







 本文提出了一种新的单幅图像去雨方法DID-MDN,该方法能够自动感知降雨密度并据此有效去除雨条纹。网络包含雨密度分类器及多流密集连接去雨网络,能适应不同尺度和形状的雨条纹。
本文提出了一种新的单幅图像去雨方法DID-MDN,该方法能够自动感知降雨密度并据此有效去除雨条纹。网络包含雨密度分类器及多流密集连接去雨网络,能适应不同尺度和形状的雨条纹。
Abstruct
- 由于不均匀密度的原因,单幅图像去雨是具有挑战性的,于是作者提出了DID-MDN的方法。该方法使网络本身能够自动确定雨密度信息,并根据估计的雨密度标签有效地去除相应的雨条纹;
- 为了different scals and shapes 的问题,作者提出了利用多尺度信息的网络结构。
- 另一个贡献在于提出了一个新的数据集
Introduction
提出问题,在单幅图像上消除水条纹
目前存在的办法
- 目前的办法为特定情形的去雨条纹而不能应对格只能够形状,密度和不同规模的情形,和训练时候的雨滴训练要求要一致才会有比较好的效果。一个可行的解决是建造数据集包含情形多的数据集,文献【6】已经这么做了,但是他只训练了一个网路并不能表征容纳所有的下雨情形。
-另一种解决思路是学习以密度为特征的除雨模型,但是这个缺乏灵活性,因为需要预先知道图片的降雨密度信息来选择对应的除雨网络。
作者的解决办法
- 提出自动感知降雨密度网络能够自动感知降雨的密度信息(大雨,中雨和小雨)。
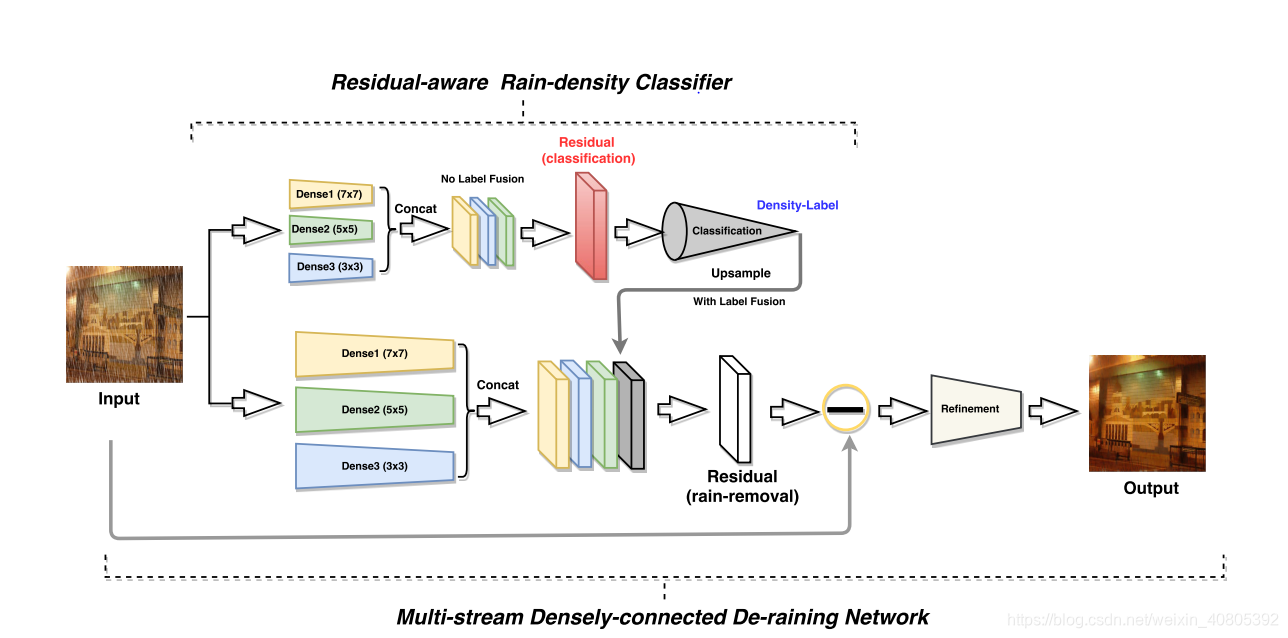
- 网络结构如下:结构采用的two-stages的方式,分别是雨滴密度检测和雨条纹去除。为了更好的预测雨的密度水平,提出了一种利用雨图像中残差分量进行密度分类的新残差感知分类器。雨条纹去除网络是基于多流密集连接网络,该网络考虑了雨条纹的形状和规模。一旦估算出了雨条纹的密度信息,我们将结合雨滴的密度在多流密集网路中输出对应的除雨后的图片。
本文的贡献
- 提出了DID-MDN算法,可以自动的估算雨滴密度,然后根据给出的密度信息除雨。
- 研究表明,残差感知是比较好表征雨密度信息的,本文提出的残差感知分类网络可以高效的得出雨条纹的密度信息。
- 第一个密度label的dataset。
- ablation study用于证明本文提出网络的不同模块的作用
背景和相关工作
单图像降雨
数学上,一张带有雨条纹的图Y可以由背景图X和雨条纹r线性表示:
可以看出这是个病态的困难的问题,不同于视频除雨可以利用视频信息(可以考虑),已经有研究者提出利用先验知识来解决除雨的问题,这包括有基于稀疏编码,基于低秩表示和基于高斯混合模型的办法,对于这些方法而言,存在一个大问题就是会过于平滑图像的细节。近几年由于深度学习在处理low-level和high-level问题上的成功,一些基于CNN的方法被提出用于除雨,这些方法学习一种从下雨到无雨的映射关系。
多尺度特征融合
融合多尺度的卷积特征能够更好的表征一张图片中的物体和它的周围(关系),例如,
- FCN网络结构采用skip-connection以及在中间层添加了高级预测层来生成多分辨率的像素预测结果
- 同样Unet也是由捕获上下文的收缩路径和支持精确定位的对称展开路径组成
- HED模型采用深度监督结构,自动学习丰富的层次表示,并融合这些表示来解决边缘和目标边界检测中具有挑战性的模糊性
多尺度特征融合已经用于各种的应用中,比如语义分割,人脸对其,视觉追踪,人流检测,行为识别,深度估计,单一图像去雾,同时也出现在了去雨[33],和33文献一样,本文也利用多尺度的信息去获取图片中雨条纹元素的scale和shape,然而,不是用不同的dilation factors作用于两个不同的卷积层的方式来结合不同尺度的特征,我们利用残差连接块作为基础Model,最后我们连接来自每一个块的特征为后续除雨。最后我们通过ablation study证明了我们方法的有效性对比33。
模型简化测试。 看看取消掉一些模块后性能有没有影响。 根据奥卡姆剃刀法则,简单和复杂的方法能达到一样的效果,那么简单的方法更可靠。 实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。 比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study
Method
我们提出的DID-MDN主要包括了两个模块,其一,残差感知密度分类器,其二是multi-stream densely connected 的除雨网络,换言之,除雨网络是通过前者分类网络给出的密度标签给出有效的除雨效果。
残差感知雨滴密度分类器
正如前文提到的一样,虽然一些网络在除雨上取得了不错的效果,但是他们经常会出现或多或少的错误,这主要是由于单一的网络不能表征足够的雨条纹的信息,我们相信在网络中加入密度级别的信息有利于整体的学习过程,从而可以更好的泛化不同的降雨条件,类似的方法也出现在了[23]当中,他们也先验的表征小雨和大雨,我们的密度label是来自于CNN分类器,不是先先验的。了准确地估计雨输入图像的密度信息,提出了一种基于残差感知的雨密度分类器,利用残差信息更好地表示雨的特征。此外,为了训练分类器,我们还合成了一个包含12000张带有密度标签的雨图像的大规模合成数据集。需要提出的是,只有三种类型的类(即标签)出现在数据集中,它们对应于低、中、高密度。
训练新分类器的一种常见策略是在新引入数据集上对预先定义的模型进行微调,如VGG-16[26]、Res-net,Dense-net 等[11],利用新数据集的微调策略的一个基本原因是,在这些预定义模型中编码的区分特征可以有利于加速训练,而且还可以保证更好的泛化。然而,我们观察到,直接微调这样一个“深入”模型对我们的任务不是一个有效的解决方案,这主要是由于CNN的高级特征(较深的部分)更倾向于在输入图像中对识别对象进行局部化,因此,相对较小的雨带可能无法很好地定位在这些高层特征中,换句话说,雨条纹信息可能会丢失在高级特性中,从而降低总体分类性能,因此,提出一种更好的特征表示方法来有效地描述雨条纹是非常重要的。
我们可以把r = y - x看作是描述降雨密度的残差分量。为了从观测图像y中获得雨量残差值r,一个没有标签融合,采用新数据集中高密度雨量训练的multi-stream 残差网络被提出,然后,将估计的残差作为训练最终分类器的输入,这样,残差估计部分就可以看作是特征提取过程1
,这将在第3.2节中讨论。这样,残差估计部分就可以看作是特征提取过程1 ,这将在第3.2节中讨论分类部分主要包括三个卷积层(Conv),内核大小为3×3,一个平均池(AP)层,内核大小为9×9,两个全连接层(FC)。
分类器的详细信息如下:
Conv(3,24)-Conv(24,64)-Conv(64,24)-APFC(127896,512)-FC(512,3),
(3,24)表示输入由3个通道组成,输出由24个通道组成,注意,最后一层由一组3个神经元组成,表示输入图像的雨密度类别,第4.3节讨论了ablation study,证明了与VGG-16[26]模型相比,提出的残差感知分类器的有效性。
残差感知分类器的Loss
为了有效地训练分类器,采用了两阶段训练协议,首先训练残差特征提取网络对给定的雨图像残差进行估计,然后利用估计残差作为输入训练分类子网络,并通过真值标签(雨密度)进行优化,最后,对特征提取和分类两个阶段进行了联合优化。用于训练残差感知分类器的总体损失函数如下:
L = L E,r + LC , (2)
其中,LE,r表示估计残差分量的每像素欧式损失,LC表示雨密度分类的交叉损失。
Multi-stream 残差网络
不同的雨图像包含不同尺度和形状的雨条纹,如下图所示

图3(a)中的雨带比较小,可以通过较小区域的特征图(具有较小的接受域)捕获,然而图(b)包括比较长的雨带,可以被比较大的感受野(特征图)所捕获,因此我的觉得通过结合各个尺寸大小的感受野可以比较好的捕获各种类型的雨带。
由于采用多尺度整合所获得成功【33】的激励,一种更有效的multi-stream 残差连接网络,被用于预测雨带大小的网络被提出,每一个stream都是建立在不同卷积核大小的dense-block上,这些stream blocks由 Dense1(77),Dense2(55),Dense1(3*3)表示。此外,为了进一步提高不同bloks之间的信息流动和更好的利用不同大小的dense-bblock来预测雨带成分,我们引入了一种改进的连通性,将每个块的所有特性连接在一起进行雨条纹估计。这就不同于文献[33]中,在每个stream中只是采用了两个卷积层,我们在不同尺度的特征之间创建短路径,以增强特征的聚集性,获得更好的收敛性,与[33]中提出的多尺度结构相比,为了验证了所提出的多流网络的有效性,进行了sblation study.
为了使用雨带密度信息来引导网络除雨,向上采样的标签映射(例如,如果标签为1,则对应的上采样标签映射与每个流的输出特征具有相同的维数,标签映射的所有像素值都为1。)与来自所有三个stream 的雨条纹特性连接在一起,然后,利用串联特征估计残差(ˆr) rain-streak信息,此外,从输入的雨图像中减去残差,估计出粗略的去雨图像.此外,从输入的雨图中减去对应的残差值就得到了对应的除雨之后的值了。最后,为了进一步完善估计的除雨后的图像和保证更好的细节会被保留,另外两个代用Relu的卷积层被应用于最后的完善。
在每个stream中都包含有6个dense-block,数学上说,每一个stream可以表达为:
sj = cat[DB1, DB2, ..., DB6],
这里的cat表示的是串联关系,DB表示每一个dense-block的输出,s表示每一个stream。除此以外,在每一个stream我们采用了不同的转换层组合和核大小,细节展示如下:
Dense1: three transition-down layers, three transition-up layers and kernel size 7 × 7.
Dense2: two transition-down layers, two no-sampling transition layers, two transition-up layers and kernel size 5 × 5.
Dense3: one transition-down layer, four no-samplingtransition layers, one transition-up layer and kernel size 3 × 3.
下图以stream1的dense1为例:

De_raining 网络的损失函数
受到基于CNN特征结构为基础的损失函数可以很好的提升语义边界信息和进一步提升除雨后图像的可视质量,我们同样的损失是基于像素欧几里得差异和特征损失的加权,对multi-stream残差连接网络的损失函数如下:
L = LE,r + LE,d + λF LF , (4)
其中 LE,d 表示每像素的欧几里得损失用于重建除雨后的图片,LF为基于特征差异的损失函数,定义为:
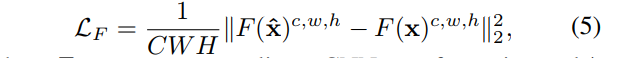
其中F表示的是非线性CNN变换,x帽表示的是除雨后剩下的照片,这里我们假设特征具有的大小为w*h,c个通道,在我们的方法中,我们计算的特征损失是在VGG_16模型上的relu_2上执行的。
测试
在测试中,雨密度label通过残差感知分类网络得知,接着,向上采样-标签映射和对应的输入图像一起喂给multi-stream 网络用于得到最终的除雨图片。
实验结果
在这个部分中,我们展示实验细节和评价结果在合成和真实的数据集上,除雨表现在综合数据集的评价采用PSNR和SSIM指标
PSNR(Peak Signal to Noise Ratio)峰值信噪比,一种全参考的图像质量评价指标,为广泛的一种图像客观评价指标,
然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,
人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
SIM(structural similarity)结构相似性,也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。SSIM取值范围[0,1],值越大,表示图像失真越小
由于真实完全准确的照片在现实世界的图片中是不存在的,因此对于不同的方法在真实数据集上做的是可视化评估,DID-MDN方法和当前表现最好的方法进行了比较,有DSC(ICCV15),GMM based method (CVPR16),CNN method(TIP17) ,DDN(deep detialed network CVPR17)…很多就不列举了。
综合数据集
尽管目前已经存在了很多综合数据集,但是它们都缺少对应的雨密集度的label,因此,我们制作了12000张图片,每张图片都针对对应的雨密集度进行标签设置,整个数据集只用三种类型的标签,大致每一种标签的图片有4000张,类似的,我们也同样的synthesize了Tests数据,包含有1200张图片,确保了包含了不同雨量和方向的图片都存在,图像通过photoshop合成,牛!。我们通过修改第三步来修改图像引入雨滴的级别,其中小,中,大分别对应的噪声级别为:5%-35%,35%-65%,65%-95%。如下图所示:

为了更好的泛化性能,我们随机的抽取1000张图片从[6]提供的数据集中。
训练细节
我们随机的从输入图片(586586)或者是它对应的水平翻转的照片中截取512512的大小,Adam方法被用于优化,batchsize为1,Learning rate为0.001,每20epochs后就会除以10,这个模型被训练达到80*12000次迭代,我们使用权值衰减为0.0001,动量为0.9;整个网络使用Pytorch框架进行训练。训练期间,我们组λF = 1。所有参数都是通过使用验证集进行交叉验证来定义的。
Ablation study
实验结果
好久完事了!!!

















 3028
3028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









