







分类与检测训练需要注意的点
分类模型数据集搜集
- 最好是下载线上的封面数据,这些数据随机性比较强;
- 最开始是下的视频–> 后来换成了封面数据
- 可以先用几百张小的数据集训练一个小模型专门做清洗用,但是数据清洗完后要质检;
- 因为没有质检,发现还是清洗的不干净,峡谷里面很多死亡、赛事模式等图片,导致分类器效果一直不佳
- 在数据搜集完准备训练时,可以将数据集的10%提前保存,做训练完后的测试集使用;
- 上一版本的测试集和训练集混合使用了,导致这一次要重新整理测试集,增多了工作量
- 测试集对整体模型的结果评估影响很大,如果有问题会直接影响结果,要确保测试集没有问题再测试;
- 测试集没有质检,里面有些类别标签是错误的,例如有的是失败,但是标签为成功
- 测试时,尽量不要全用一个视频来测,要覆盖全面,否则测试结果不具有代表性;
- 云顶类别的测试集是一个视频,云顶模式比较多,用一个视频不能体现整体效果
- 训练之前可以将 1920 * 1080 的大图进行批量缩放成 227*227 的小图,但是原图需要保存备份;
- 因为原图没有备份,导致在测试sdk的时候又要重新整理,因为sdk输入统一是1920*1080大小的
检测模型数据集搜集
- 将数据集的10%提前保存,做训练完后的测试集使用,测试模型的效果;
- 训练集分来自两个部分:1. 线上下载的封面截图给打标组打标(约1w张)、2. 自己造一批数据(通过脚本贴图);
- 训练数据准备好后,要抽样质检,确保标签的正确性;
模型训练
分类模型训练
- 分类模型训练的时候把每个类别都单独建一个文件夹存放数据集,不要都放到一起,质检的时候不方便
- 之前都是放到一个文件夹中,所以质检起来只能根据文件名来看,不方便
- 分类训练时,最好把标签都打乱,因为神经网络的拟合能力太强了,如果不乱序的话,同一个组合的batch反复出现,模型有可能会“记住”这些样本的次序,从而影响泛化能力。
- 之前训练的标签没有打乱,训练时一个batchsize里面的图片都是同一个类别的
# shell命令shuf标签
shuf train.txt > train_.txt
shuf val.txt > val_.txt
检测模型训练
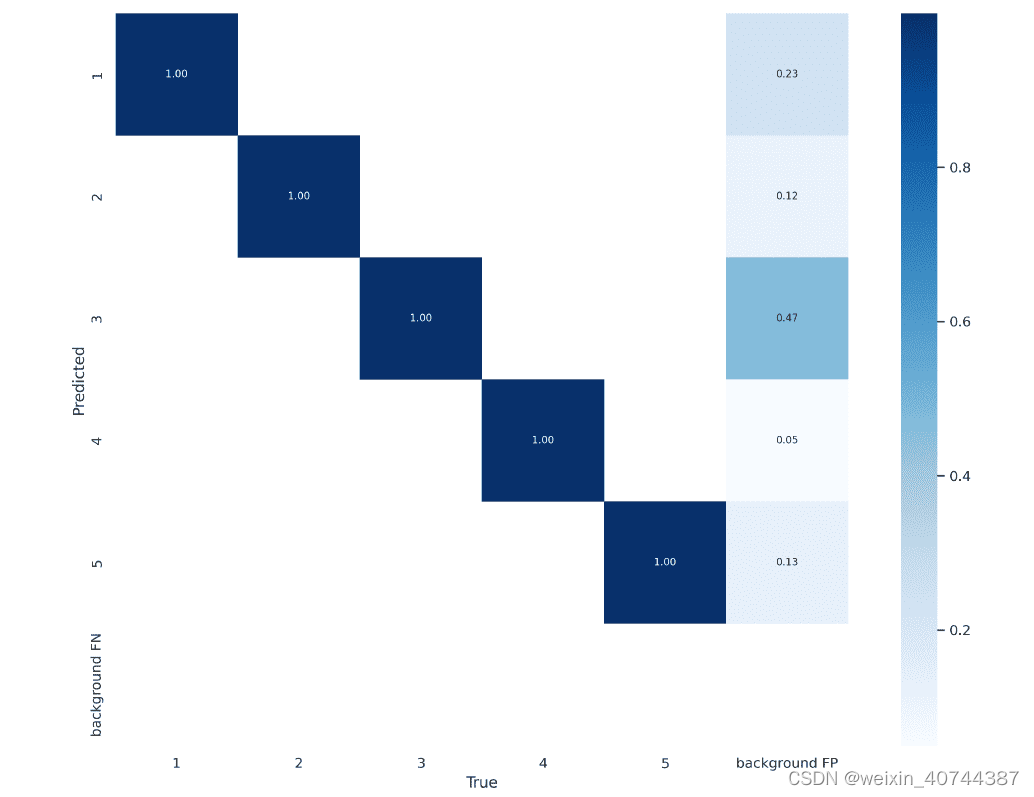
- train.py 训练模型,detect.py测试模型效果,val.py统计模型的准确率和召回率,使用val.py统计模型效果时,需要把测试集的标签处理成与验证集标签相同的模式,才能测出效果(需要把.xml标签文件处理成.txt文件格式);
- 检测模型训练完了后,可以通过python端用detect.py脚本来测试大批量的数据集,只保存有识别结果的即可,可以快速统计模型的准确率;
效果测试
召回率统计
- 召回率效果测试统计,验证集和测试集都要统计,先测试验证集是否满足效果,后测测试集;
- 之前没有测试验证集,直接在测试集上测试的;
- 把误识别的类别保存下来看看,看看是模型效果不好还是测试集标签打错,这个对测试效果影响很大;
- 模型效果不好的时候没有及时检测数据,以为数据都是正确的,导致训练了很多次模型效果都不是很好;
- 需要先把baseline的结果统计出来,然后再在测试集上与自己的模型进行对比,计算每个类别的召回提升了或者下降了多少;
- 单个模块的召回测完后,再把全流程的召回率测一下,以确保每个功能都能正常运行;
准确率统计
- 准备大批量的数据测试准确率,比较baseline与自己的模型在大批量数据上的误推率;
- 如果推出图片较多,可以采用随机抽样的方法来统计准确率,需要保证随机;
- 通过调整阈值提升准确率的同时,召回率也要重新再测一下,确保召回没有降低;
- 准确率很低的情况下先与baseline进行对比,结合误推率一起看效果;
性能测试
进程数据量统计
- 启1个handle,进程数据量为1000,那么启4个handle的时候,单进程数据量为250,总进程量为1000;
- 之前我的测试方式是 启1个handle,进程数据量为1000,那么启4个handle的时候,进程数据量为4000,测试方式最好与上一版本的测试方式保持一致;

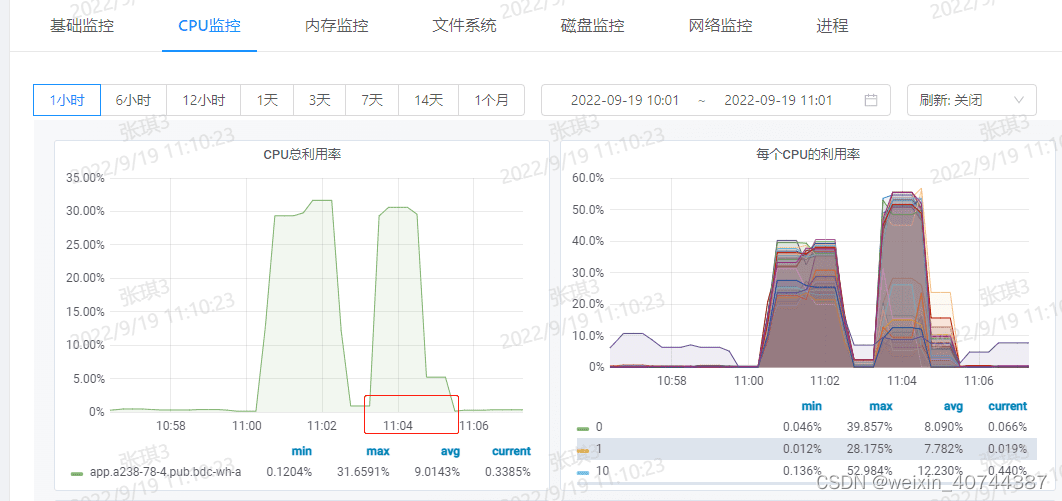
CPU消耗计算
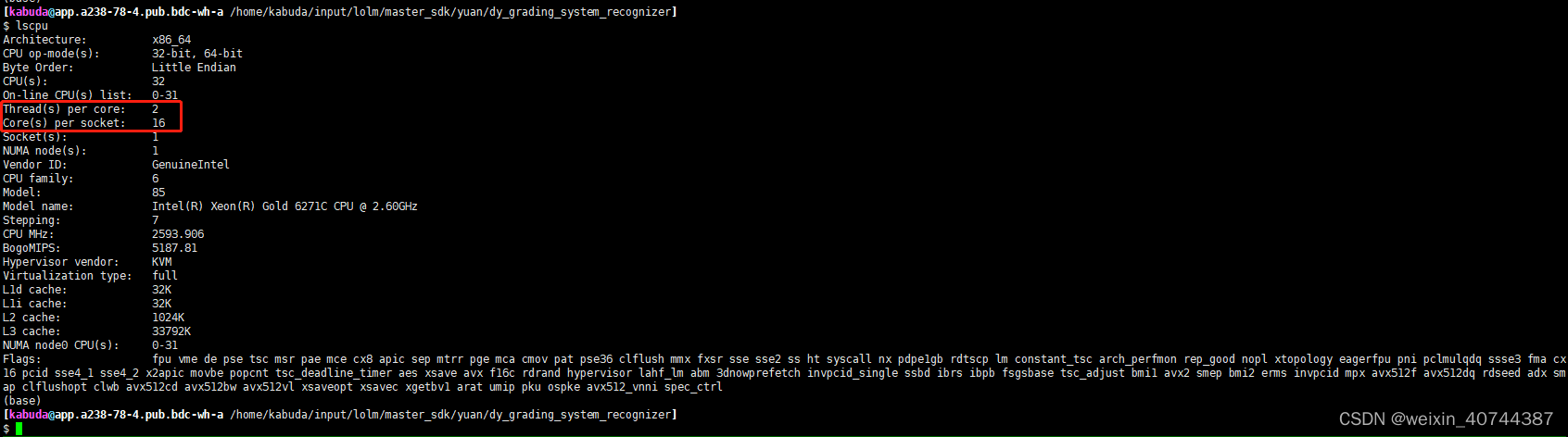
- cpu核数 = Core(s) per socket * Thread(s) per core,通过lscpu命令可以查看
- cpu消耗通过性能基础监控来计算,cpu消耗 = cpu利用率 * cpu总核数
内存消耗计算
- 单个模型在不同的机器上,消耗的内存基本一致
- 内存消耗计算方法:KiB Mem total * %MEM
- 之前我是直接看used栏消耗的内存,但是这里消耗的内存是表示所有进程消耗的,不指我的进程;
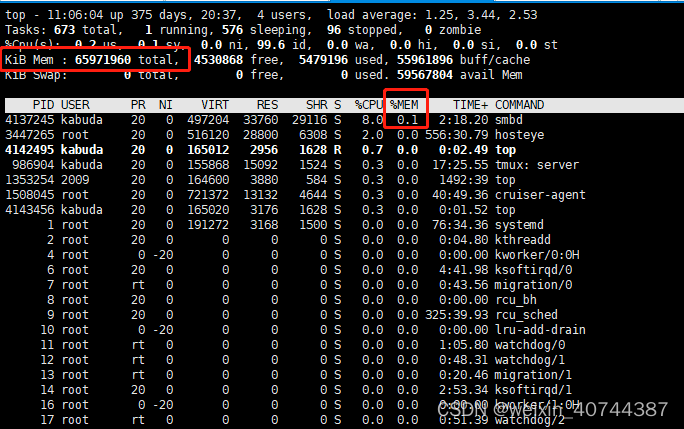
- 之前我是直接看used栏消耗的内存,但是这里消耗的内存是表示所有进程消耗的,不指我的进程;
QPS计算
- QPS:(Queries Per Second)每秒执行的查询总数(每秒有多少的请求响应)
- QPS = 图片数量 / 处理时间
- 多线程处理时,qps在sdk内部测试时,需要记录线程启动的最早开始时间及最晚结束时间,才能确保qps的准确性
- 之前我的计算方法是在sdk内部测试平均耗时,然后再用1000ms除以平均耗时,得到qps,但是在多线程处理的时候,该方法容易出错,因为每个线程开始的时间和结束的时间不知道,不好计算多线程的时候的平均耗时;
- 之前我的计算方法是在sdk内部测试平均耗时,然后再用1000ms除以平均耗时,得到qps,但是在多线程处理的时候,该方法容易出错,因为每个线程开始的时间和结束的时间不知道,不好计算多线程的时候的平均耗时;
sdk逻辑代码
- 分类模型对输入图片进行分类
- 判断图片类别是否为8,如果类别为8就过检查模型;如果类别不为8,则返回相应结果;
- 分类类别为8的图片通过检测识别;
- 是否检测到2个或2个以上标签为1、2、3 的情况;
- 取出上面情况的排名最前的2个图标的结果;
- 取出这2个图标结果的坐标,判断这2个结果的x点坐标距离是否大于1400;y点坐标距离是否小于100;
- 满足上一条件,判断2个图标的宽高是否都小于100;
- 结果返回;
检测结果排序
获得检测模型检测到的结果,同一个标签结果置信度从大到小进行排序;
bool compard(const YoloOutput &input_x, const YoloOutput &input_y)
{
return input_x.confidence > input_y.confidence;
}
std::vector<YoloOutput> det_outs;
Detect(src, det_outs);
sort(det_outs.begin(), det_outs.end(), compard);
申请临时空间
获得检测模型的类别个数,申请一个大小为类别个数的临时空间save_rect_resule,用来存放需要进行逻辑判断的结果;
size_t GetClaaName(){
return class_names_.size() ;
}
int detect_nums = ptr_detect_net_->GetClaaName();
std::vector<std::vector<GameBoardRect>> save_rect_resule(detect_nums);
Size_t主要用来计数,如sizeof得到的类型即为size_t。
在32位架构中被普遍定义为: typedef unsigned int size_t; (4个字节)
而在64位架构中被定义为: typedef unsigned long size_t;(8个字节)
Size_t 是无符号数;int 则无论在32位还是64位架构中,都是4个字节,带符号数。
遍历检测结果,将置信度大于阈值的结果存储到临时空间save_rect_resule中;
if (det_outs[i].confidence > 0.8)
{
class_num = det_outs[i].id;
GameBoardRect det_res_blood; //云顶之弈的图标位置保存
det_res_blood.x = det_outs[i].box.x;
det_res_blood.y = det_outs[i].box.y;
det_res_blood.w = det_outs[i].box.width;
det_res_blood.h = det_outs[i].box.height;
// bboxes_det.push_back(det_res_blood);
save_rect_resule[class_num].push_back(det_res_blood);
}
主逻辑判断
sdk逻辑判断,检测的标签为1、2、3且检测到的个数为2时;
if(class_num > 0 && class_num < 4 && save_rect_resule[class_num].size() == 2)
{
int res_x = abs(save_rect_resule[class_num][0].x - save_rect_resule[class_num][1].x);
int res_y = abs(save_rect_resule[class_num][0].y - save_rect_resule[class_num][1].y);
int res_w1 = save_rect_resule[class_num][0].w;
int res_h1 = save_rect_resule[class_num][0].h;
int res_w2 = save_rect_resule[class_num][1].w;
int res_h2 = save_rect_resule[class_num][1].h;
if(res_x > (int)((src.cols/1920.0)*1400) && res_y<(int)((src.cols/1080.0)*100) &&
res_w1<(int)((src.cols/1920.0)*100) && res_h1<(int)((src.cols/1080.0)*100) &&
res_w2 <(int)((src.cols/1920.0)*100) && res_h2 < (int)((src.cols/1080.0)*100) )
{
return class_num;
}
}














 4304
4304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









