







目录
4-11 节11.决策树原理
属于有监督算法
既可以做分类也可以做回归(分类用样本到叶子节点众数代表的类别表示--其中用到熵值;回归用样本到叶子节点平均数表示--用到方差计算节点划分好坏)
数据可离散也可连续
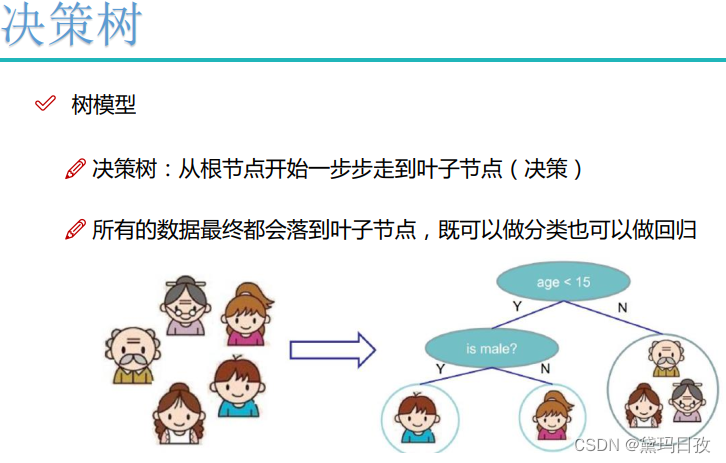
节点判断的先后顺序有严格的限制。
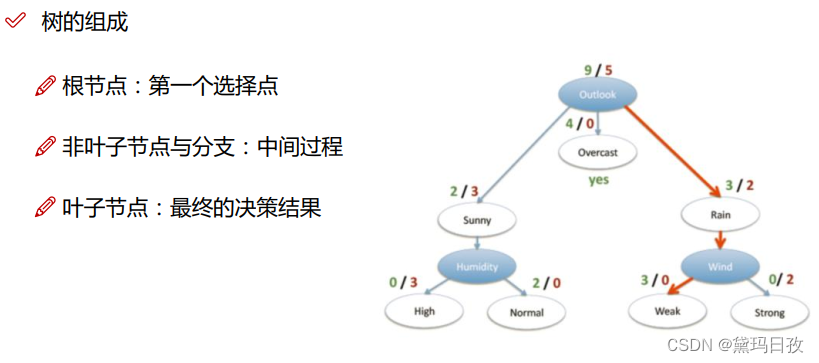


熵越来越小,不确定性越来越小。

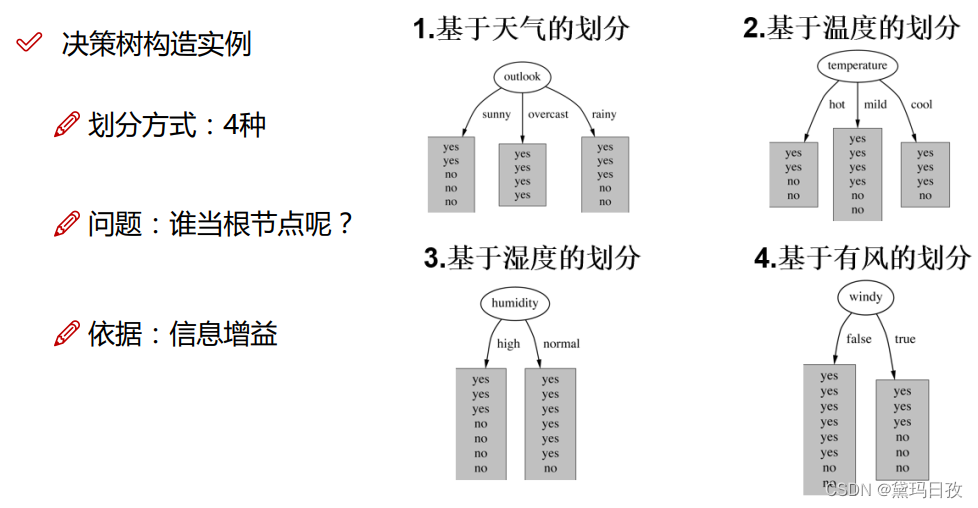
信息增益。第一个节点根节点选择信息增益最大的,以此类推。
信息增益=系统原始熵值-采用特征X分类后的熵值
信息增益率=(系统原始熵值-采用特征X分类后的熵值)/ 特征X自身熵值
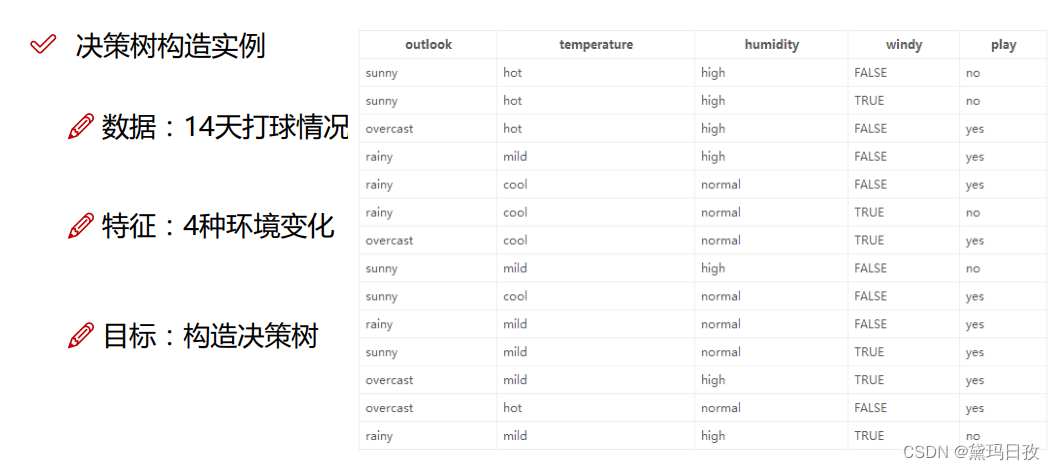
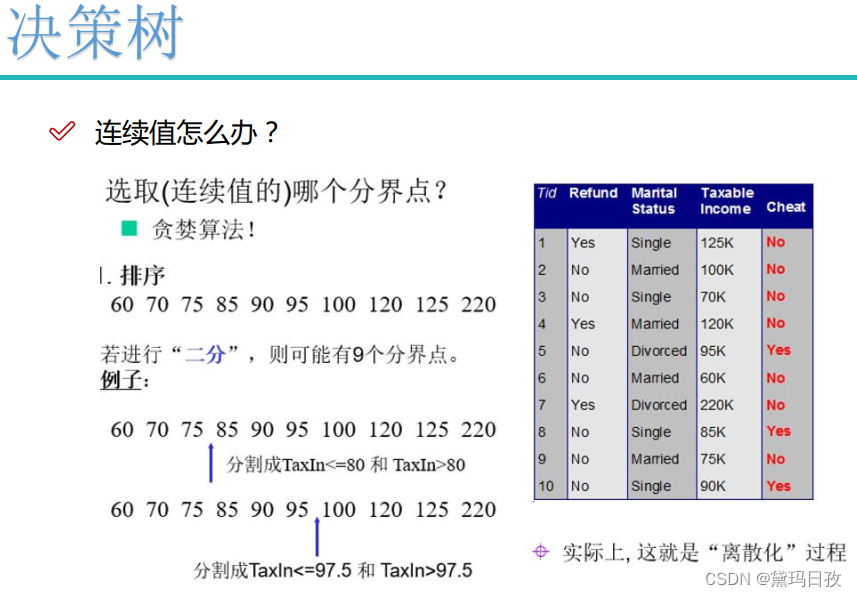
举例:



C4.5解决ID3z中没有考虑自身熵的问题

CART为二叉树,包括很多回归任务也是用二叉树表示。

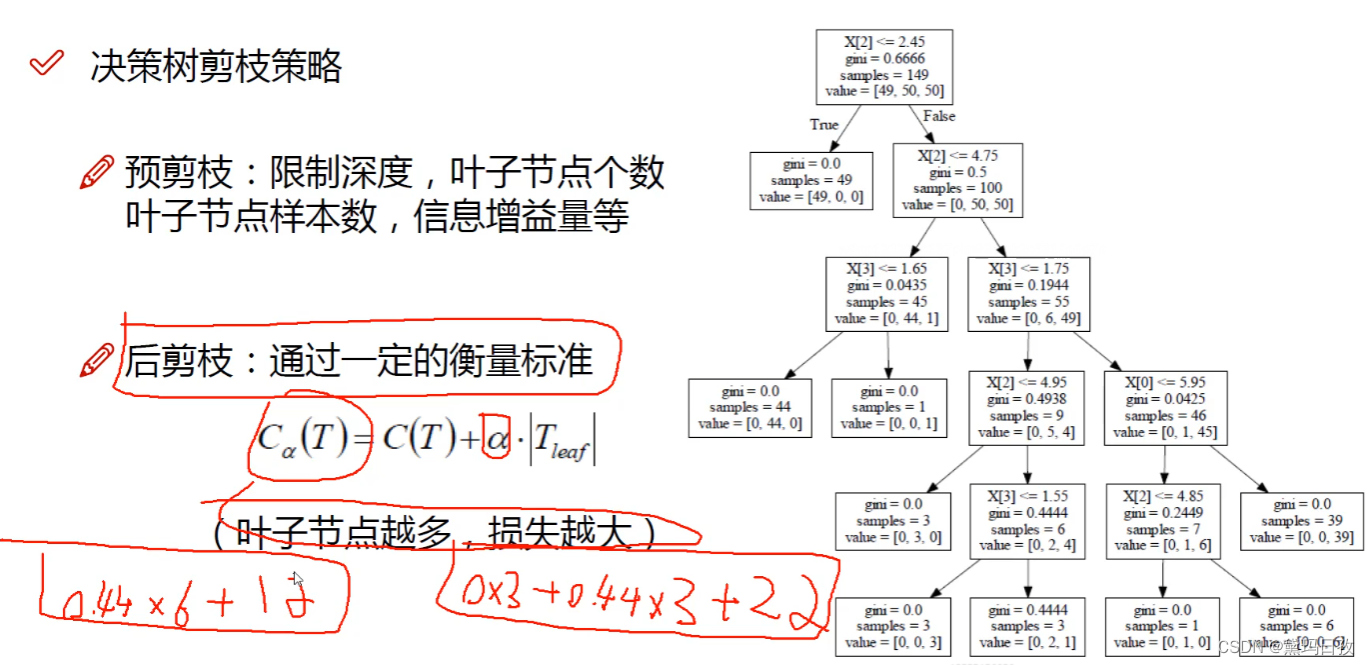
后剪枝用的比较少。下面公式用最下方左边两个叶子节点和其父节点举例说明。
4-12 节12.决策树代码实现
DecisionTree.py
# -*- coding: UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
from math import log
import operator
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['F1-AGE', 'F2-WORK', 'F3-HOME', 'F4-LOAN']
return dataSet, labels
def createTree(dataset,labels,featLabels):
classList = [example[-1] for example in dataset]
if classList.count(classList[0]) == len(classList): #classList.count(classList[0])表示classList中值为classList[0]的个数。
return classList[0]
#ss = majorityCnt(classList)#ss = 'yes'
if len(dataset[0]) == 1: #特征已经遍历完,只剩下随后一列标签。
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataset)
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}}
del labels[bestFeat]
featValue = [example[bestFeat] for example in dataset]
uniqueVals = set(featValue)
for value in uniqueVals:
sublabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataset,bestFeat,value),sublabels,featLabels)
return myTree
def majorityCnt(classList):
classCount={} #当classCount={'no': 6, 'yes': 9}
for vote in  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1596
1596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









