







场景: 你的公司内部文档分散,各种合同、手册、产品文档堆积如山,想找到某个特定文档或信息时,往往费时费力,甚至需要翻阅大堆纸质文件。新员工上岗培训也是一项庞大的任务,不仅需要讲解,还要反复查找资料。面对这样的问题,企业如何高效地管理和获取知识呢?
解决方案: 通过 AnythingLLM Desktop,你可以快速搭建一个本地化的知识库,上传企业内部的各种文件,一键生成私有数据库,确保所有信息都在你掌控之中。比如,将公司合同、员工手册、产品文档、会议纪要等资料上传到系统。接下来,接入 DeepSeek 模型,员工可以通过简单提问快速获取所需的信息。例如:“第三季度销售目标是什么?”、“如何申请年假?”等问题,只需秒级查询,答案迅速呈现!
优势:
✅ 数据完全本地存储, 确保所有资料保密,杜绝外泄风险。无论是财务报表还是客户信息,都能安全存储。
✅ 支持离线使用,即使处于内网环境,也能实现高效的AI运作,确保任何时候都能快速获取信息。
✅ 简化新员工培训,新员工只需提问即可得到快速的答案,告别冗长的培训文档和一对一讲解。
实际案例: 一家全球500强公司部署了这套方案,员工工作效率提升了20%,新员工入职培训时间缩短了50%,有效节省了大量人力和时间成本。
使用 DeekSeek-R1 和 AnythingLLM 搭建本地知识库,完全本地化,无需联网,并解决大模型杜撰问题。
一、本地部署DeepSeek + Ollama
本地部署DeepSeek + Ollama 小白也能轻松搞定!
二、AnythingLLM 下载和安装
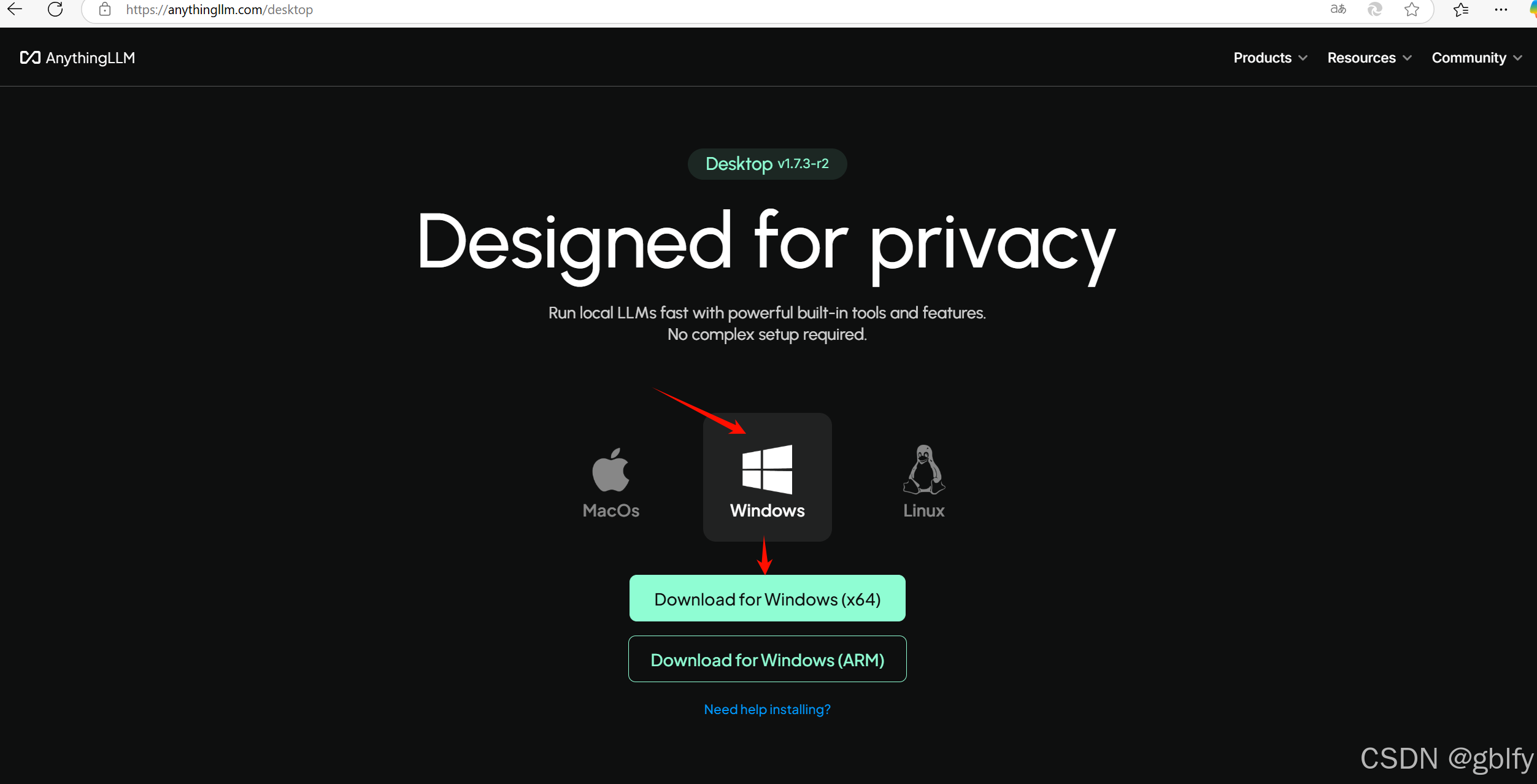
2.1. AnythingLLM 下载
官网链接:https://anythingllm.com/desktop
2.2. AnythingLLM 安装
点击Get Started
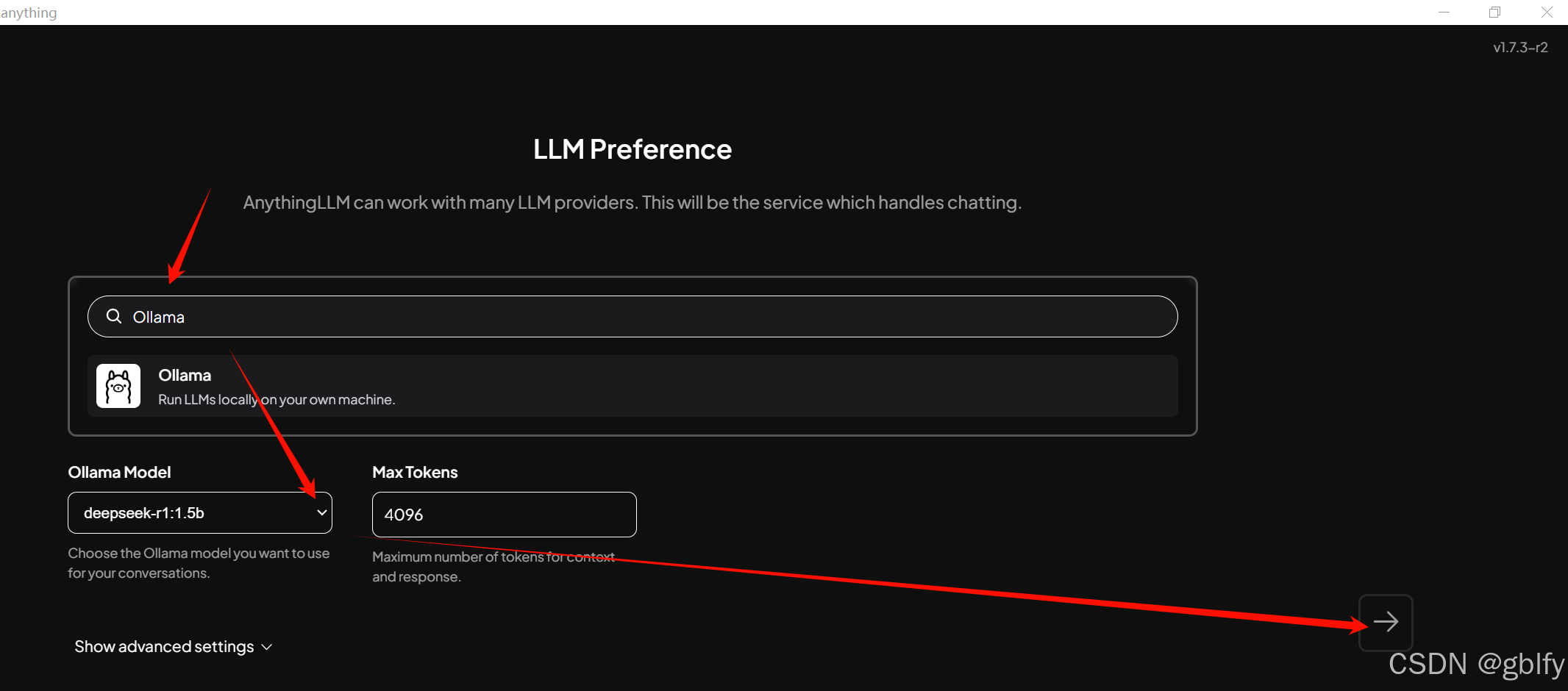
它首先会让我们选择LLM,我们搜索Ollama,并确定下面的模型与我们之前下载的相同,我这里是deepseek-r1:1.5b,然后点击下一步
Ollama
再点击下一步
模型配置
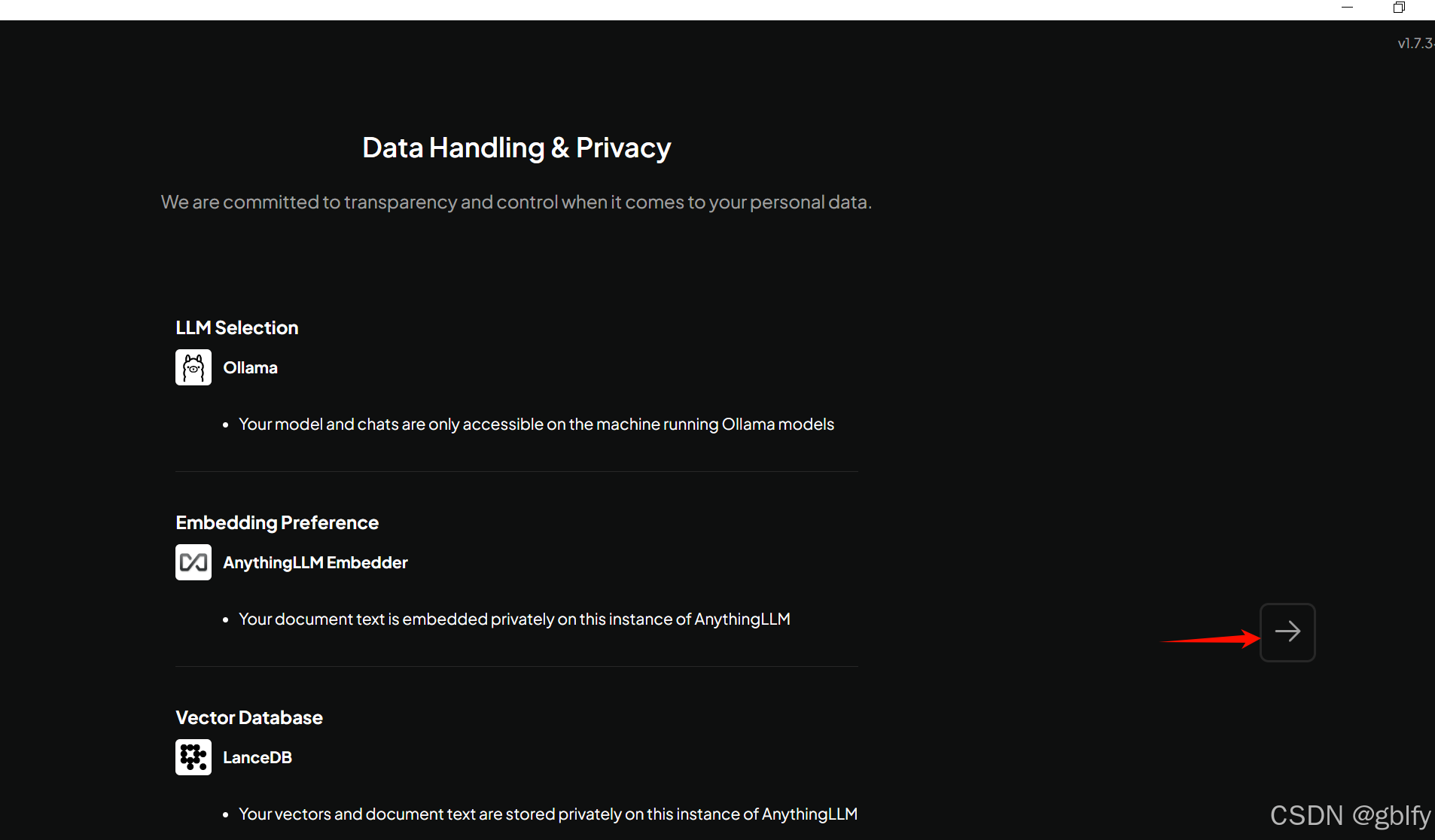
- 1、LLM Selection(大语言模型选择):
这里选择了名为 Ollama 的模型。
说明用户的模型和聊天记录仅在运行 Ollama 模型的机器上可访问,这意味着数据不会在其他地方被存储或访问,从而增强了数据的安全性和隐私性。
- 2、Embedding Preference(嵌入偏好):
使用了名为 AnythingLLM Embedder 的嵌入工具。
说明用户的文档文本是在 AnythingLLM 的实例上私密嵌入的,这意味着文本数据的处理和转换是在本地进行的,不会泄露给第三方。
- 3、Vector Database(向量数据库):
使用了 LanceDB 作为向量数据库。
说明用户的向量和文档文本都是存储在这个 AnythingLLM 实例上的,这再次强调了数据的私密性和安全性。
收集用户对 AnythingLLM 服务的反馈,可选的调查问卷,可直接跳过。之后我们点击Skip Survey,
2.3. AnythingLLM 创建工作区
输入工作区名称Default,自定义即可,点击下一步
Default
之后我们便来到了AnythingLLM的主界面,到这里我们就算启动成功了
2.4. AnythingLLM 主题设置
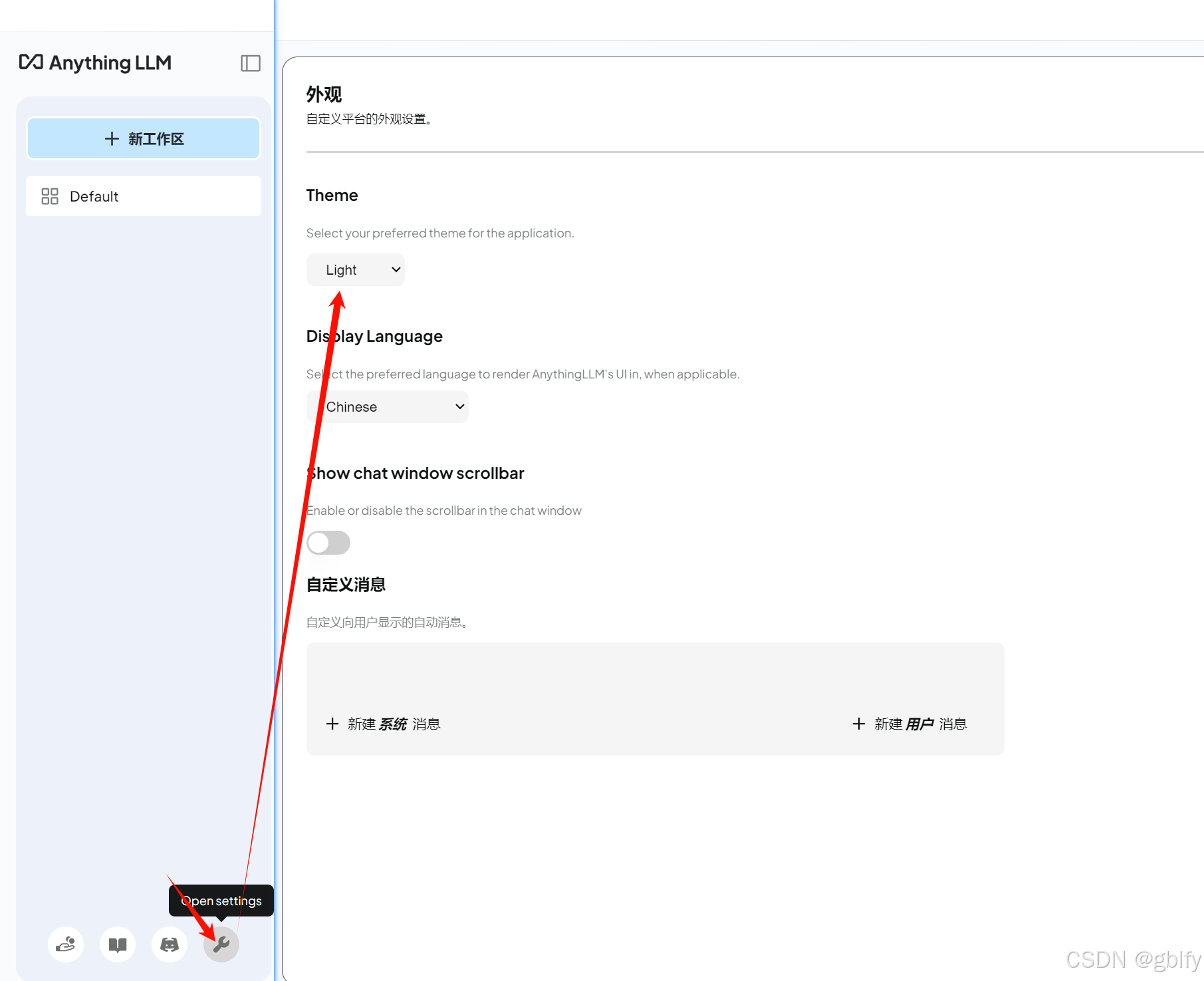
2.5. AnythingLLM 界面语言设置
界面默认是英文的,修改为中文
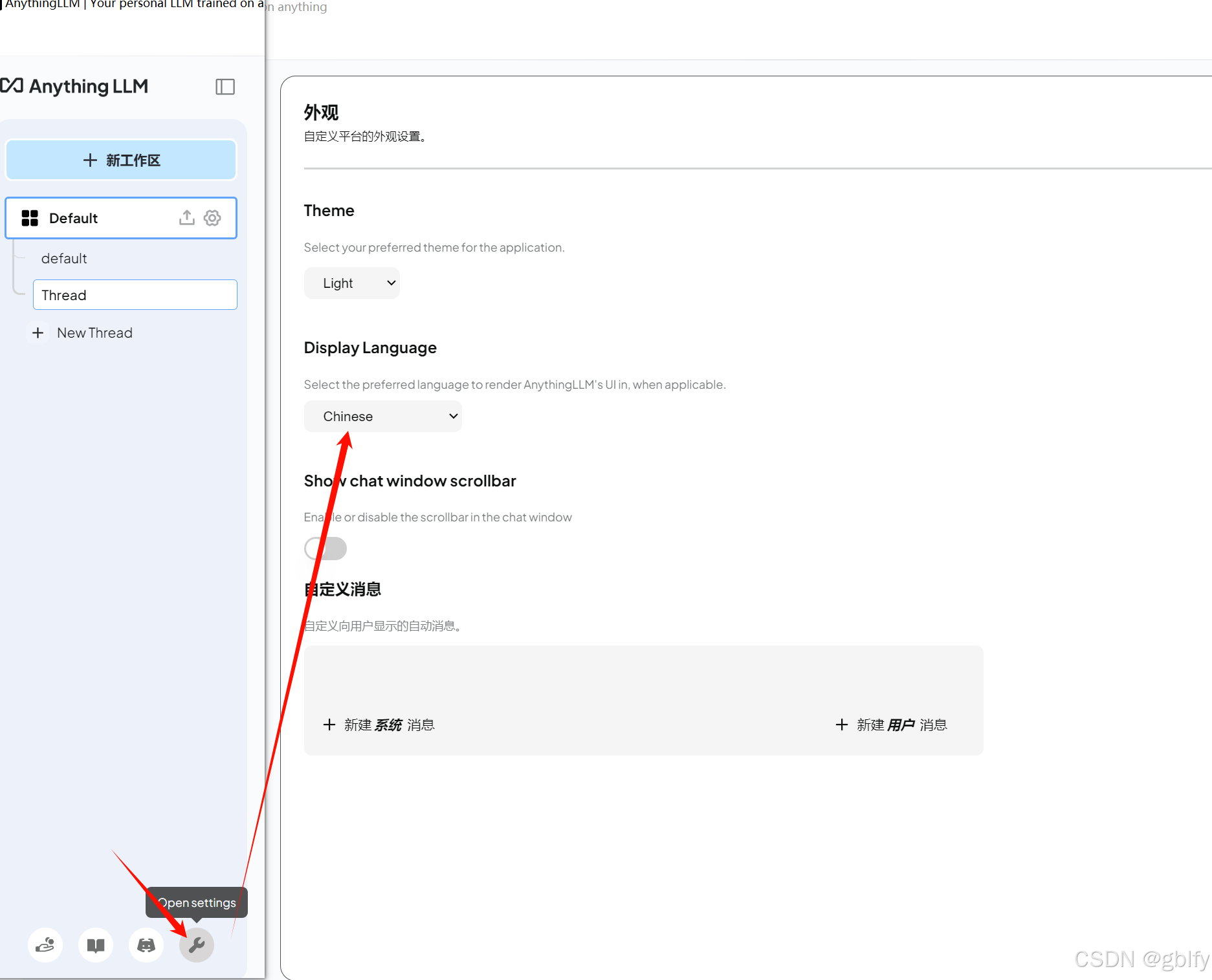
2.6. AnythingLLM 回答语言设置
当我们问的问题在所有文档里面都找不到的时候,AnythingLLM会诚实的告诉我们找不到,但回答用的是英文。你如果想改成中文的话,可以点击工作区的配置按钮,再点击里面的聊天配置,将拒绝响应内容修改为中文。
在此工作区中没有相关信息来回答您的查询。
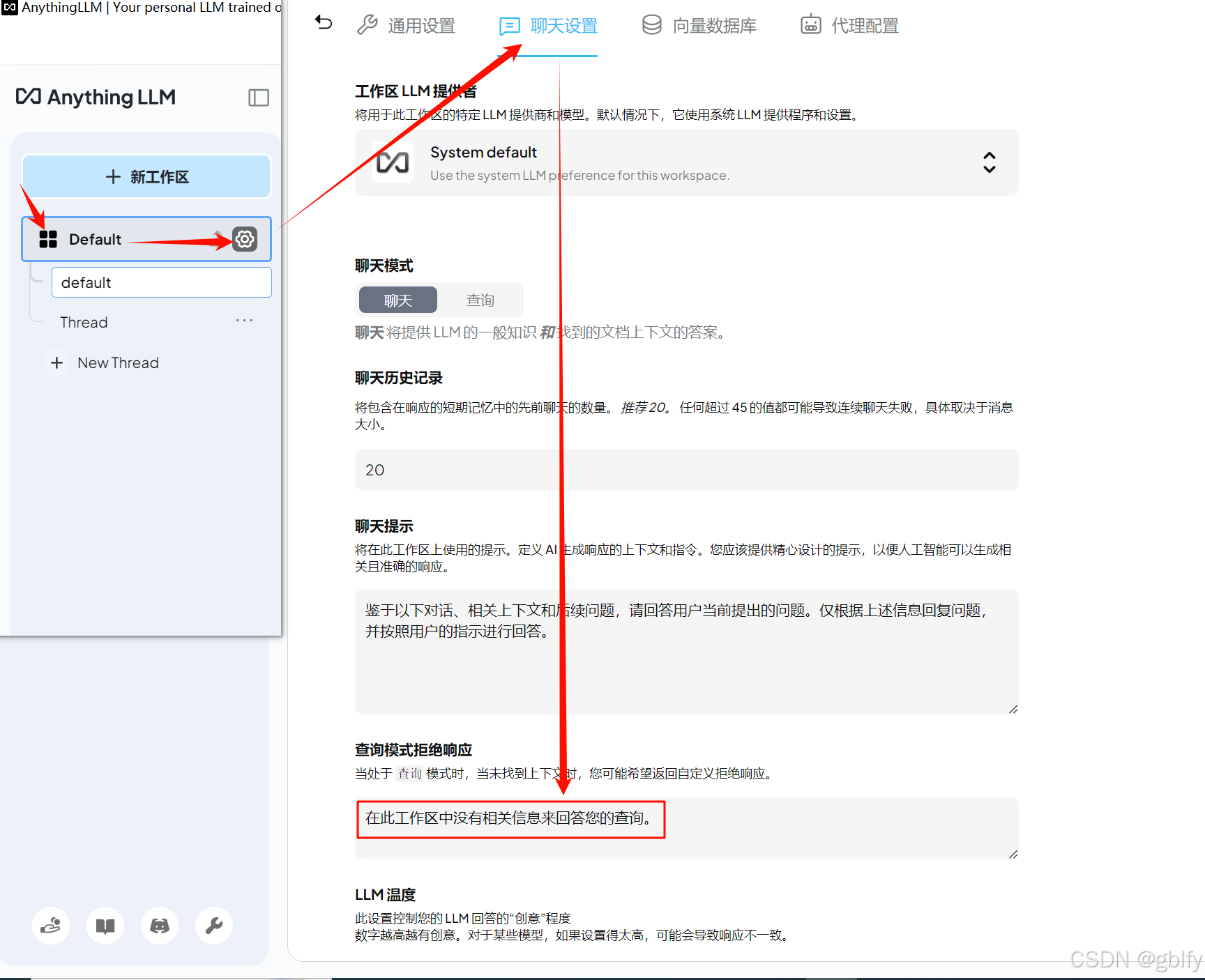
你可能会发现上面有个聊天提示也是英文的,与下面拒绝响应内容不同的是,聊天提示是在问题有对应文档的时候使用的
AgythingLLM会将你的问题,对应的文档内容和聊天提示,同时发送给DeepSeek,引导他通过文档来回答问题,如果聊天提示为英文的话,Deepseek偶尔也会选用英文回答,为了解决这个问题,你也可以将聊天提示修改为中文。
鉴于以下对话、相关上下文和后续问题,请回答用户当前提出的问题。仅根据上述信息回复问题,并按照用户的指示进行回答。
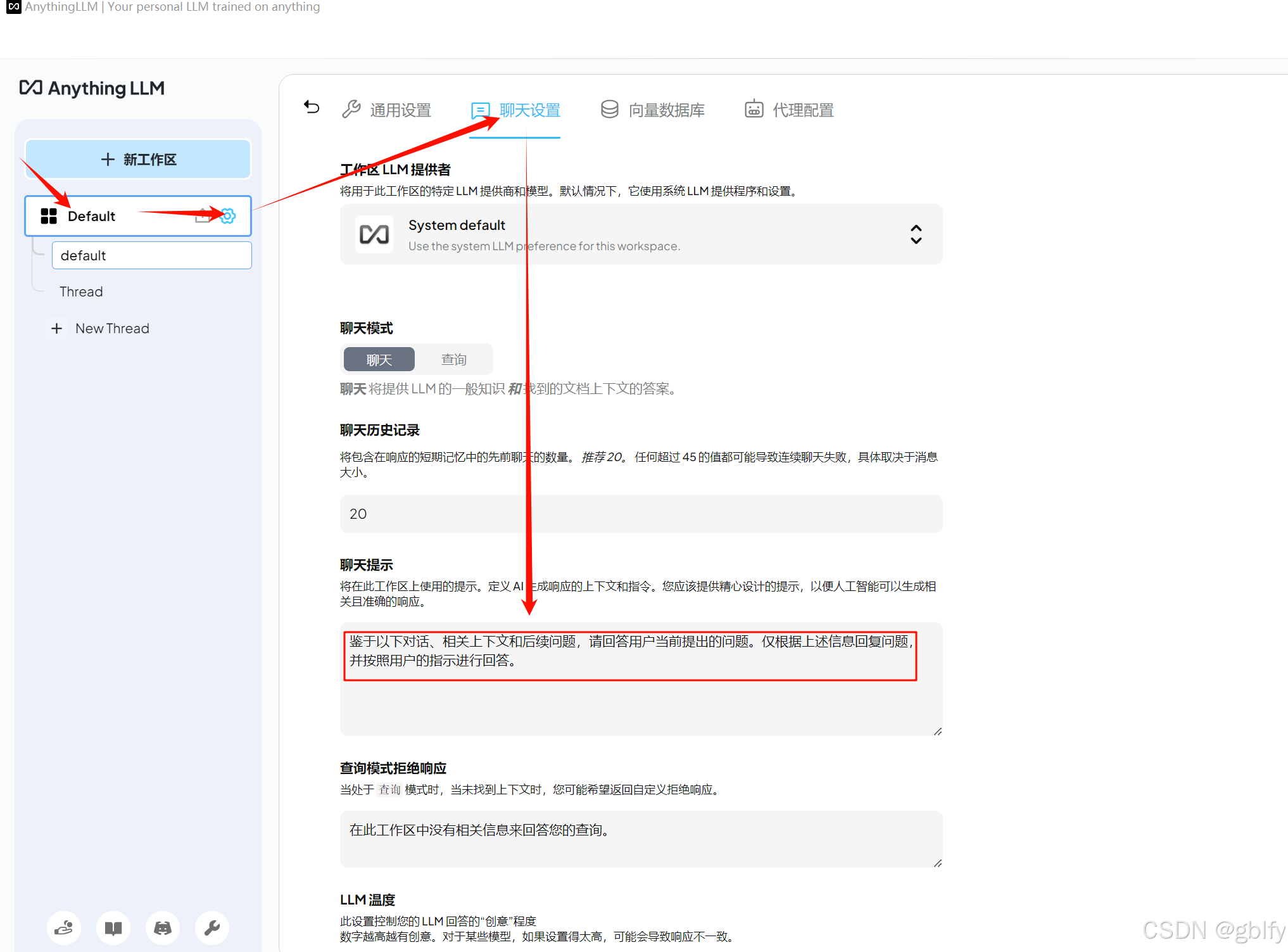
全部修改完毕后,我们点击最下面的Update Workspace,然后返回问答页面。
2.7. AnythingLLM 聊天对话
Anything LLM的左侧为工作区,这个Default便是我们初次启动时定义的工作区名称,右侧便是对话区
我们可以随便在对话区问问试试
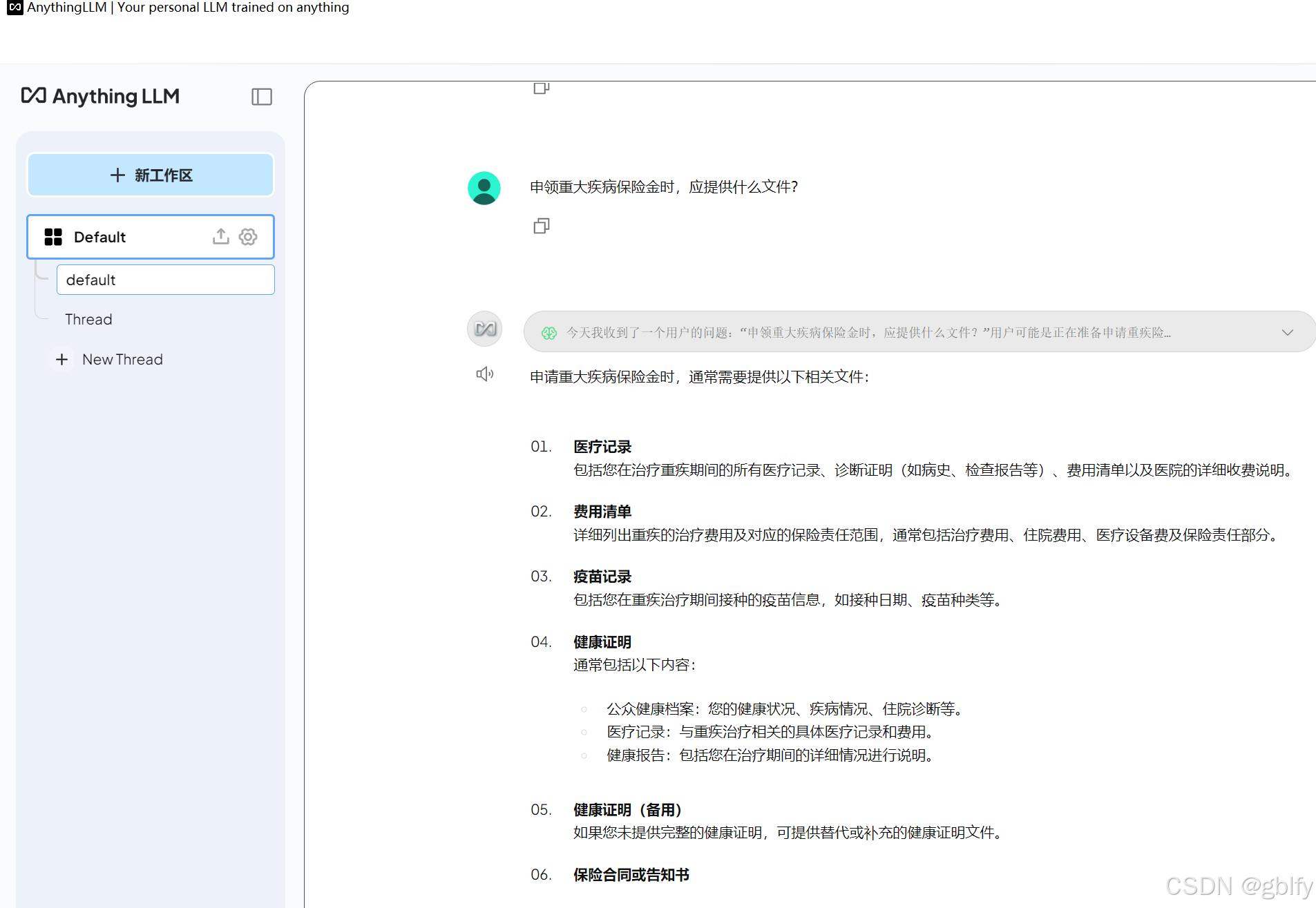
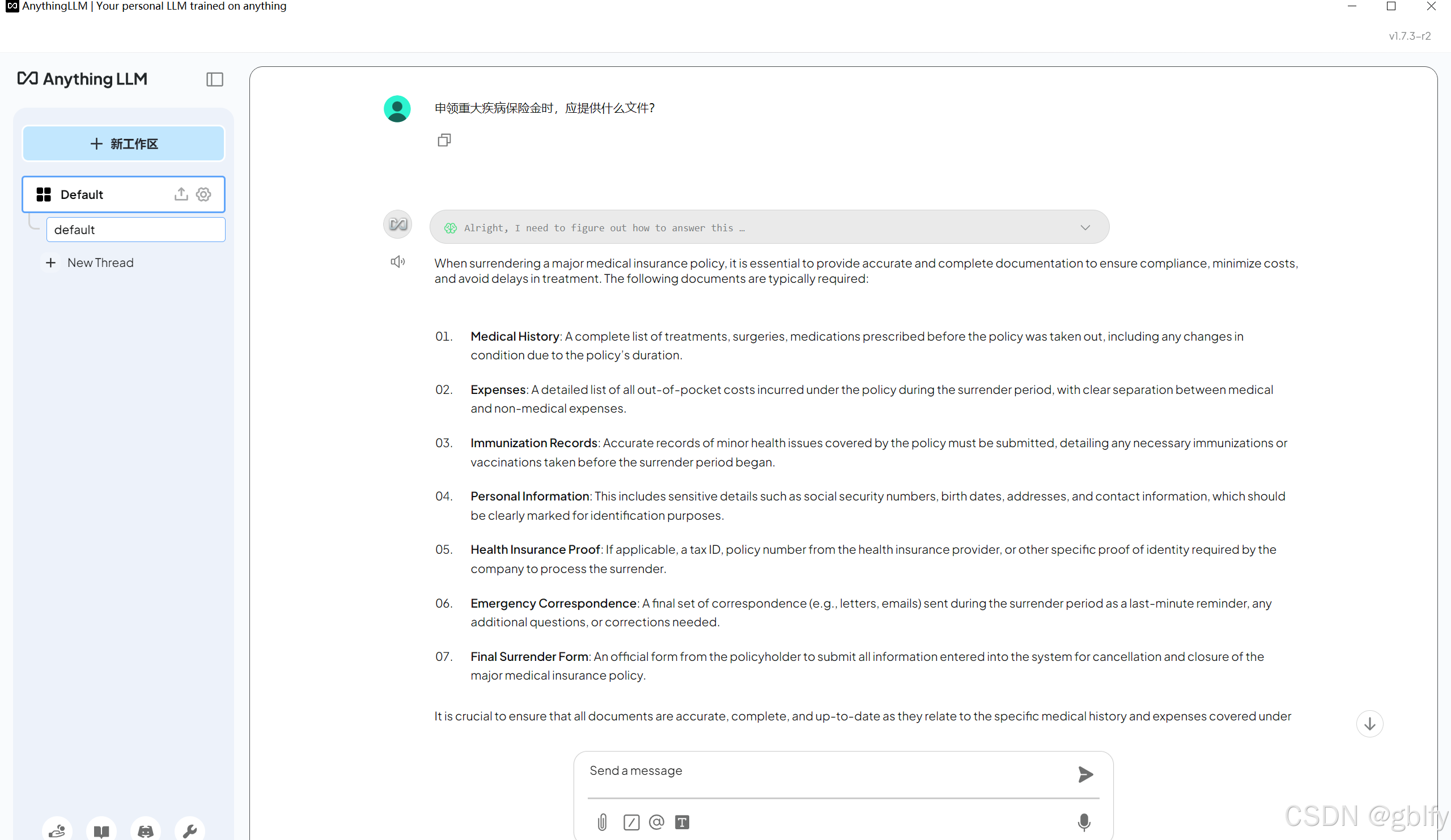
申领重大疾病保险金时,应提供什么文件?
默认回答的是英文,看不懂
如果设置了 2.6. AnythingLLM 回答语言设置此时,AnythingLLM给我们返回的就是中文效果了。
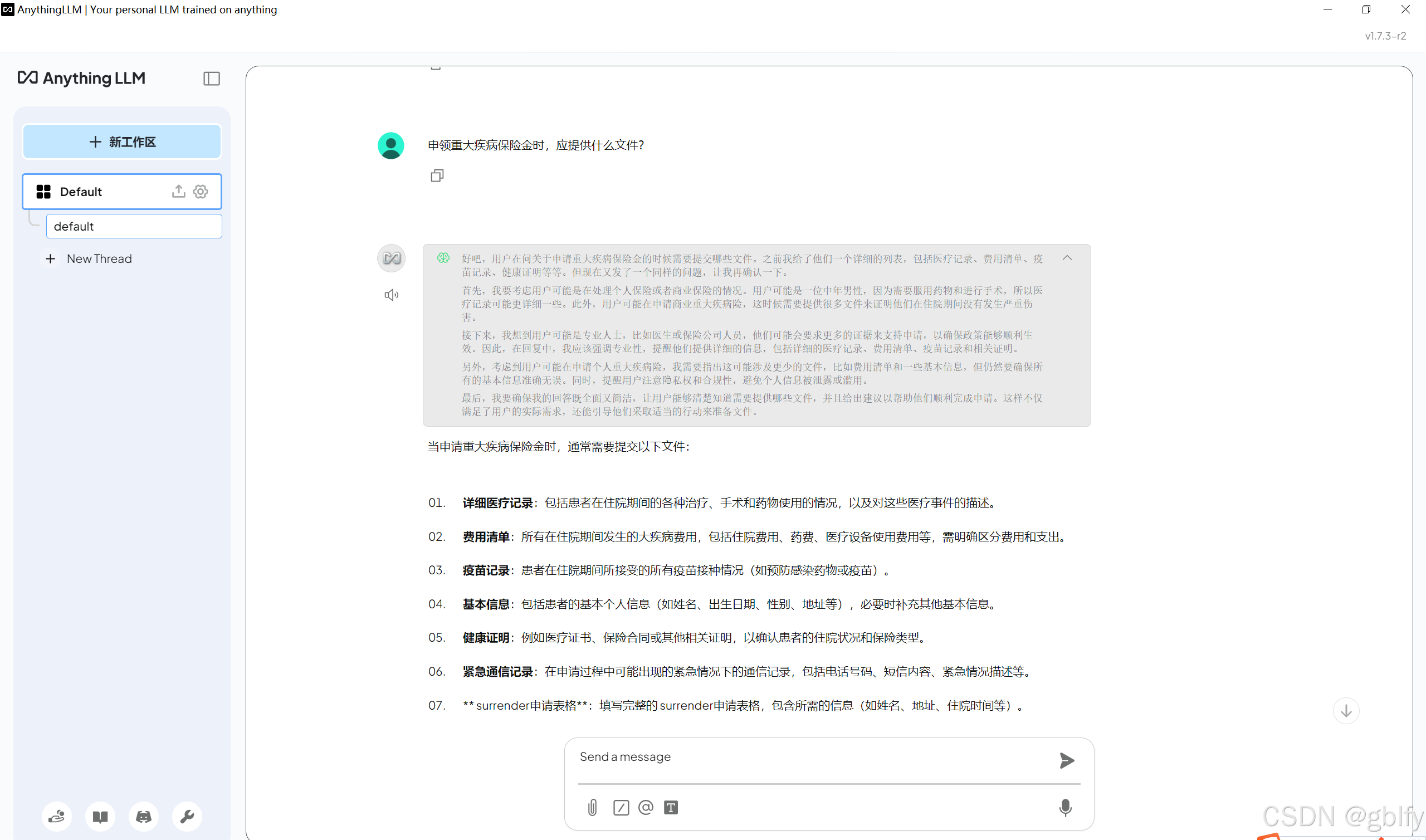
2.8. 回答分析
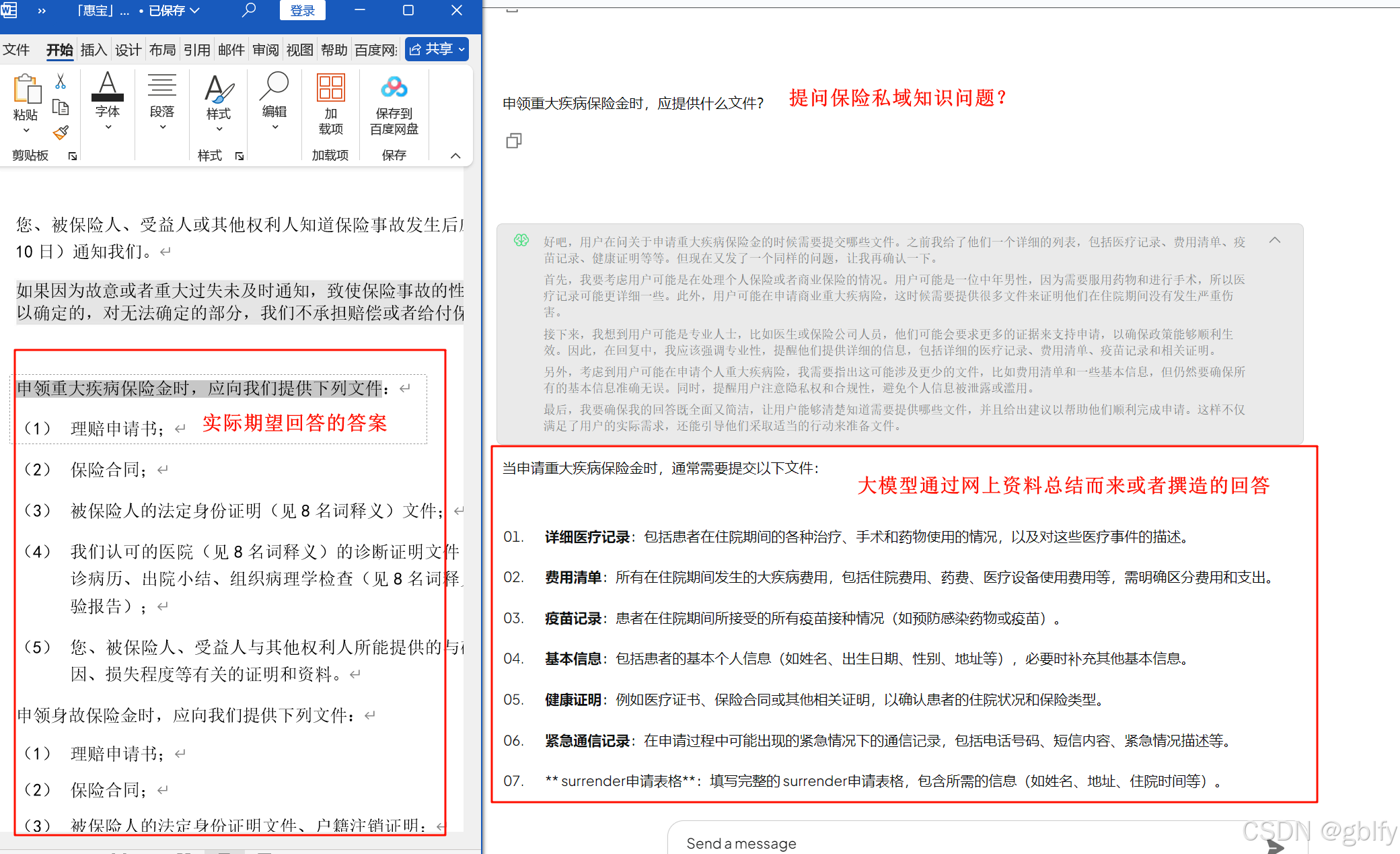
从上面大模型回答分析得出结论,当提问大模型不知道的知识时,大模型会搜索网上资料或者撰造一些知识总结形成最终回答,很明显,当提问私域保险知识时,大模型回答是不符合预期的。
我们怎么能上大模型诚实地告诉我们它不知道呢?我们可以点击工作区左侧的设置按钮,再点击聊天配置
可以看到这里有两介聊天模式,一个是聊天,一个是查询,当AnythingLLM没有在我们上传的文档里面找到,任何与间题相关的内容的时候,这两种模的处理方式是不一样的。
- 聊天模式:会根据大模型自己的知识给我们一个答案,即使这个答案是错误的,它也会强行回答。
- 查询模式:则会在此时诚实地告诉我们,找不到任何相关的文档。
我这就将密改成查询模式
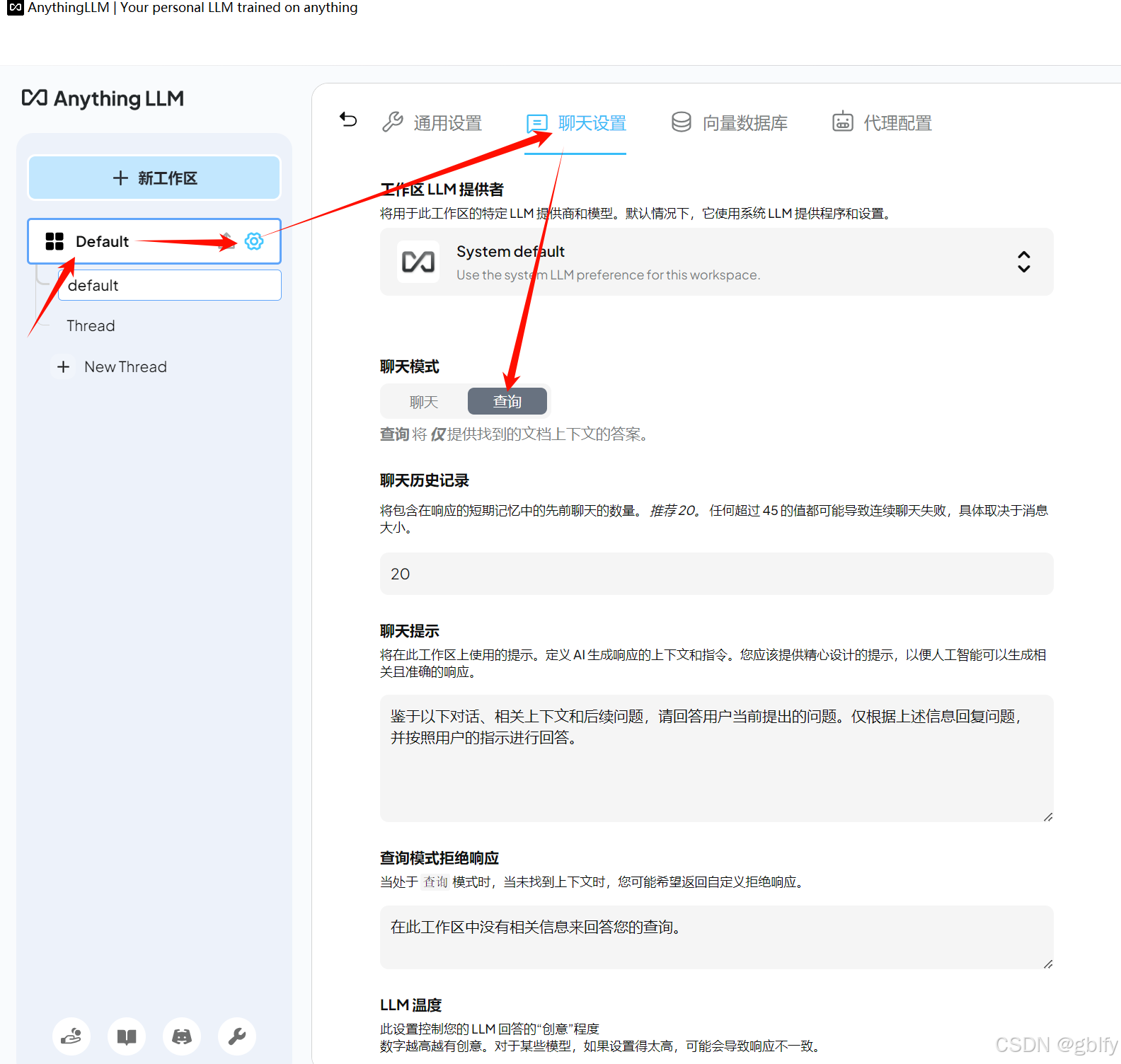
然后点击Jpdate Workspace更新工作区
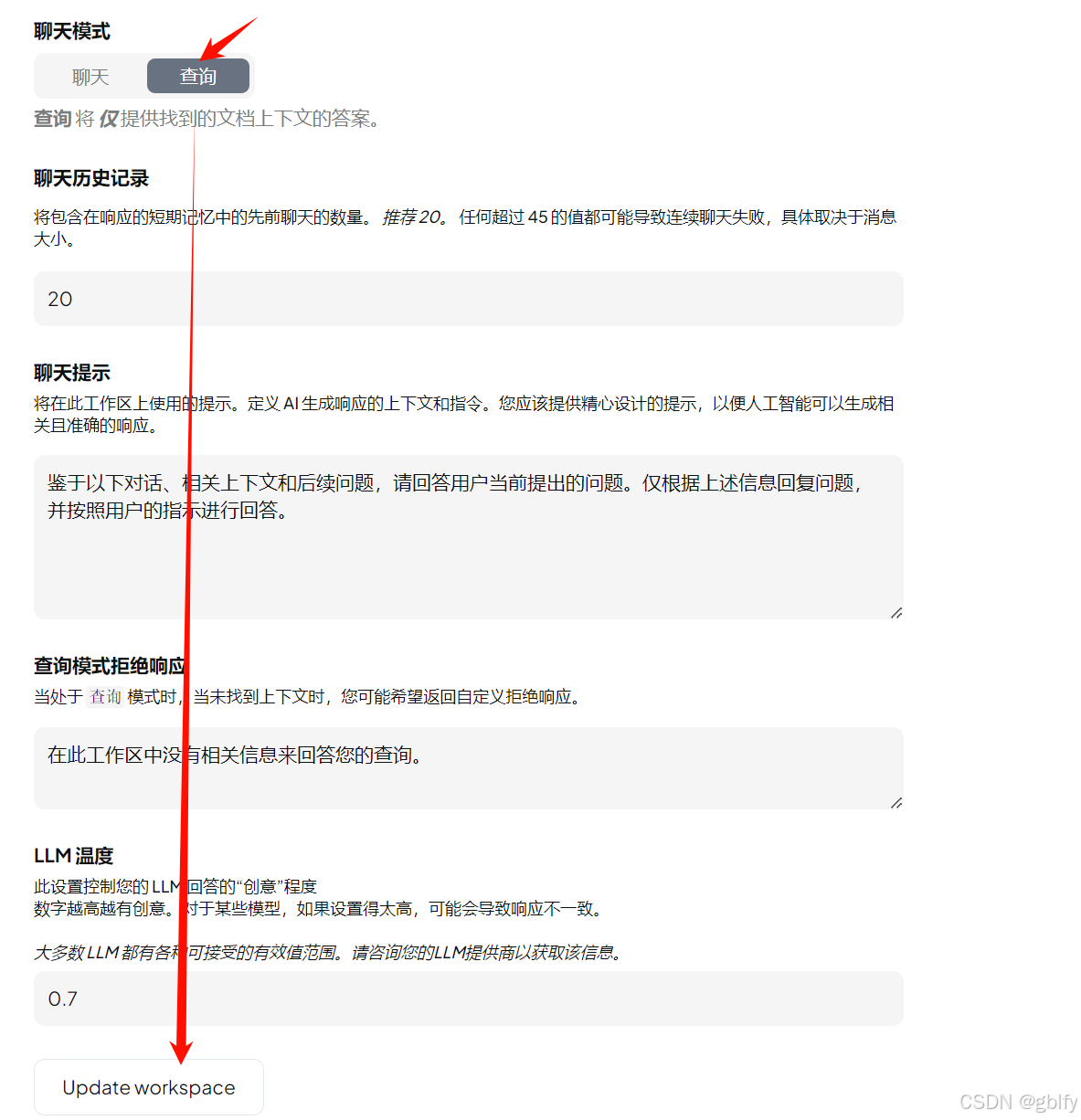
这样可以有效地防止大模型胡说八道,设置好了之后,我们回来再问一下相同的问题
申领重大疾病保险金时,应提供什么文件?
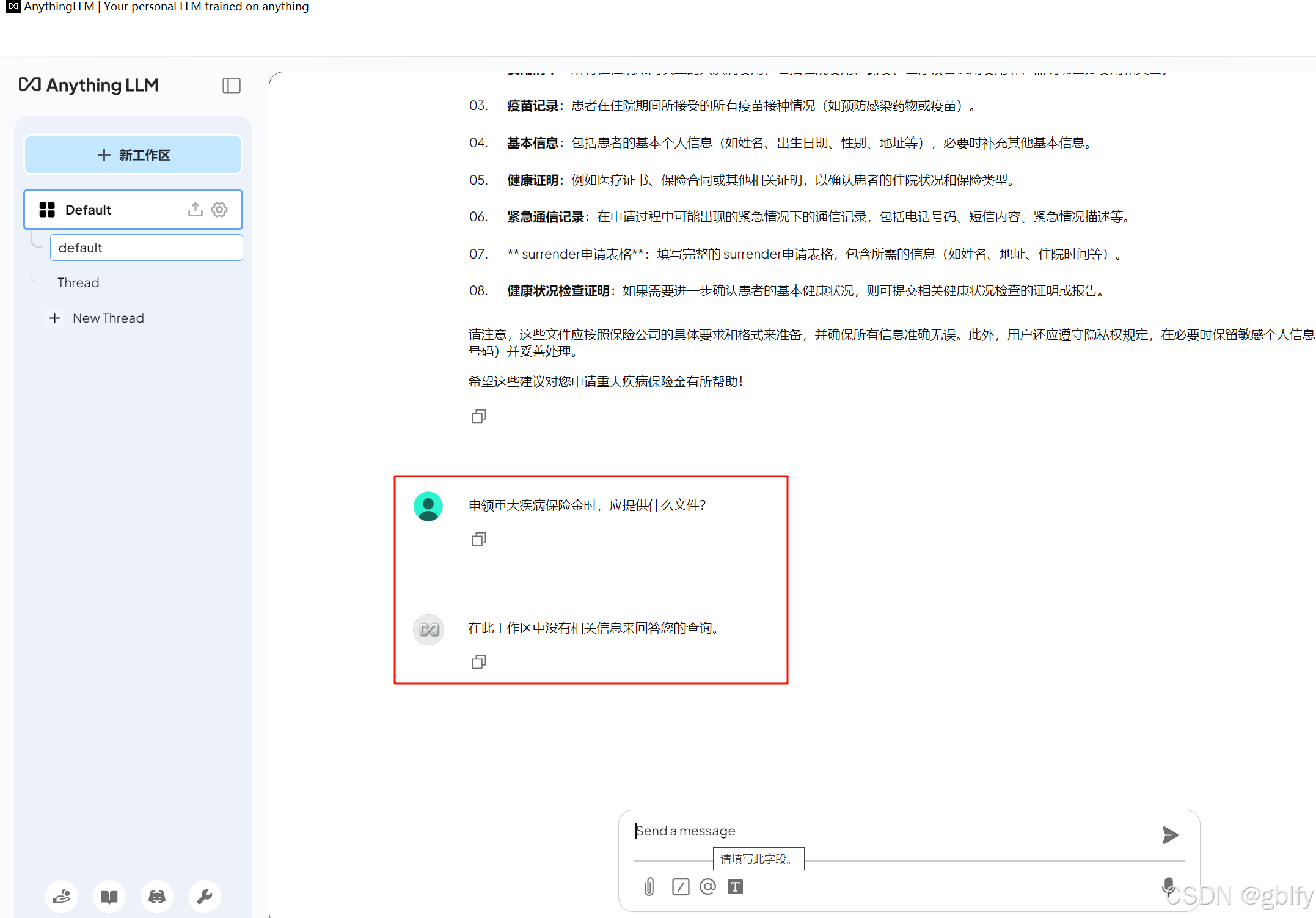
可以看到这次AnythingLLM,直接告诉我们没有相关的信息
三、知识库
3.1. 上传文档
我们把这一个文件拖到AnythingLLM里面
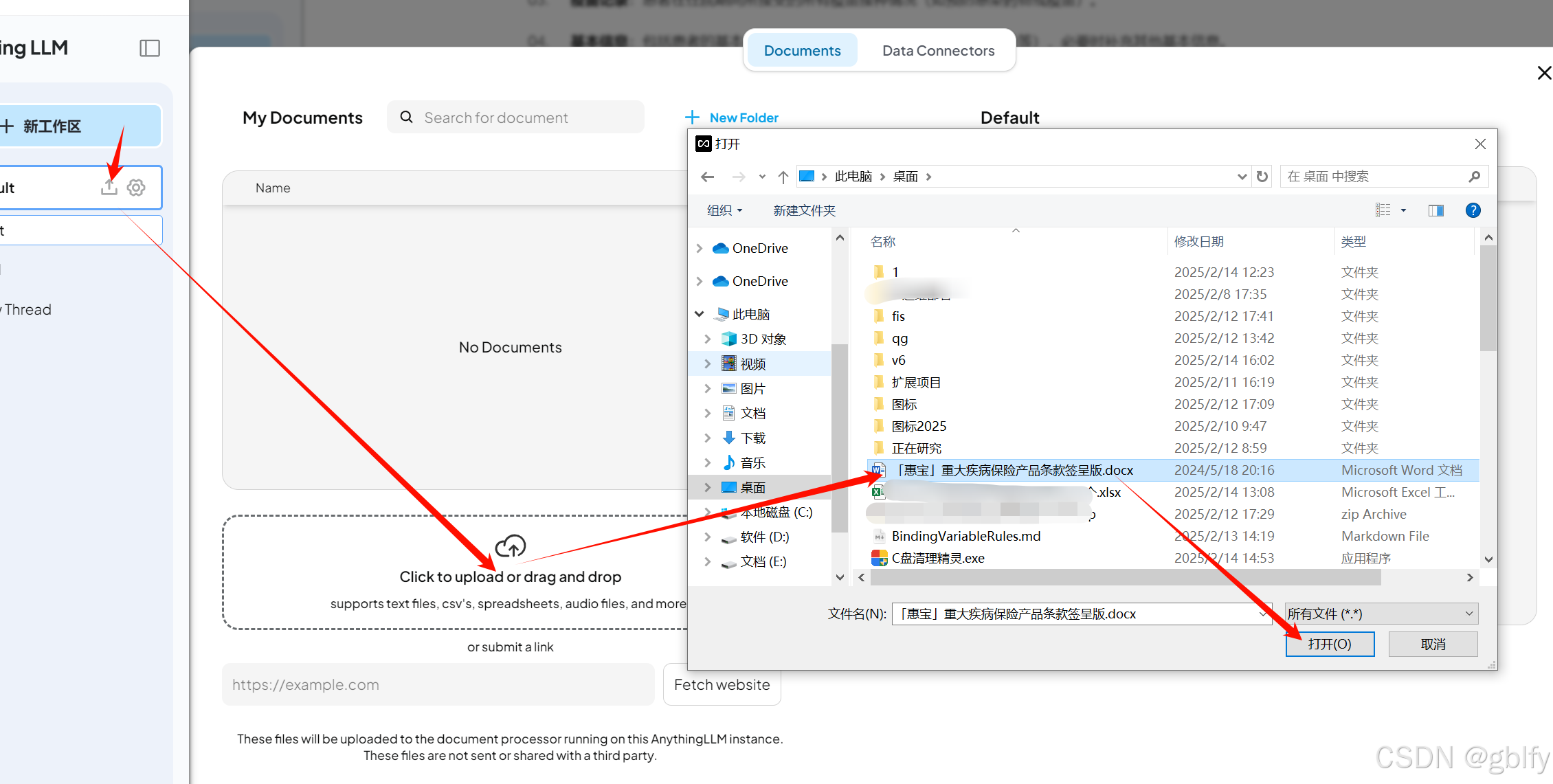
3.2. 文档向量化
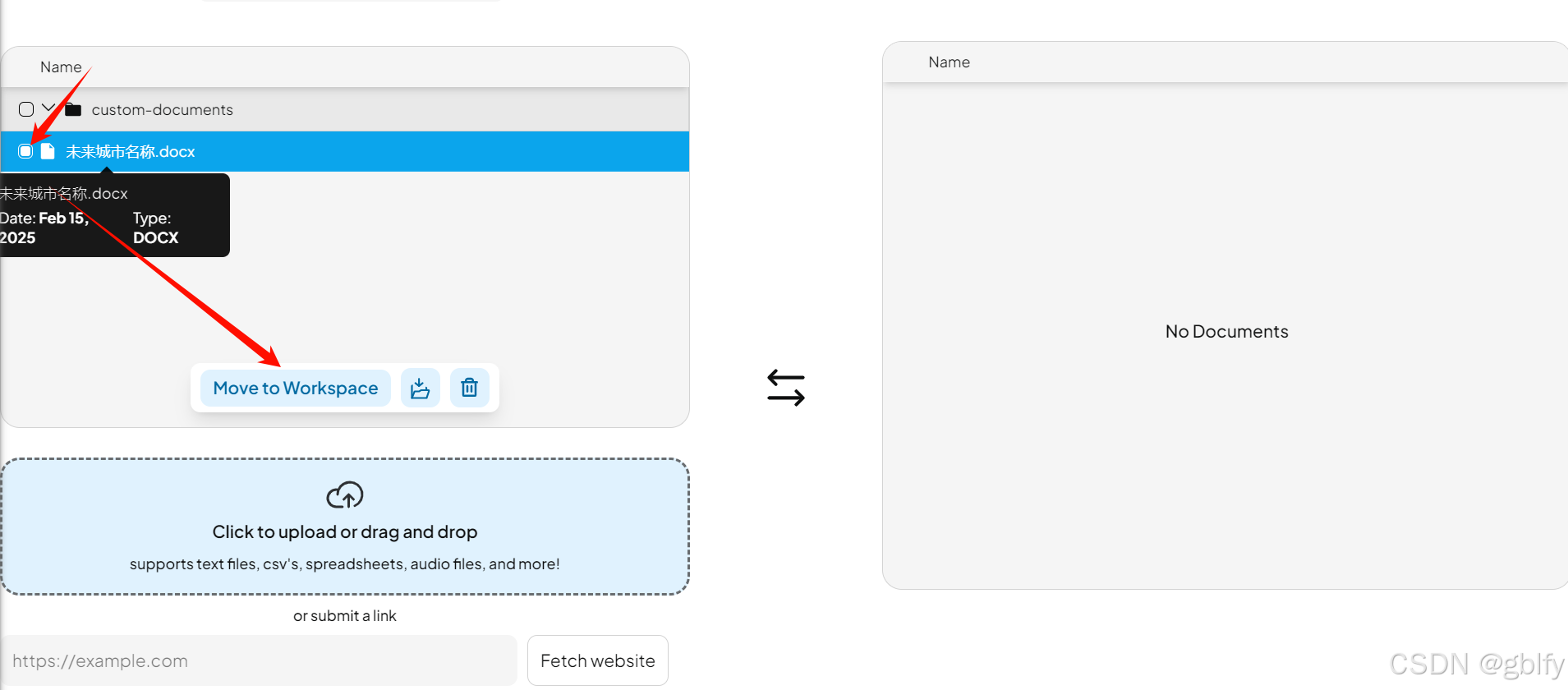
选择全选,点击Move to Workspace文档就会出现在右边的工作区文档区域
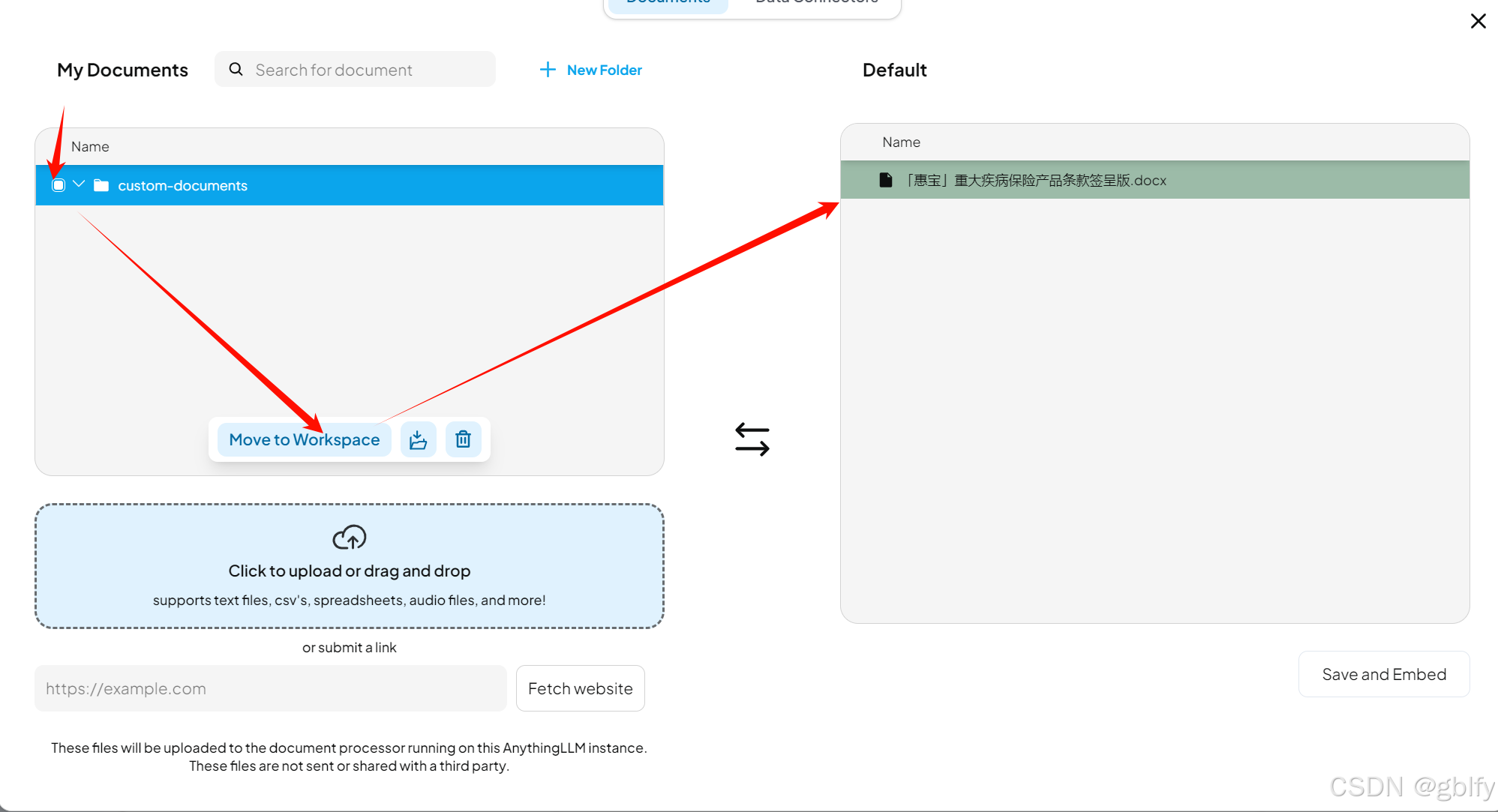
紧接着我们点击Save and Embed,把它们保存起来
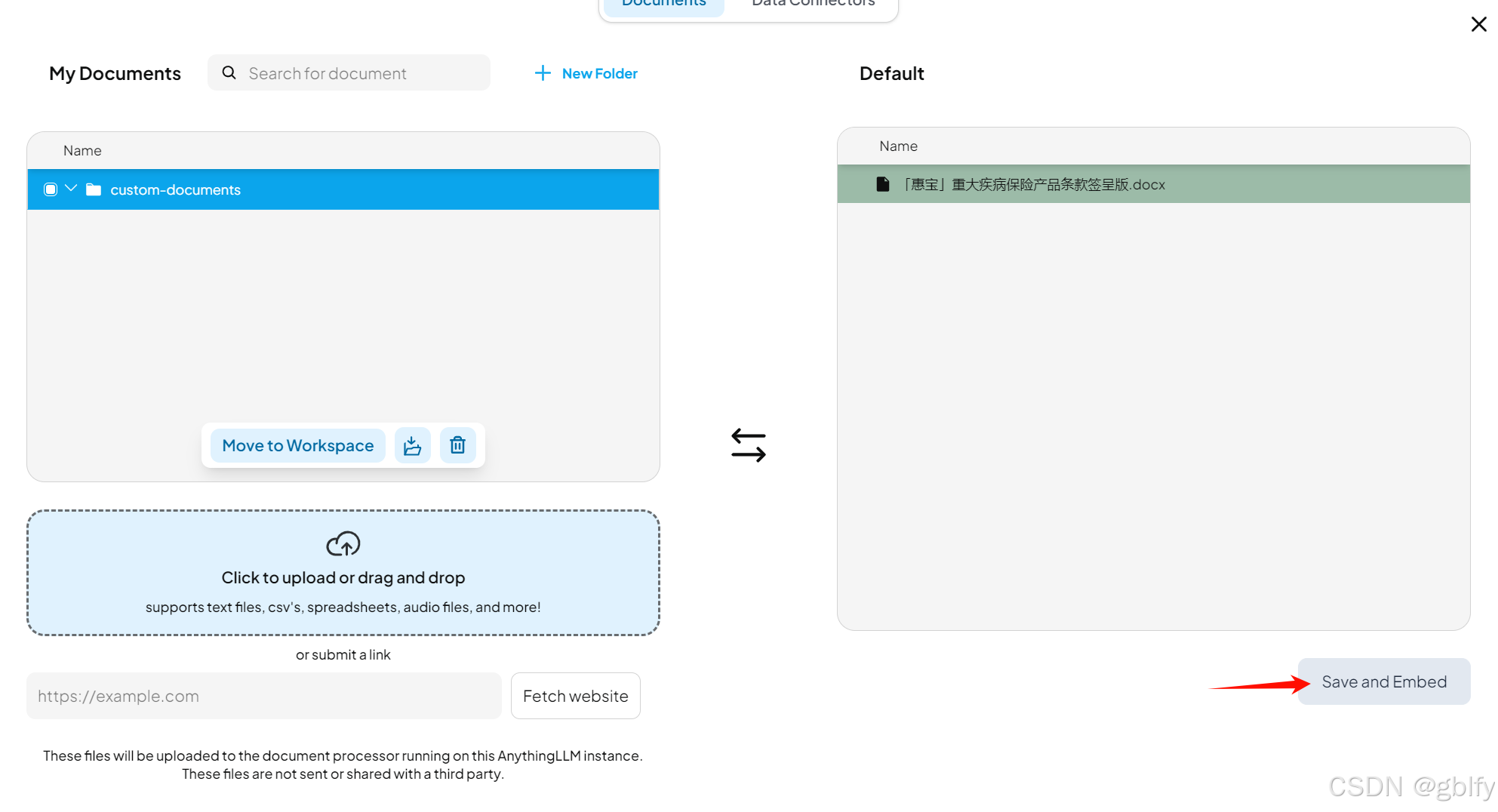
3.3. DeepSeek + 知识库知识体验
然后我们回来再把前面的问题一遍
申领重大疾病保险金时,应提供什么文件?
答案基本正确。
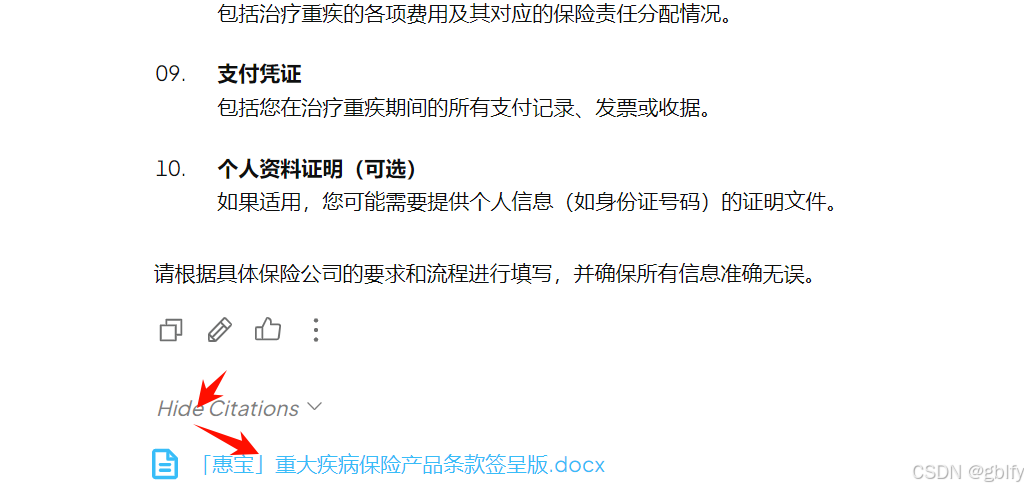
我们,点击下方的Show Citations,之后就可以发现DeepSeek所参考的文档列表

四、多工作区管理
我们在AnythingLLM里面可以定义多个工作区,每个工作区都有自己上传的文档,聊天模式等,彼此之间互相隔离。
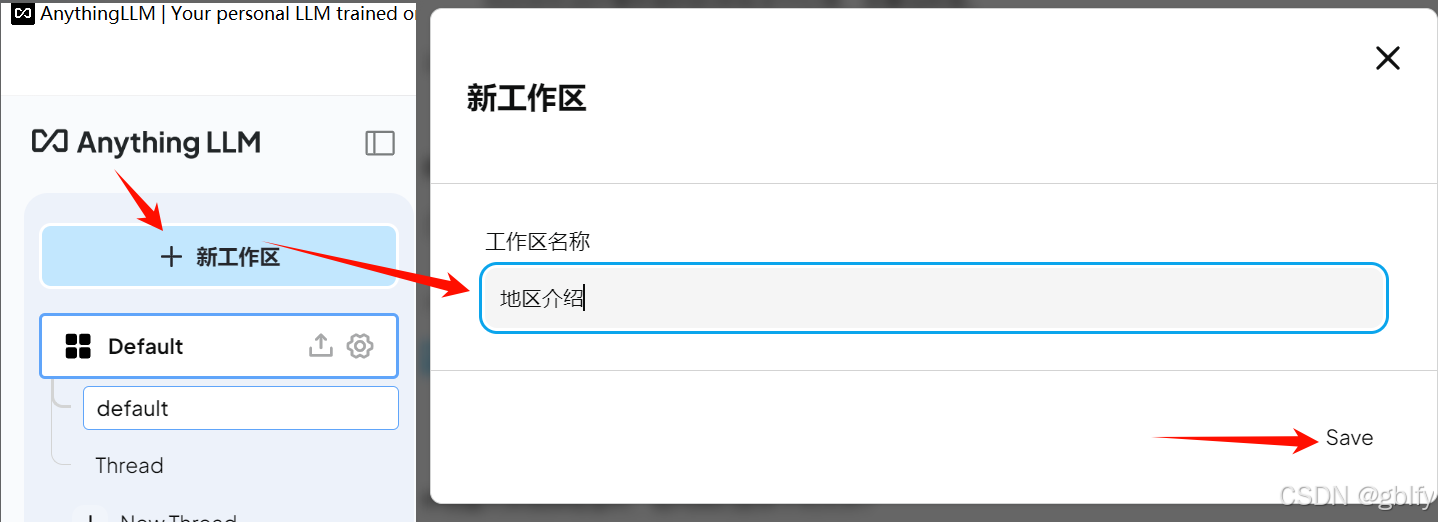
4.1. 创建工作区
比如我们可以创建名为地区介绍的工作区
4.2. 设置聊天模式
同样,我把它的聊天模式设为查询
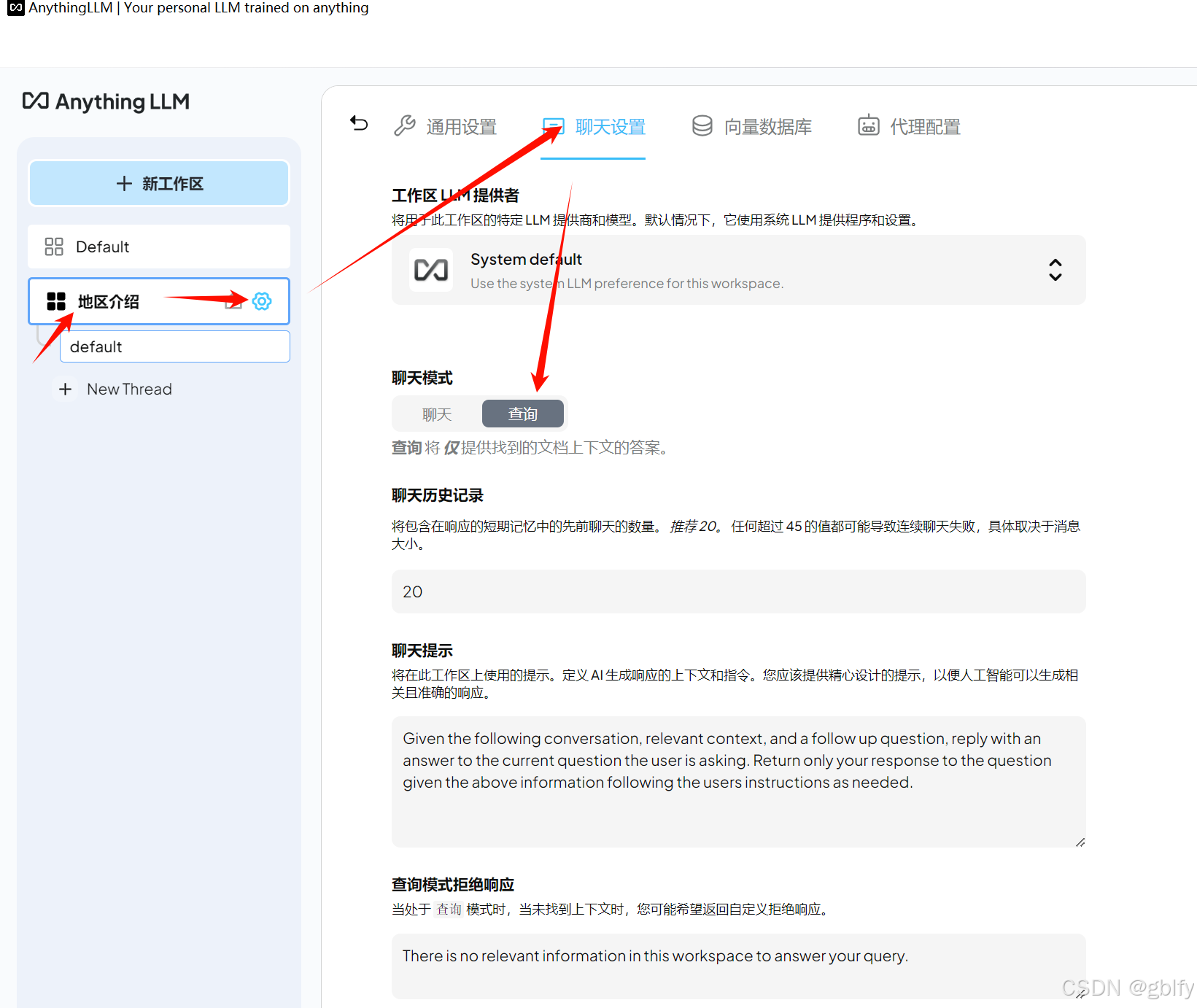
4.3. 验证工作区之间是否隔离
问一下以前的问题
申领重大疾病保险金时,应提供什么文件?
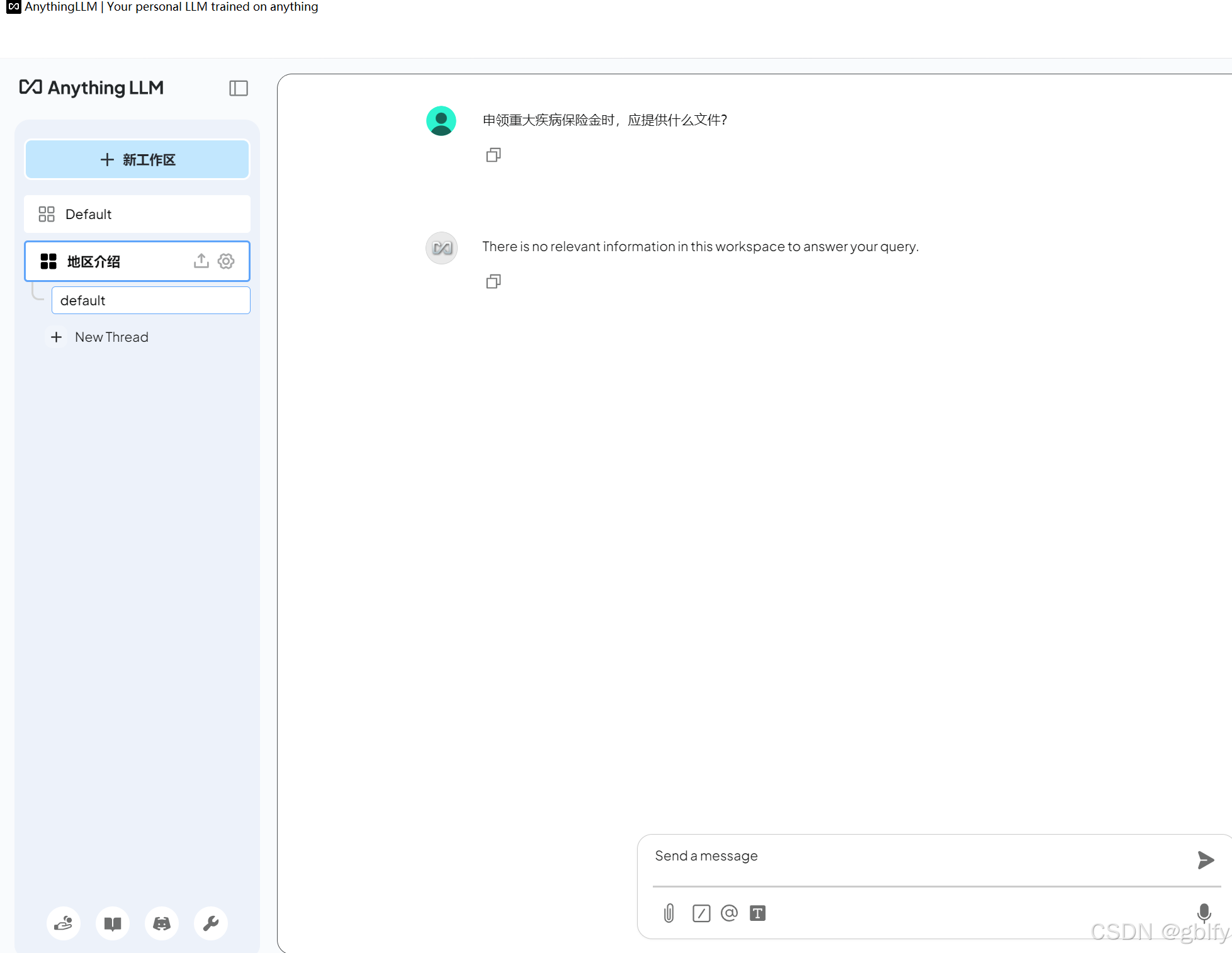
回答的答案都是没有信息的。可以看出这两个工作区的文档确实是互相隔离的。
4.4. 上传文档
下面我们往这个新的工作区里面上传一个文档
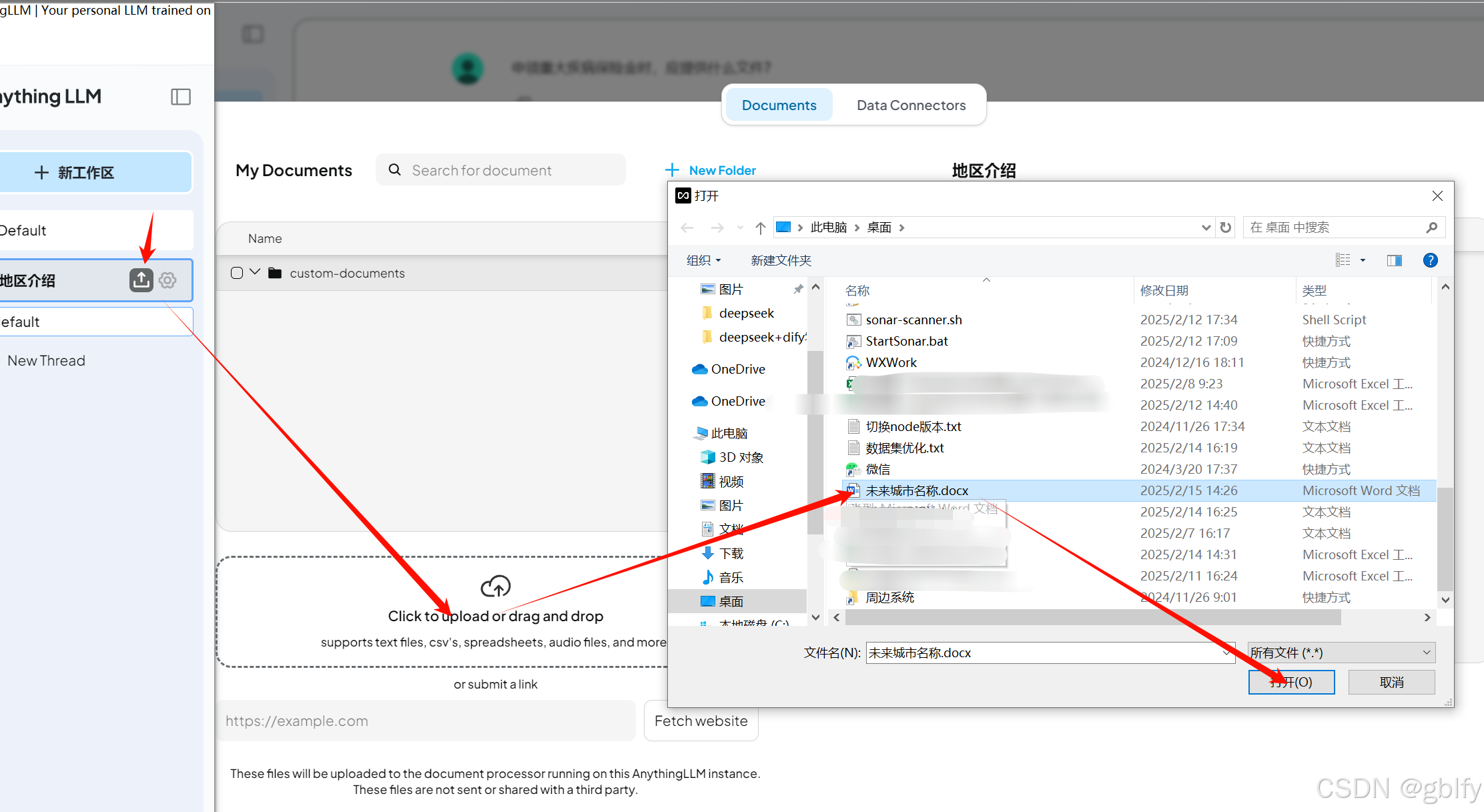
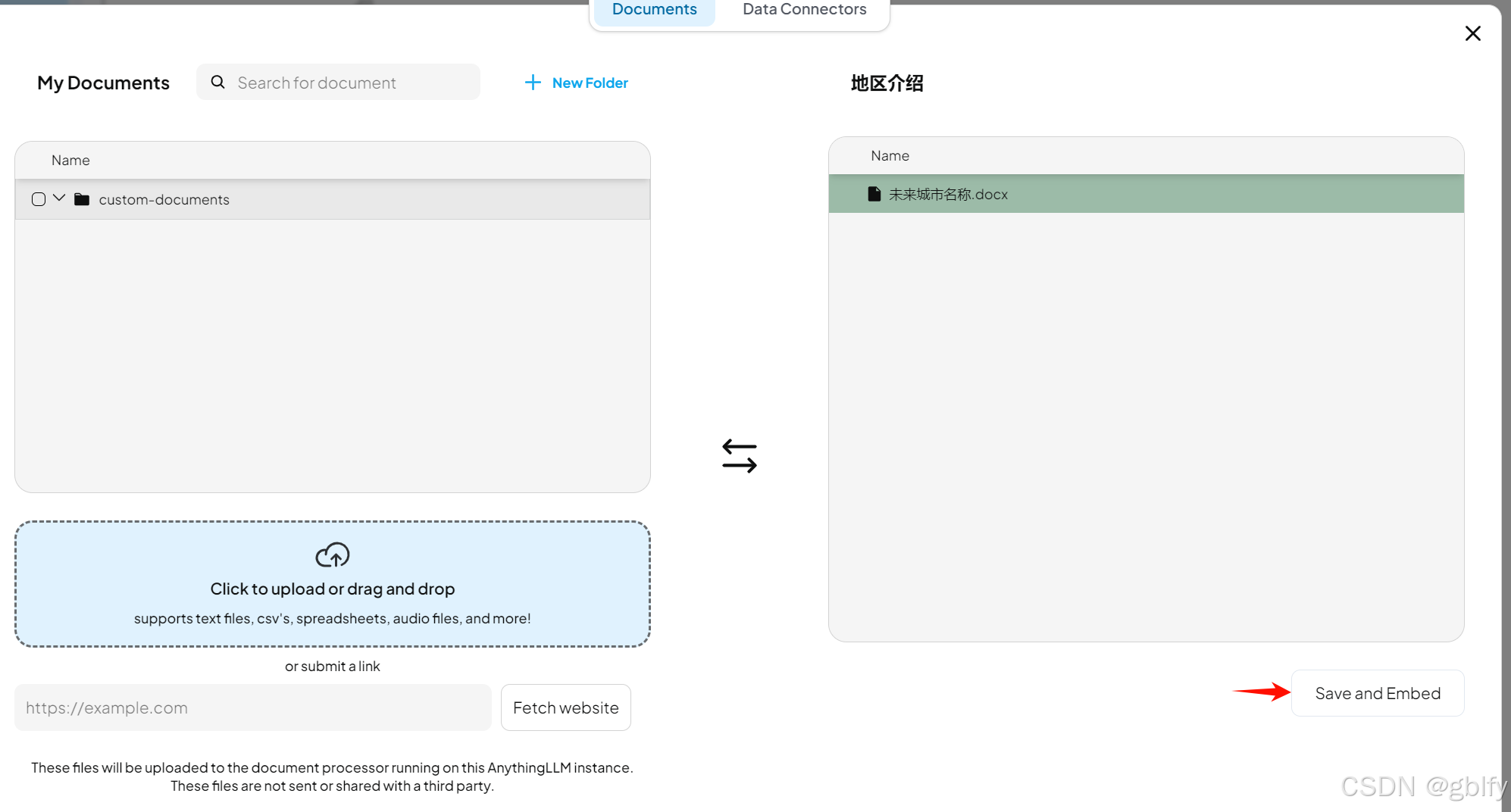
4.5. 测试知识库效果
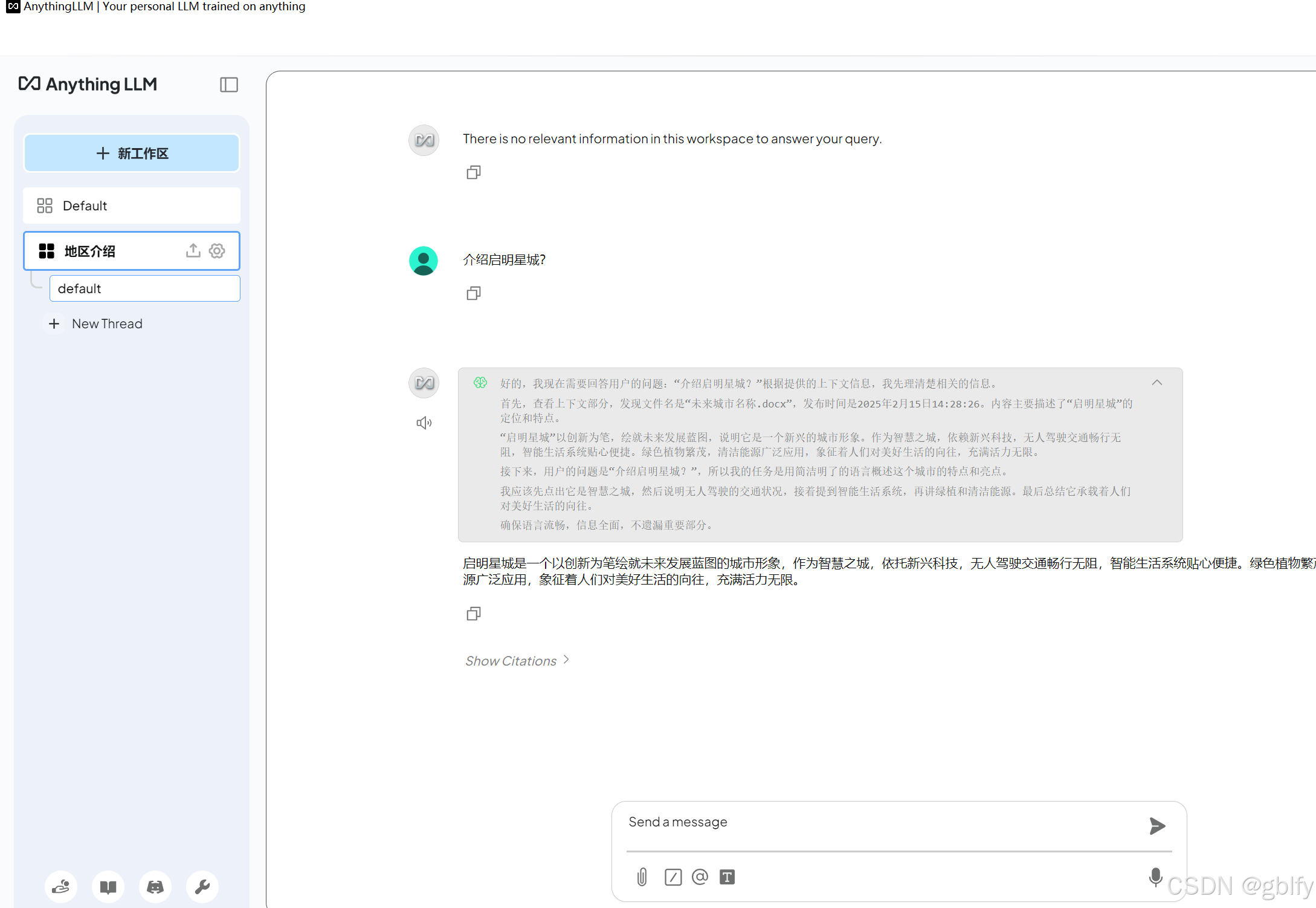

4.6. 结果评估
从上面回答,答案符合预期。
五、AnythingLLM 接入DeepSeek R1(在线)
5.1. 注册DeepSeek账号
①先去官网注册账号:https://platform.deepseek.com/sign_in

5.2. 创建API密钥,并复制
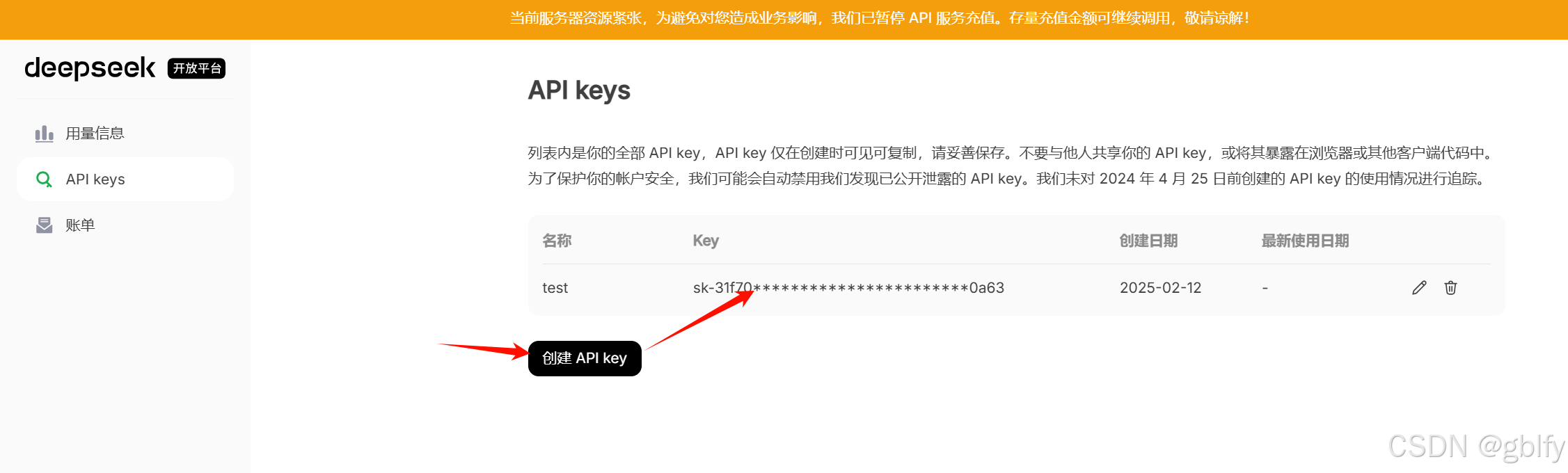
AnythingLLM支持直接调用DeepSeek官方提供的API接口。
5.3. 修改默认模型配置
在工作区右侧点击设置,选择聊天设置,可以更改LLM模型。
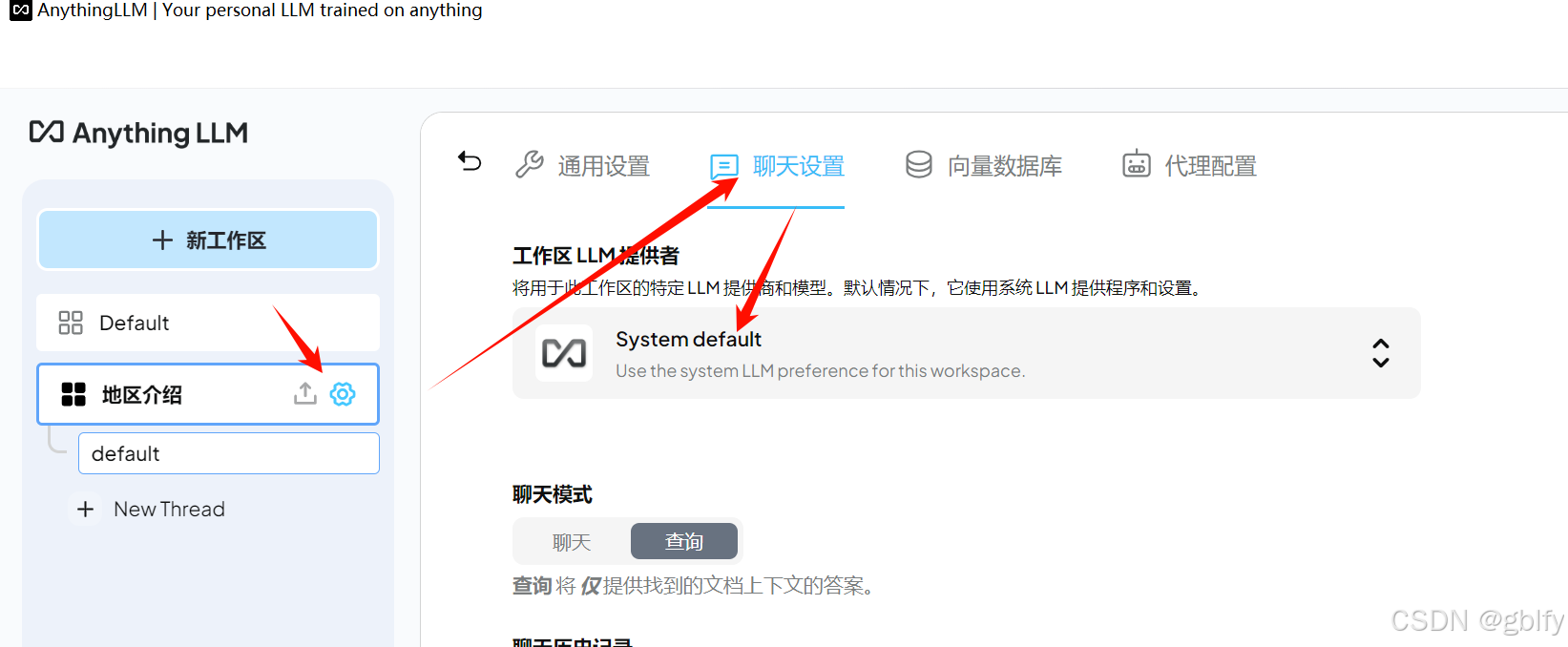
选择DeepSeek,输入API Key,选择DeepSeek R1模型。
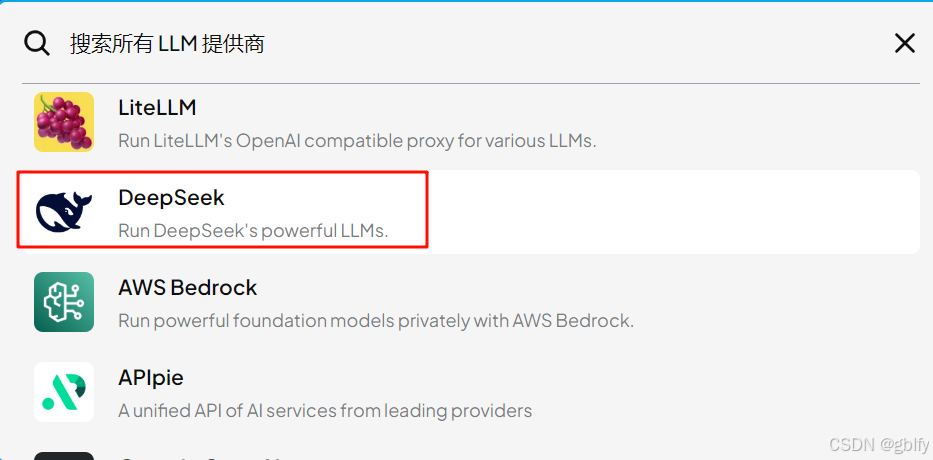
5.4. 填入API密钥
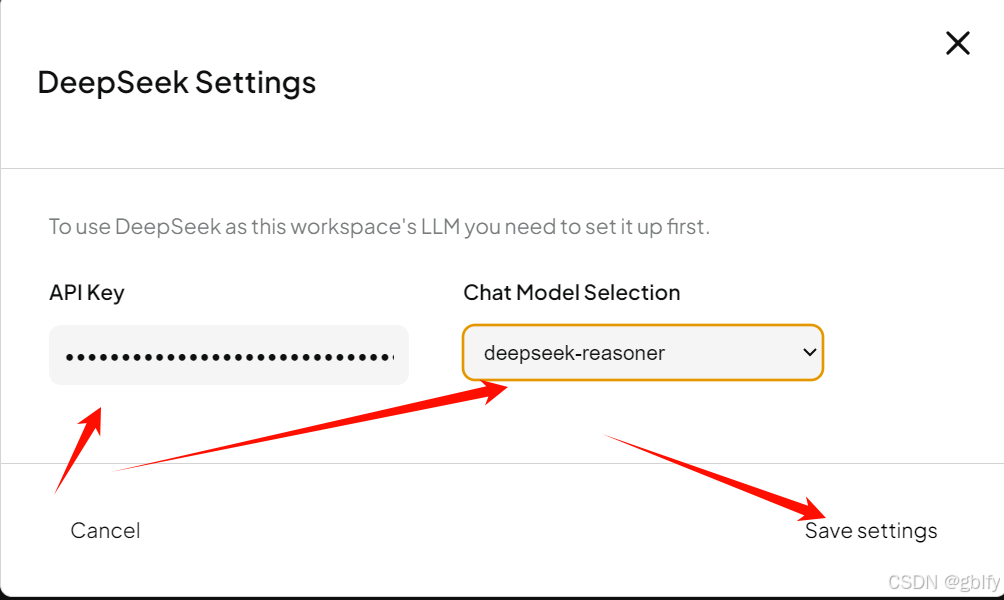
保存更新
点击最后更新工作区后就可以享受官方提供的大模型服务了,只是调用的模型变为官方API接口。
5.5. 体验DeepSeek 模型服务
略
看到这里,你是否发现AI私有化部署并没有想象中复杂?其实技术平权化的浪潮早已到来,重要的是勇敢迈出第一步。
毕竟,当技术门槛不复存在,唯一限制我们的,就只剩下想象力。
记住,每个科技达人都是从点击『安装』按钮开始的!
希望本文能帮助你迈出第一步,探索本地 AI 的无限可能。如果你在部署过程中遇到任何问题,欢迎在评论区留言交流!


















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











