






Query Expansion with Locally-Trained Word Embeddings
word embedding
word2vec是一种语言模型,可以通过对数据集训练语言模型,将关键词定量化为词向量,实现关键词的定量度量。在这里不做详细赘述。
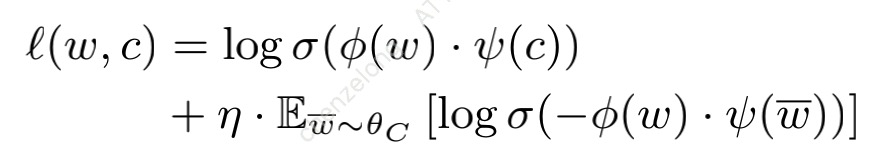
该公式表示词向量训练过程中在上下文为“c”的情况下,能预测出单词“w”的损失。
通过word2vec对词向量化非常依赖于文本数据集,作者通过实验证明了同一个单词“cut”在通用数据集和是由相关数据集中的近义词完全不同。因此在通过word2vec来寻找与搜索词相关的文本时,可以考虑在某些特定的语料上对搜索词和搜索相关的文本进行词向量训练。
loacl word embedding
作者通过证明了使用通用文章来训练词向量的不足,自然而然就引出了本文的中心-“为了训练指定主题的语言模型,需要对指定主题的语料进行词向量训练(我理解的是,与搜索词及其相关的文本;这么做是为了便于搜索词和文本中的单词的匹配)”
作者通过KL散度来衡量搜索query和文本d之间的匹配程度。公式如下所示,其中pq(w)表示在搜索query的上下文下预测出单词w的概率,pd(w)表示在文本d的上下文下预测出单词w的概率。(在这里的单词w,我没读清楚指的是query中的单词还是文本d中的单词)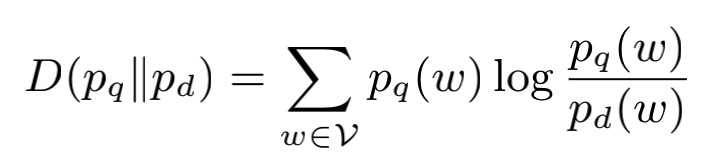
KL散度表示的就是概率 pq 与概率 pd 之间的差异,很显然,散度越小,说明 概率 pq 与概率 pd 之间越接近。
将上述公式算出来的结果作为query和document之间匹配程度的得分,如果得分越小,说明越匹配。
对所有候选document计算得分后归一化,即可进行匹配度排序。
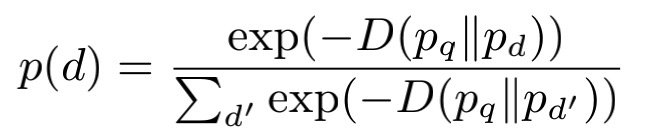
query expansion with word embedding
当搜索q存在已知的搜索扩展q+时,如何利用搜索扩展q+来帮助检索到更匹配的文本d呢?用以下公式将q和q+统一处理。
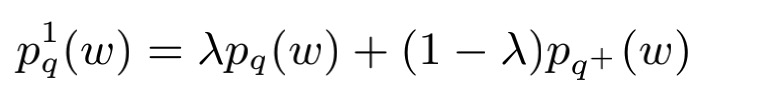















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









