









使用spark进行文件过滤
ps:分隔线前的内容为4月8日更新
已经将代码整理好上传到github上面
注意: 本博客发布的时候所用的spark版本是1.6版本
上传到github上面使用的spark版本是2.4版本(与时俱进)
所以部分测试结果稍有差别,这是spark版本(源码不同)导致的
但是实现方式是一样的, 博客代码和github代码均已经过测试,请放心使用!
在使用spark的很多情形下, 我们需要计算某个目录的数据.
但这个文件夹下面并不是所有的文件都是我们想要计算的
比如 : 对于某一天的数据,我们只想计算其中的几个小时,这个时候就需要把剩下的数据过滤掉
更坏的一种情形 : 对于那些正在copy(还没有完成),或者是.tmp临时文件,
程序在读取的过程中,文件发生变化已经复制完成或者被删除,都会导致程序出错而停掉
为了避免上述问题的出现, 我们就需要对 输入目录下的文件进行过滤:
即保证我们textFile的时候, 只读取那些我们想要的数据.
1.基本操作
获取到spark的context,代码如下 :
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark.fileFilter");
sparkConf.setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
2. 关键操作
1. 通过spark的context得到hadoop的configuration,并对hadoop的conf进行设置
代码如下 :
Configuration conf = jsc.hadoopConfiguration(); //通过spark上下文获取到hadoop的配置
conf.set("fs.defaultFS", "hdfs://192.168.1.31:9000");
conf.set("mapreduce.input.pathFilter.class", "cn.mastercom.bigdata.FileFilter"); // 设置过滤文件的类,这是关键类!!
2. 过滤类FileFilter的写法
关键点 : 实现PathFilter接口,重写里面的accept方法
一个简单的测试demo如下 :
package cn.mastercom.bigdata;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
/**
* 输入路径的文件过滤
* 过滤掉临时文件和正在复制的文件
* @author xmr
*
*/
public class FileFilter implements PathFilter
{
@Override
public boolean accept(Path path) {
String tmpStr = path.getName();
if(tmpStr.indexOf(".tmp") >= 0)
{
return false;
}
else if(tmpStr.indexOf("_COPYING_") >= 0)
{
return false;
}
else
{
return true;
}
}
}
3. 读取目录(文件), 进行rdd操作,输出结果
经过以上设置,使用spark对输出目录的文件进行过滤的功能就已经实现了!
接下来的rdd操作,就只会针对那些没有被过滤掉的文件了!!
具体的执行又分为以下几种情况 :(测试进行的rdd操作为最简单的map,直接将输入的结果输出出来)
1. 直接读取被过滤掉的文件(.tmp文件或者是正在复制的文件)
举例 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark/part-00003.tmp");
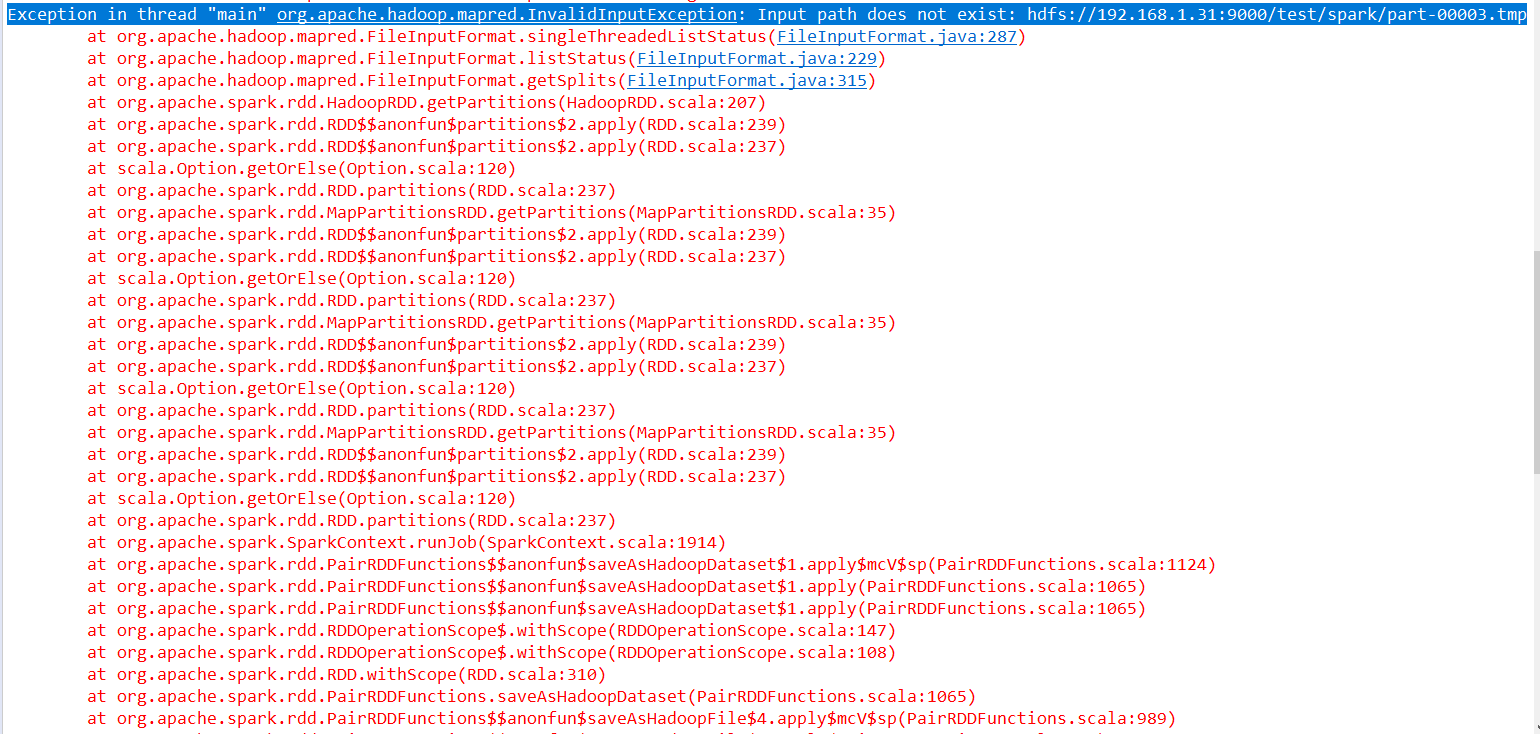
这种情况下会抛出文件不存在的异常 :
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException:
Input path does not exist: hdfs://192.168.1.31:9000/test/spark/part-00003.tmp
详细报错情况如下图 : !!
但是这个文件在hdfs上面命名是存在的,为什么会碰到这个问题呢? 去源码里面看,发现代码如下 :
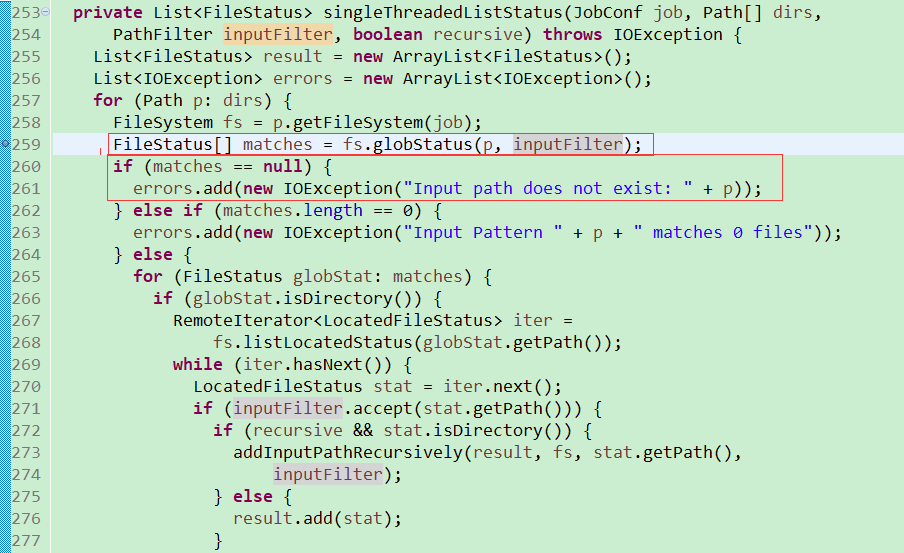
红框标注的 p ,就是我们传入的path, inputFilter就是我们FileFilter里面设置的文件过滤
而这个文件刚好在我们的过滤范围内,globstatus就会返回一个空值
在matches是一个空值的情况下,就会抛出 : Input path does not exist: 的异常
2. 读取正常文件(不在过滤的范围内)
执行情况与正常执行的spark程序相同,不再赘述
3. 读取一个全部都是要被过滤掉文件的文件夹
举例 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark");
// 这个文件夹下所有的文件都是.tmp文件或者是_COPYING_文件
这种情形下虽然没有任何的结果输出出来(因为所有的文件都被过滤掉)
但是也并没有抛出 Input path does not exist: 的异常,这是为什么呢?
原因 : 我们的Filter过滤, 过滤掉的是这个目录下面的所有文件
但是这个文件夹,对于框架来说,确实是存在的,所以才不会报错
如果我们换一种写法 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark/*"); // 读取这个文件夹下面全部的文件
这种情况下就会有错误抛出啦!
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input Pattern hdfs://192.168.1.31:9000/test/spark/* matches 0 files
详细报错信息如下:!
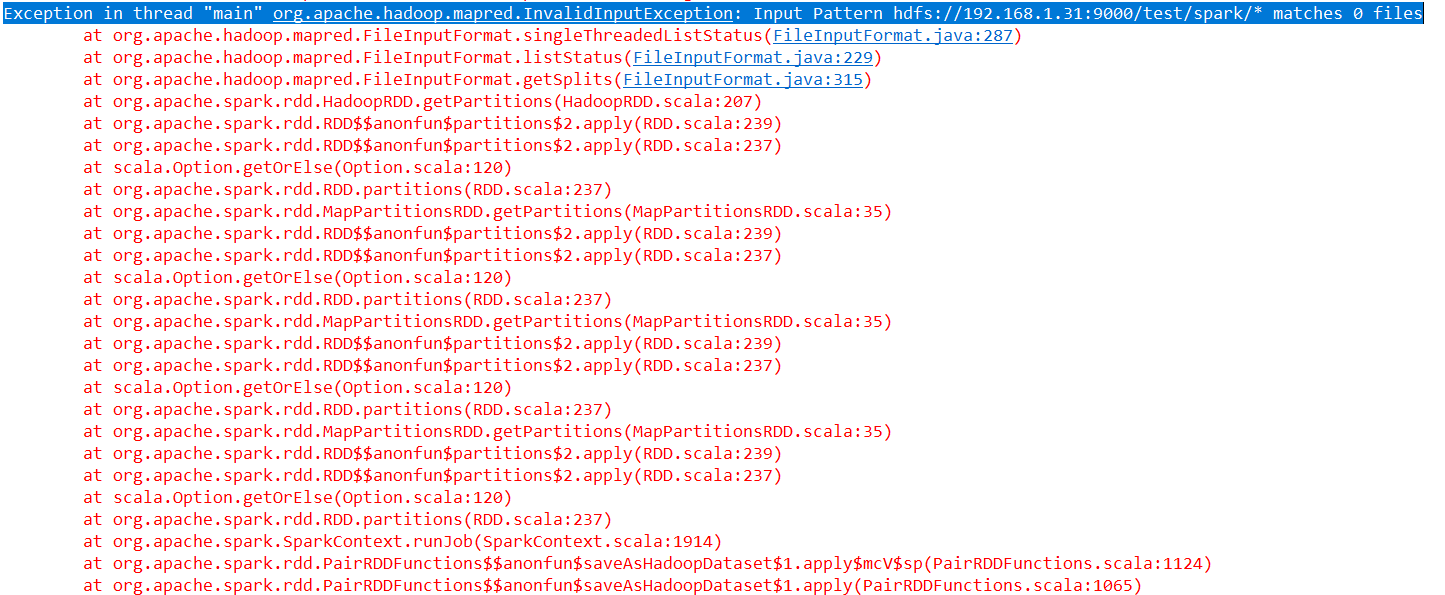
这错误就是说 : 这个目录下没有文件匹配~
同样的目的,换一种写法,结果就截然不同,还是挺奇妙的吧!!
4. 读取一个不全都是要被过滤掉文件的文件夹
结果 : 符合过滤条件的文件被过滤掉,其余的文件正常运算跑出结果
总结 : spark的文件过滤最关键的还是得到hadoop的configuration
并且对这个configuration进行设置!
在读取文件的时候,框架就会自动在最合适的时候进行文件的过滤~
hadoop,spark还是很强大的QAQ!















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









