







RepVGG模型介绍
RepVGG: Making VGG-style ConvNets Great Again 论文地址:https://arxiv.org/abs/2101.03697
- RepVGG在VGG的基础上进行改进,主要的思路包括:
- 在VGG网络的Block块中加入Identity和残差分支,相当于把ResNet网络中的精华应用了到VGG网络中;
- 模型推理阶段,通过Op融合策略将所有的网络层都转换为Conv3*3,便于网络的部署和加速
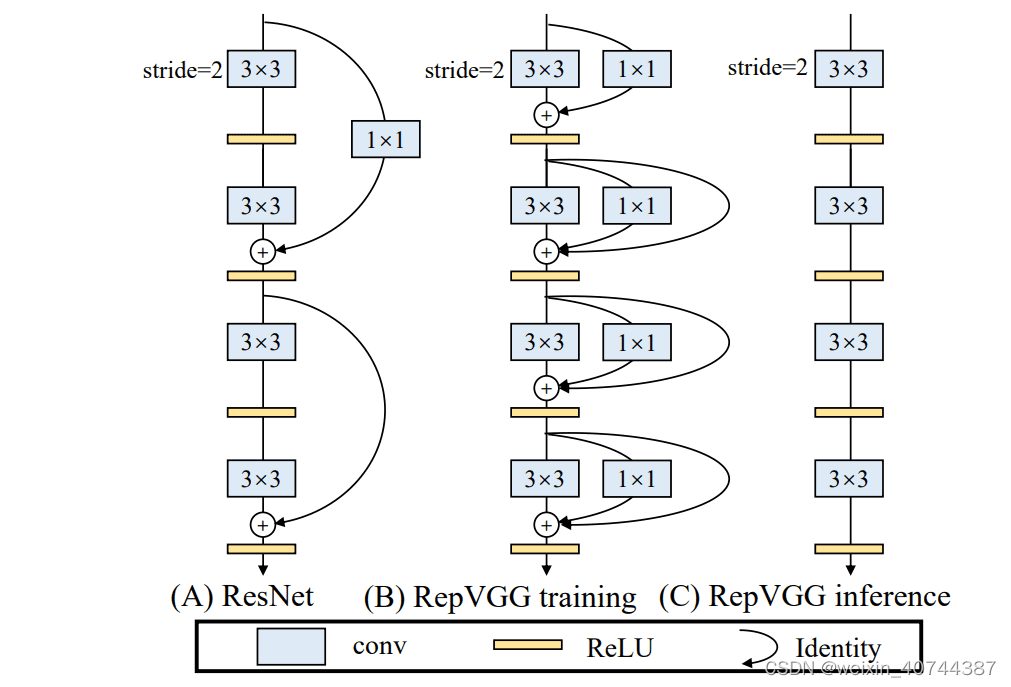
- RepVGG的网络结构设计:
- 图(A)中包含着Conv1*1的残差结构和Identity的残差结构,这些残差结构的存在解决了深层网路中的梯度消失问题,使得网络更加易于收敛;
- 图(B)是训练阶段的RepVGG网络架构,整个网络的主体结构和ResNet网络类似,两个网络中都包含残差结构。
- 网络中的残差块并没有跨层;
- 整个网络包含2种残差结构;
- 模型的初始阶段使用了简单的残差结构,随着模型的加深,使用了复杂的残差结构,这样不仅仅能够在网络的深层获得更鲁邦的特征表示,而且可以更好的处理网络深层的梯度消失问题;
- 图(C)是推理阶段的RepVGG网络,该网络的结构非常简单,整个网络均是由Conv3*3+Relu堆叠而成,易于模型的推理和加速
残差结构具有多个分支,相当于给网络增加了多条梯度流动的路径,训练一个这样的网络,其实类似于训练了多个网络,并将多个网络融合在一个网络中,类似于模型集成的思路,不过这种思路更加简单和高效;
-
RepVGG架构的主要优势:
- 当前大多数推理引擎都对Conv33做了特定的加速,假如整个网络中的每一个Conv33都能节省3ms,如果一个网络中包含30个卷积层,那么整个网络就可以节省3*30=90ms的时间;
- 当推理阶段使用的网络层类别比较少时,是一种较好的模型加速方案,模型推理阶段的网络结构越简单越能起到模型加速的效果;
- 推理阶段首先在线下将模型转换为单分支结构,在设备推理阶段能更好的提升设备的内存利用率,从而提升模型的推理速度;
-
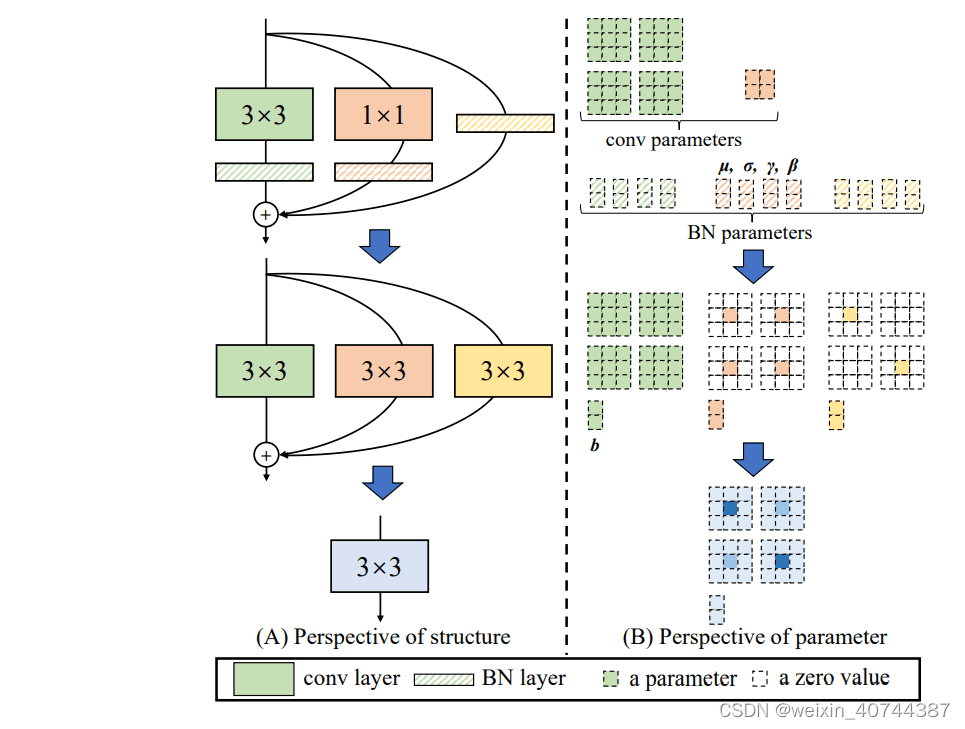
推理阶段Op融合细节详解
- 首先将残差块中的卷积层和BN层进行融合;
- 将融合后的卷积层转换为Conv3*3;
- 合并残差分支中的Conv3*3
-
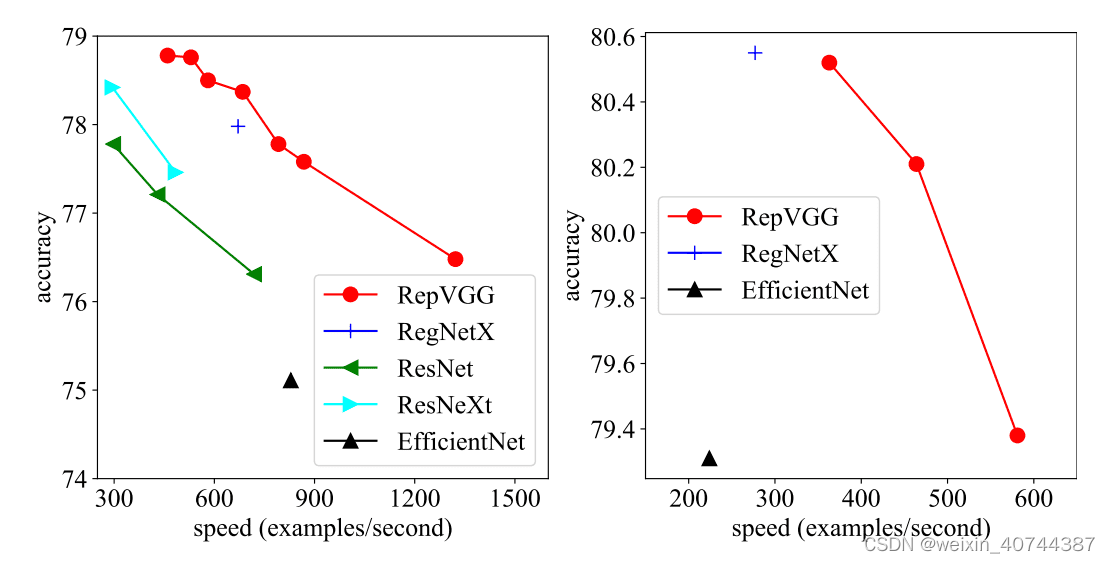
RepVGG性能评估:
- 相同测试条件下,最小的模型RepVGG-A0与ResNet-18相比,各项指标都有显著的提升,RepVGG-A0网络不仅具有更少的参数量,更快的推理速度,而且获得了更高的分类精度;
- 与EfficientNet-B0相比,RepVGG-B1g4不仅具有更快的执行速度,而且获得了更高的分类精度,当然该模型也更大一些;
- 与VGG-16网络相比,RepVGG-B2在各个指标上面都有一定的性能提升
RepVGG模型训练
训练代码:/common/zhangqi3/games_class/dy_games_recognition-repVGG_code-repVGG_traincode.zip (jupyter的common目录)
参考:github:https://github.com/Fafa-DL/Awesome-Backbones
参考:https://github.com/DingXiaoH/RepVGG
环境配置
- 安装pytorch==1.2.0以上版本
- 开源数据集:data/flower_photos_20190815(2个类别)
- 组内测试数据集:/common/zhangqi3/games_class/zhijian_trainset(125个类别)
1. 制作数据集及标签:
1.1 训练数据标签制作:
在/datas/中创建标签文件annotations.txt,按行将类别名索引写入文件;

1.2 数据集划分:
python ./tool/split_data.py (python文件见附件),得到划分后的数据集格式如下:

1.3 数据集信息文件制作
修改划分数据集的脚本中 init_dataset 为训练集的地址,new_dataset 为修改后保存的目录;
def main():
'''
split_rate : 测试集划分比例
init_dataset: 未划分前的数据集路径
new_dataset : 划分后的数据集路径
'''
def makedir(path):
if os.path.exists(path):
rmtree(path)
os.makedirs(path)
split_rate = 0.2
init_dataset = 'data/flower_photos_20190815' #修改为 训练集的目录
new_dataset = 'datasets2' #修改为 split后保存的地址
random.seed(0)

pip install terminaltables -i https://pypi.douban.com/simple/ 在Anaconda环境里安装terminaltables

python ./tool/get_annotation.py 到生成的数据集信息文件train.txt与val.txt (python文件见附件)
def main():
classes_path = 'data/annotations.txt'
datasets_path = 'datasets2' # 修改为 划分数据集后的目录地址
datasets = ["train", "val"]
classes, indexs = get_info(classes_path)
for dataset in datasets:
txt_file = open('datasets2/' + dataset + '.txt', 'w') # 修改为 划分数据集后的目录地址
datasets_path_ = os.path.join(datasets_path, dataset)
classes_name = os.listdir(datasets_path_)
2. 模型训练:
2.1 修改参数文件
- 在src/main_train中修改num_classes为自己数据集类别大小
try:
#4.5 get files and split for K-fold dataset
#4.5.1 read files
#num_classes, train_data_list, val_data_list = get_files(args.input_path,"trainval")
num_classes = 2 # 修改为 自己数据集类别的大小
train_data_list = get_files_my(args.input_path, os.path.join(args.input_path, "train.txt"), num_classes)
val_data_list = get_files_my(args.input_path, os.path.join(args.input_path, "val.txt"), num_classes)
#4.2 get model and optimizer
model = get_net(args.network, num_classes)
- 按照自己电脑性能在config/default.json中修改batch_size
- 修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小
- 确认/datas/下train.txt与test.txt与annotations.txt对应
模型训练 bash run_main_train_repvgg.sh (shell文件见附件)
src_path='src/'
input_path='datasets2/' # 划分后的数据集路径
weights_file='./sv_train_0928/model/repvgg_a0_best.pth' # 训练后的模型保存路径
weights_path='model/torch_model_zoo/'
network='repvgg_a0'
output_path_train='sv_train_0928' # 训练后的模型保存路径

2.2 pth转pt
python src/main_convert.py -w ./sv_train_0928/model/repvgg_a0_best.pth -c 2
2.3 val:验证
模型验证 python src/main_predic.py (python文件见附件)

3. 批量数据测试(组内125个类别测试集):
- 整理10w+张测试集合,将测试集合划分为多个相同大小的txt文件,作为模型的输入,将上一步转换后的模型进行效果测试:
python src/predict_repvgg.py -w ./save_pt_pth_file/repvgg_a0_cpp_deploy_zq.pt --save ./save_npy_file/
- 测试结果转换
将上一步保存的npy测试结果进行转换,得到每个类别的测试效果:
python src/predict_repvgg.py -w ./save_pt_pth_file/repvgg_a0_cpp_deploy_zq.pt --save ./save_npy_file/
RepVGG性能评估
- baseline:SqueezeNet,平均单张耗时在40~60ms左右
- repVGG模型测试性能结果统计:平均单张耗时在17~30ms左右,相比bashline有明显的提升;
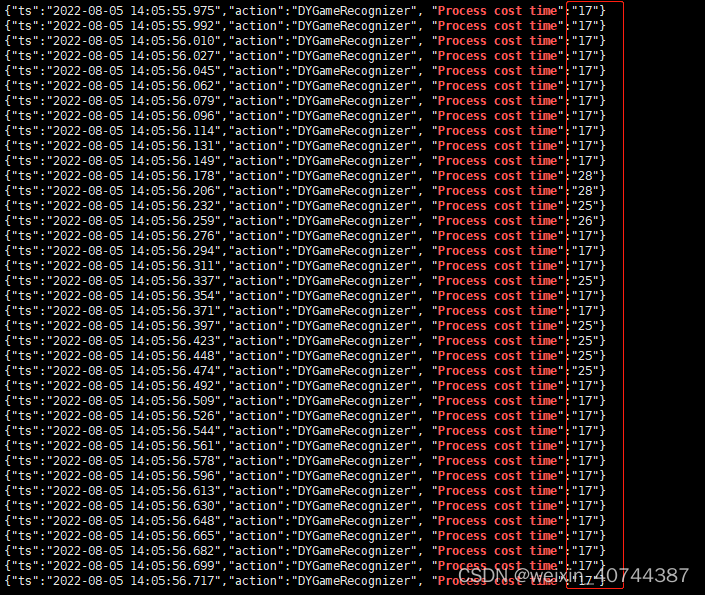
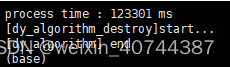
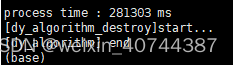
- 在4.5k的无标签测试集上的性能效果统计,repvgg模型总耗时12w毫秒,baseline模型总耗时28w毫秒,性能提升约57%;
vrepVGG耗时(上)
bashline耗时(下)














 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









