







CGAN 论文笔记 结合看到的综合总结
 论文地址:Conditional Generative Adversarial Nets
论文地址:Conditional Generative Adversarial Nets
发表于:2014年SCI
2014年,Goodfellow提出了Generative Adversarial Networks,在论文的最后他指出了GAN的优缺点以及未来的研究方向和拓展,其中他提到的第一点拓展就是:A conditional generative model p(x|c) can be obtained by adding c as input to both G and D。这是因为这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的pixel的情形,基于简单 GAN 的方式就不太可控了。于是我们希望得到一种条件型的生成对抗网络,通过给GAN中的G和D增加一些条件性的约束,来解决训练太自由的问题。
同年,Mirza等人就提出了一种Conditional Generative Adversarial Networks,这是一种带条件约束的生成对抗模型,它在生成模型(G)和判别模型(D)的建模中均引入了条件变量y,这里y可以是label,可以是tags,可以是来自不同模态是数据,甚至可以是一张图片,使用这个额外的条件变量,对于生成器对数据的生成具有指导作用,因此,Conditional Generative Adversarial Networks也可以看成是把无监督的GAN变成有监督模型的一种改进,这个改进也被证明是非常有效的,为后续的相关工作提供了指导作用。
二元博弈问题
在之前的文章中,我们提到的Generative Adversarial Networks实际上是对D和G解决以下极小化极大的二元博弈问题:
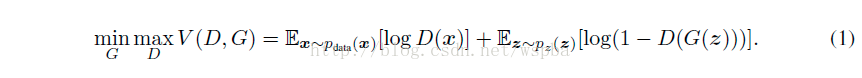 而在D和G中均加入条件约束y时,实际上就变成了带有条件概率的二元极小化极大问题:
而在D和G中均加入条件约束y时,实际上就变成了带有条件概率的二元极小化极大问题:
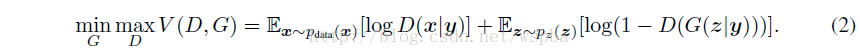
网络结构

在生成器模型中,条件变量y实际上是作为一个额外的输入层(additional input layer),它与生成器的噪声输入p(z)组合形成了一个联合的隐层表达;在判别器模型中,y与真实数据x也是作为输入,并输入到一个判别函数当中。实际上就是将z和x分别于y进行concat,分别作为生成器和判别器的输入,再来进行训练。其实在有监督的DBN中,也用到了类似的做法。
和原始的生成对抗网络相比,条件生成对抗网络CGAN在生成器的输入和判别器的输入中都加入了条件y。这个y可以是任何类型的数据(可以是类别标签,或者其他类型的数据等)。目的是有条件地监督生成器生成的数据,使得生成器生成结果的方式不是完全自由无监督的。
模型中z是噪声,y是条件(数据类型预先设定),将z加上条件y得到z|y,送入网络中训练得到样本G(z|y),这个G(z|y)就是生成出的假样本,其标签为0,送入鉴别器中。x是标签为1的正样本,加上条件y得到x|y,其含义是满足y条件的正样本,与送来的G(z|y)比较得到唯一的数值,反馈训练得到参数。
实验部分
Mnist数据集
在MNIST上以类别标签为条件(one-hot编码)训练条件GAN,可以根据标签条件信息,生成对应的数字。生成模型的输入是100维服从均匀分布的噪声向量,条件变量y是类别标签的one hot编码。噪声z和标签y分别映射到隐层(200和1000个单元),在映射到第二层前,联合所有单元。最终有一个sigmoid生成模型的输出(784维),即28*28的单通道图像。
在MNIST数据集的实验中,对于生成器模型,将label的one-hot编码与100维的均匀分布的噪声输入concat起来作为输入,输出是784维的生成数据,与数据集28*28的维度一致。对于判别器模型,作者使用了一个maxout的激活层,对maxout感兴趣的朋友可以去看Goodfellow2013年的一篇论文Maxout Networks,本文作者提到了模型的框架并不是限定的,只不过在这里使用maxout对于这个任务的效果非常好。

多模态学习用于图像自动标注
自动标注图像:automated tagging of images,使用多标签预测。使用条件GAN生成tag-vector在图像特征条件上的分布。数据集: MIR Flickr 25,000 dataset ,语言模型:训练一个skip-gram模型,带有一个200维的词向量。
在多模态的实验中,作者使用的是Flickr数据集,这个数据集具有大量的含有标签的图像,并且具有很多user-generated metadat/user-tags,而这些user-tags的好处是,相当于是很多人来描述这张图片,而不是仅仅来定义这张图片,并且对于不同的人来描述可能会出现很多同义词,这对训练也起到了非常有效的效果。>

在这里,作者的目的是利用图像的特征作为条件变量,生成词向量的分布,实现一个图像自动标注的功能。对于image feature,作者使用的是在ImageNet数据集上预训练的卷积神经网络,利用最后一个全连接层的4096个单元的输出作为图像特征。对于word representation,先从YFCC100M数据集中收集一个语料库,包含有相关的user-tags、标题以及描述等,然后训练一个skip-gram的模型,用来生成一个语义的字典。
然后在实验中,分别使用上面的卷积模型和skip-gram模型来提取Flickr数据集中的图片和tag特征,然后来训练我们的Conditional Generative Adversarial Network,最终实现了很好的图像自动标注的效果。
在文章的最后,作者提出了几点未来的研究方向,第一,文中使用的模型和方法都是比较简单的,作者希望能够探索更加sophisticated的Conditional Generative Adversarial Network;第二,在文章中的图像自动标注实验中,是每次单独使用一个tag,作者希望能够同时使用多个tags能达到更好的效果;第三,作者希望能够构建一个联合训练机制来学习一个language model,能够适应于特定的任务。
总的来说,Conditional Generative Adversarial Networks是在GAN上的一个简单的改进,但是取得了很好的效果,并且CGAN在很多场所都会有非常重要的运用。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









