







HRNET分割模型训练
1. 制作数据集及标签:
1.1 合成数据:
python create_game_board_dataset.py img_merge/1.txt img_merge/2.txt img_merge/3/ img_merge/4/ ./out/
生成了图片数据和labelme格式的json标注数据
####create_game_board_dataset.py
"""
@Brief: 游戏边框数据集自动生成: 贴背景图, 主播左右下角小窗贴图, 主播左右侧拼图
"""
import os
import sys
import glob
import json
import cv2
from PIL import Image
import random
from multiprocessing import Process
NUM_PROCESS = 4
GAME_TYPE = "wzry"
#游戏画面直接贴到背景图片上
def img_tie_beijing(ori_img_file, other_img_file, out_dir, out_file_name):
ori_img = cv2.imread(ori_img_file)
ori_h, ori_w = ori_img.shape[:2]
h_resize = ori_h - random.randint(0,int(ori_h/5))
w_resize = ori_w - random.randint(0,int(ori_w/3))
ori_img = cv2.resize(ori_img, (w_resize, h_resize))
#oo_file = random.choice(other_img_list)
other_img = cv2.imread(other_img_file)
other_img = cv2.resize(other_img, (ori_w, ori_h))
img1_pil = Image.fromarray(cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB))
img2_pil = Image.fromarray(cv2.cvtColor(other_img, cv2.COLOR_BGR2RGB))
paste_x = random.randint(0, ori_w - w_resize)
paste_y = random.randint(0, ori_h - h_resize)
img2_pil.paste(img1_pil, (paste_x, paste_y))
#贴图图片保存
out_img_path = os.path.join(out_dir, out_file_name+".jpg")
img2_pil.save(out_img_path)
#labelme格式的json标注数据
img_name = out_file_name+".jpg"
shapes = [{"label": GAME_TYPE, "points":[[paste_x, paste_y],[paste_x+w_resize, paste_y+h_resize]],"group_id":None, "shape_type":"rectangle","flags":{}}]
out_dict = {"version": "4.5.5", "imageHeight": ori_h, "imageWidth": ori_w, "imagePath": os.path.basename(out_img_path), "flags": {}, "shapes": shapes, "imageData": None}
out_label_file = os.path.join(out_dir, out_file_name+".json")
with open(out_label_file, 'w') as fd:
json.dump(out_dict, fd)
#合成带有主播小窗的游戏边框数据
def img_tie_zhubo_xiaochuang(ori_img_file, other_img_file, zhubo_horiz_img_file, out_dir, out_file_name):
ori_img = cv2.imread(ori_img_file)
ori_h, ori_w = ori_img.shape[:2]
h_resize = ori_h - random.randint(0,int(ori_h/5))
w_resize = ori_w - random.randint(0,int(ori_w/3))
ori_img = cv2.resize(ori_img, (w_resize, h_resize))
other_img = cv2.imread(other_img_file)
other_img = cv2.resize(other_img, (ori_w, ori_h))
img1_pil = Image.fromarray(cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB))
img2_pil = Image.fromarray(cv2.cvtColor(other_img, cv2.COLOR_BGR2RGB))
paste_x = random.randint(0, ori_w - w_resize)
paste_y = random.randint(0, ori_h - h_resize)
#贴背景图
img2_pil.paste(img1_pil, (paste_x, paste_y))
#贴主播小窗
zhubo_img = cv2.imread(zhubo_horiz_img_file)
zhubo_res_w = random.randint(int(w_resize/10),int(w_resize/5))
zhubo_res_h = random.randint(int(h_resize/8),int(h_resize/4))
zhubo_img = cv2.resize(zhubo_img, (zhubo_res_w, zhubo_res_h))
zhubo_paste_x1 = random.randint(paste_x, paste_x + w_resize-zhubo_res_w)
zhubo_paste_x = random.choice([paste_x, zhubo_paste_x1, paste_x + w_resize-zhubo_res_w])
zhubo_paste_y = paste_y + h_resize - zhubo_res_h
zhubo_pil = Image.fromarray(cv2.cvtColor(zhubo_img, cv2.COLOR_BGR2RGB))
img2_pil.paste(zhubo_pil, (zhubo_paste_x, zhubo_paste_y))
if zhubo_paste_x > paste_x and zhubo_paste_x < (paste_x + w_resize-zhubo_res_w):
point_list = [[paste_x, paste_y], [paste_x, paste_y+h_resize], [zhubo_paste_x, paste_y+h_resize], [zhubo_paste_x, paste_y+h_resize-zhubo_res_h],
[zhubo_paste_x+zhubo_res_w, paste_y+h_resize-zhubo_res_h], [zhubo_paste_x+zhubo_res_w, paste_y+h_resize],
[paste_x+w_resize, paste_y+h_resize], [paste_x+w_resize, paste_y]]
elif zhubo_paste_x == paste_x:
point_list = [[paste_x, paste_y], [paste_x, paste_y+h_resize-zhubo_res_h], [paste_x+zhubo_res_w, paste_y+h_resize-zhubo_res_h],
[paste_x+zhubo_res_w, paste_y+h_resize], [paste_x+w_resize, paste_y+h_resize], [paste_x+w_resize, paste_y]]
elif zhubo_paste_x == (paste_x + w_resize-zhubo_res_w):
point_list = [[paste_x, paste_y], [paste_x, paste_y+h_resize], [zhubo_paste_x, paste_y+h_resize], [zhubo_paste_x, paste_y+h_resize-zhubo_res_h],
[paste_x+w_resize, paste_y+h_resize-zhubo_res_h], [paste_x+w_resize, paste_y]]
#贴图图片保存
out_img_path = os.path.join(out_dir, out_file_name+".jpg")
img2_pil.save(out_img_path)
#labelme格式的json标注数据
img_name = out_file_name+".jpg"
shapes = [{"label": GAME_TYPE, "points":point_list, "group_id":None, "shape_type":"polygon","flags":{}}]
out_dict = {"version": "4.5.5", "imageHeight": ori_h, "imageWidth": ori_w, "imagePath": os.path.basename(out_img_path), "flags": {}, "shapes": shapes, "imageData": None}
out_label_file = os.path.join(out_dir, out_file_name+".json")
with open(out_label_file, 'w') as fd:
json.dump(out_dict, fd)
#左右拼接主播小窗
def img_pinjie_zhubo(ori_img_file, other_img_file, zhubo_vert_img_file, out_dir, out_file_name):
ori_img = cv2.imread(ori_img_file)
ori_h, ori_w = ori_img.shape[:2]
h_resize = ori_h - random.randint(0,int(ori_h/5))
w_resize = ori_w - random.randint(int(ori_w/6), int(ori_w/3))
ori_img = cv2.resize(ori_img, (w_resize, h_resize))
other_img = cv2.imread(other_img_file)
other_img = cv2.resize(other_img, (ori_w, ori_h))
img1_pil = Image.fromarray(cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB))
img2_pil = Image.fromarray(cv2.cvtColor(other_img, cv2.COLOR_BGR2RGB))
paste_x1 = random.randint(0, int((ori_w - w_resize) / 8))
paste_x2 = random.randint(int((ori_w - w_resize) - ((ori_w - w_resize) / 8)), int(ori_w - w_resize))
paste_x = random.choice([paste_x1, paste_x2])
paste_y = random.randint(0, ori_h - h_resize)
#贴背景图
img2_pil.paste(img1_pil, (paste_x, paste_y))
#拼接主播小窗
zhubo_img = cv2.imread(zhubo_vert_img_file)
zhubo_img_h, zhubo_img_w = zhubo_img.shape[:2]
if (ori_w -(paste_x+w_resize)) > paste_x:
zhubo_paste_x = paste_x+w_resize
zhubo_res_w = ori_w - (paste_x+w_resize)
else:
zhubo_paste_x = 0
zhubo_res_w = paste_x
res_h = int((zhubo_res_w/zhubo_img_w) * zhubo_img_h)
if res_h < ori_h:
zhubo_res_h = random.randint(res_h, ori_h)
else:
zhubo_res_h = ori_h
zhubo_paste_y = random.randint(0, ori_h - zhubo_res_h)
zhubo_img = cv2.resize(zhubo_img, (zhubo_res_w, zhubo_res_h))
zhubo_pil = Image.fromarray(cv2.cvtColor(zhubo_img, cv2.COLOR_BGR2RGB))
img2_pil.paste(zhubo_pil, (zhubo_paste_x, zhubo_paste_y))
#贴图图片保存
out_img_path = os.path.join(out_dir, out_file_name+".jpg")
img2_pil.save(out_img_path)
#labelme格式的json标注数据
shapes = [{"label": GAME_TYPE, "points":[[paste_x, paste_y],[paste_x+w_resize, paste_y+h_resize]],"group_id":None, "shape_type":"rectangle","flags":{}}]
out_dict = {"version": "4.5.5", "imageHeight": ori_h, "imageWidth": ori_w, "imagePath": os.path.basename(out_img_path), "flags": {}, "shapes": shapes, "imageData": None}
out_label_file = os.path.join(out_dir, out_file_name+".json")
with open(out_label_file, 'w') as fd:
json.dump(out_dict, fd)
def img_tietu_aug(ori_img_list, other_img_list, zhubo_horiz_img_list, zhubo_vert_img_list, out_dir, pro_idx=0):
for img_file in ori_img_list:
other_img_file = random.choice(other_img_list)
ori_img_name = os.path.basename(img_file).split(".")[0]
#随机选择一种生成图片方式
select_idx = random.randint(0, 2)
if select_idx == 0:
out_file_name = "paste_beijing_{}_{}".format(GAME_TYPE, ori_img_name)
img_tie_beijing(img_file, other_img_file, out_dir, out_file_name)
elif select_idx == 1:
out_file_name = "paste_zhubo_xiaochuang_{}_{}".format(GAME_TYPE, ori_img_name)
zhubo_horiz_img_file = random.choice(zhubo_horiz_img_list)
img_tie_zhubo_xiaochuang(img_file, other_img_file, zhubo_horiz_img_file, out_dir, out_file_name)
elif select_idx == 2:
out_file_name = "paste_pinjie_zhubo_{}_{}".format(GAME_TYPE, ori_img_name)
zhubo_vert_img_file = random.choice(zhubo_vert_img_list)
img_pinjie_zhubo(img_file, other_img_file, zhubo_vert_img_file, out_dir, out_file_name)
if __name__ == "__main__":
#原始的游戏图片数据(无边框)
ori_img_file = sys.argv[1]
#背景图片数据
other_img_file = sys.argv[2]
#主播横屏图片数据
zhubo_horiz_dir = sys.argv[3]
#主播竖屏图片数据
zhubo_vert_dir = sys.argv[4]
#生成数据目录
out_dir = sys.argv[5]
ori_img_list = []
other_img_list = []
with open(ori_img_file, "r") as fd:
for line in fd:
ori_img_list.append(line.strip())
with open(other_img_file, "r") as fd:
for line in fd:
other_img_list.append(line.strip())
zhubo_horiz_img_list = glob.glob(zhubo_horiz_dir+"/*.jpg")
zhubo_vert_img_list = glob.glob(zhubo_vert_dir+"/*.jpg")
print("ori_img_list: {}, other_img_list: {}, zhubo_horiz_img_list: {}, zhubo_vert_img_list: {}".format(len(ori_img_list), len(other_img_list), len(zhubo_horiz_img_list), len(zhubo_vert_img_list)))
#多进程发送请求
total_img_num = len(ori_img_list)
num_per_process = int(total_img_num/ NUM_PROCESS)
if total_img_num % NUM_PROCESS:
num_per_process += 1
process_pool = []
for g in range(NUM_PROCESS):
start_idx = g * num_per_process
end_idx = start_idx + num_per_process
print("start_idx: {}, end_idx: {}".format(start_idx, end_idx))
if g == (NUM_PROCESS-1):
end_idx = total_img_num
p = Process(target = img_tietu_aug, args = (ori_img_list[start_idx:end_idx], other_img_list, zhubo_horiz_img_list, zhubo_vert_img_list, out_dir, g))
p.start()
process_pool.append(p)
for p in process_pool:
p.join()
1.2 自制数据集:
参考:
- https://blog.csdn.net/gaoyi135/article/details/103870646(【labelme】批量将.json文件转换成mask.png等文件)
- https://blog.csdn.net/weixin_45609455/article/details/106334688(自制多分类cityscapes格式数据集用于HRNet网络进行语义分割)
1.2.1 数据集的标注环境
用labelme 标注数据
conda create -n labelme python=3.6
source activate labelme
conda install pyqt
pip install labelme
1.2.2 json文件的转换
修改labelme环境中的代码文件:
conda info --envs //查看环境的地址
找到labelme环境安装位置的json_to_dataset.py文件,打开该文件,并将其中的代码替换(脚本见附件:json_to_dataset.py):
运行: labelme_json_to_dataset --out ./save_label2/ ./lol_labeldata/train/
此时生成的是用labelme打标后生成的带有颜色的mask标签
###labelme_json_to_dataset.py
import argparse
import base64
import json
import os
import os.path as osp
import glob
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
parser = argparse.ArgumentParser()
parser.add_argument("json_file")
parser.add_argument("-o", "--out", default=None) #--out是保存制作标签的大地址
args = parser.parse_args()
json_file = args.json_file #获得json文件的目录
print("the json_file is ---{}".format(json_file))
save_dir = '/mnt/dataset/LOL_/label_img1/' #将生成的label单独保存一份放到label_img1目录下
if args.out is None:
out_dir = osp.basename(json_file).replace(".", "_") #获得json文件目录的名称
print("the out_dir1 is ---{}".format(out_dir))
out_dir = osp.join(osp.dirname(json_file), out_dir) #获得json文件的目录
print("the out_dir2 is ---{}".format(out_dir))
else:
print("args.out is not None")
out_dir = args.out
# save_dir = out_dir
if not osp.exists(out_dir):
os.mkdir(out_dir)
#add by zhongzhiwei
if os.path.isdir(json_file):
json_file_list = glob.glob(json_file+"/*.json")
elif os.path.isfile(json_file) and (os.path.basename(json_file).split('.')[-1] == "json"):
json_file_list = []
json_file_list.append(json_file)
elif os.path.isfile(json_file) and (os.path.basename(json_file).split('.')[-1] == "txt"):
json_file_list = []
print("------begin read json list")
with open(json_file, 'r') as fd:
for line in fd:
json_file_list.append(line.strip())
print(json_file_list)
for json_ff in json_file_list:
print("begin process file: ", json_ff)
data = json.load(open(json_ff))
imageData = data.get("imageData")
if not imageData:
if "imagePath" not in data.keys():
print("{} imagePath is empty".format(json_ff))
continue
imagePath = os.path.join(os.path.dirname(json_ff), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
#label_name_to_value = {"_background_": 0, "wzry": 1, "hpjy": 2}
label_name_to_value = {"_background_": 0, "lol": 1, "fu": 2}
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
try:
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
except Exception as e:
print("{} except {}".format(json_ff, e))
continue
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
label=lbl, img=imgviz.asgray(img), label_names=label_names, loc="rb"
)
json_name = osp.basename(json_ff).replace(".json", "")
out_dir = osp.join(args.out, json_name)
print("the out_dir3 is ---{}".format(out_dir))
if not osp.exists(out_dir):
os.mkdir(out_dir)
utils.lblsave(osp.join(out_dir, json_name + "_label.png"), lbl)
utils.lblsave(osp.join(save_dir, json_name + "_label.png"), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir))
if __name__ == "__main__":
main()
1.2.3 从转换后的_json文件夹中获取mask图(标签的映射)
将图像里面标注的类别进行一个局部到全局的映射, 新建一个class_name存放我们的类,代码见附件:(get_png.py)
运行:python get_png.py
对应好后,在转训练的png的时候,按照制作好的标签顺序,进行mask的png的制作,运行代码get_png.py,输出图保存到png文件夹中。
###get_png.py
import os
from PIL import Image
import numpy as np
def main():
# 读取原文件夹
count = os.listdir("./before/")
for i in range(0, len(count)):
# 如果里的文件以jpg结尾
# 则寻找它对应的png
if count[i].endswith("jpg"):
path = os.path.join("./before", count[i])
img = Image.open(path)
img.save(os.path.join("./jpg", count[i]))
# 找到对应的png
path = "./output/" + count[i].split(".")[0] + "_json/label.png"
img = Image.open(path)
# 找到全局的类
class_txt = open("./before/class_name", "r")
class_name = class_txt.read().splitlines()
# ["_background_","a","b"]
# 打开json文件里面存在的类,称其为局部类
with open("./output/" + count[i].split(".")[0] + "_json/label_names.txt", "r") as f:
names = f.read().splitlines()
# ["_background_","b"]
new = Image.new("RGB", [np.shape(img)[1], np.shape(img)[0]])
# print('new:',new)
for name in names:
index_json = names.index(name)
index_all = class_name.index(name)
# 将局部类转换成为全局类
new = new + np.expand_dims(index_all * (np.array(img) == index_json), -1)
new = Image.fromarray(np.uint8(new))
print('new:',new)
new.save(os.path.join("./png", count[i].replace("jpg", "png")))
print(np.max(new), np.min(new))
if __name__ == '__main__':
main()
1.2.4 转灰度图
得到的图是24bit的图,需要将其转换为8bit的灰度图用于训练,转换代码见附件:(get_gray.py)
运行:python get_gray.py
以上训练的灰度图就算是制作成功了,然后制作好参与训练需要的文本列表(train.lst,val.lst,testval.lst,test.lst)
###get_gray.py
import cv2
import os
input_dir = './png_mergeimg' #上一步保存.png图像文件夹
out_dir = './grey'
a = os.listdir(input_dir)
for i in a:
print(i)
img = cv2.imread(input_dir+'/'+i)
if '.png' in i:
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
cv2.imencode('.png', gray)[1].tofile(out_dir+'/'+i)
2. 模型训练:
github:https://github.com/HRNet/HRNet-Semantic-Segmentation
2.1 train:训练
python tools/train.py --cfg ./seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
2.2 val:验证
python tools/test.py --cfg ./seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml TEST.MODEL_FILE ./seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484/best2.pth TEST.SCALE_LIST 0.5,0.75,1.0,1.25,1.5,1.75 TEST.FLIP_TEST True
2.3 test:测试
python tools/test.py --cfg experiments/lol_dataset/seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml DATASET.TEST_SET list/lol_dataset/test.lst TEST.MODEL_FILE output/douyu/seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484/best2.pth TEST.SCALE_LIST 0.5,0.75,1.0,1.25,1.5,1.75 TEST.FLIP_TEST True
3. 模型转换:
yaml文件:见附件 ( seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml)
python model_convert.py --cfg …/experiments/lol_dataset/seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484.yaml
"""
model_convert.py @Brief: 模型转换为pt文件, 用于模型的部署
"""
import argparse
import os
import pprint
import shutil
import sys
import logging
import time
import timeit
from pathlib import Path
import numpy as np
import cv2
from PIL import Image
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from torch.nn import functional as F
import torchvision
import _init_paths
import models
import datasets
from config import config
from config import update_config
from core.function import testval, test
from utils.modelsummary import get_model_summary
from utils.utils import create_logger, FullModel
OUT_DIR = "./out/"
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
def image_resize(image, long_size, label=None):
h, w = image.shape[:2]
if h > w:
new_h = long_size
new_w = np.int(w * long_size / h + 0.5)
else:
new_w = long_size
new_h = np.int(h * long_size / w + 0.5)
print("new_w, new_h: ", new_w, new_h)
image = cv2.resize(image, (new_w, new_h),
interpolation = cv2.INTER_LINEAR)
return image
def input_transform(image):
image = image.astype(np.float32)[:, :, ::-1]
image = image / 255.0
image -= mean
image /= std
return image
def parse_args():
parser = argparse.ArgumentParser(description='Train segmentation network')
parser.add_argument('--cfg',
help='experiment configure file name',
required=True,
type=str)
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
parser.add_argument('--input-pic', type=str, default='../data/210306_437465_1810.jpg',
help='path to the input picture')
args = parser.parse_args()
update_config(config, args)
return args
def main():
if not os.path.exists(OUT_DIR):
os.makedirs(OUT_DIR)
torch.set_num_threads(1)
args = parse_args()
final_output_dir = '../output/douyu/seg_hrnet_w48_train_512x1024_sgd_lr1e-2_wd5e-4_bs_12_epoch484/'
#logger, final_output_dir, _ = create_logger(
# config, args.cfg, 'test')
#logger.info(pprint.pformat(args))
#logger.info(pprint.pformat(config))
# device = torch.device("cuda")
device = torch.device("cpu")
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
## cudnn related setting
#cudnn.benchmark = config.CUDNN.BENCHMARK
#cudnn.deterministic = config.CUDNN.DETERMINISTIC
#cudnn.enabled = config.CUDNN.ENABLED
# build model
#model = eval('models.'+config.MODEL.NAME +
# '.get_seg_model')(config)
model = models.seg_hrnet.get_seg_model(config).to(device)
print(model)
dump_input = torch.rand(
(1, 3, config.TRAIN.IMAGE_SIZE[1], config.TRAIN.IMAGE_SIZE[0])
)#.to(device)
#logger.info(get_model_summary(model, dump_input.to(device)))
#sys.exit(0)
if config.TEST.MODEL_FILE:
model_state_file = config.TEST.MODEL_FILE
else:
model_state_file = os.path.join(final_output_dir,
'best.pth')
# print("*********the model_state_file is {}".format(model_state_file))
#logger.info('=> loading model from {}'.format(model_state_file))
pretrained_dict = torch.load(model_state_file, map_location=device)
model_dict = model.state_dict()
pretrained_dict = {k[6:]: v for k, v in pretrained_dict.items()
if k[6:] in model_dict.keys()}
#for k, _ in pretrained_dict.items():
# logger.info(
# '=> loading {} from pretrained model'.format(k))
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
model.eval()
test_data = torch.rand(1,3,720,1280)#.to(device)
test_input = torch.autograd.Variable(test_data)
#记录原始模型的预测结果
# test_img = cv2.imread('')
# test_img = cv2.resize(test_img, (w,h))
# cv2.cvtCOlor
# test_img /= 255.f
# image = image.transpose((2, 0, 1))
# test_img[0] -
size = (1280,720)
ori_out = model(test_input)
pred = F.upsample(input=ori_out,
size=(size[0], size[1]),
mode='bilinear')
# pred = pred.to('cpu').detach().numpy()
# pred = pred.data.cpu().detach().numpy()
pred = pred.detach().numpy()
pred = np.asarray(np.argmax(pred, axis=1), dtype=np.float)[0]
np.savetxt("./ori_out.txt", pred, fmt="%.2f")
#模型转换
example = torch.rand(1, 3, 720, 1280)
# traced_script_module = torch.jit.script(model) #
traced_script_module = torch.jit.trace(model, example)
start_t = time.time()
new_out = traced_script_module(test_data)
pred = F.upsample(input=new_out,
size=(size[0], size[1]),
mode='bilinear')
pred = pred.detach().numpy()
pred = np.asarray(np.argmax(pred, axis=1), dtype=np.float)[0]
print("cost time: ", time.time() - start_t)
np.savetxt("./new_out.txt", pred, fmt="%.2f")
#保存模型
# traced_script_module.save("torch_script_eval.pt")
traced_script_module.save("torch_model.pt")
print("model convert success!")
if __name__ == '__main__':
main()
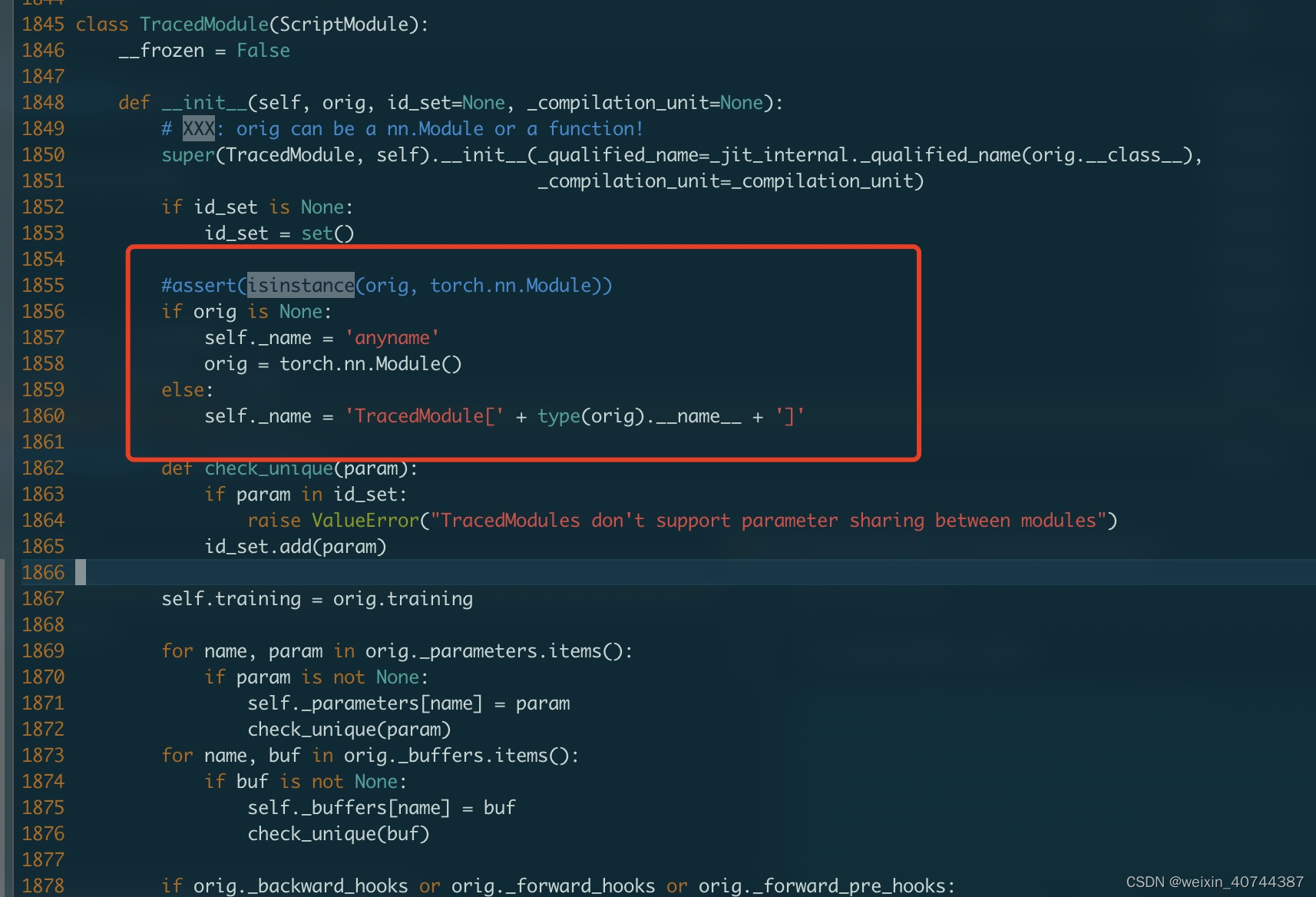
4. 报错记录:

- 报错地址:https://github.com/pytorch/pytorch/issues/30459
- 报错原因:模型中间有None
- 修改:修改当前conda虚拟环境中的__init__.py文件
vi +1885 /opt/conda/envs/pytorch_12/lib/python3.6/site-packages/torch/jit/init.py
修改如下:
完~















 4753
4753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









