







作者:林俊旸(阿里巴巴 多模态&NLP)
编辑:AI椰青
正值前几天发布Qwen2-VL,大家应该在我们的博客或者各个公众号看到我们模型的表现,并且看到我们开源了Qwen2-VL-7B和Qwen2-VL-2B以及推出了Qwen2-VL-72B的API。如果你还没看过,请点击下面几个链接:
Blog:https://qwenlm.github.io/blog/qwen2-vl/
GitHub:https://github.com/QwenLM/Qwen2-VL
HF:https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
ModelScope:https://modelscope.cn/organization/qwen?tab=model
博客已经包含大部分技术内容了。在这个系列里面,我打算多唠一唠。平时写作时间有限,这次计划分几篇写。第一篇会讲讲效果和例子,第二篇讲讲技术方案设计以及为什么我们会选择这么做,第三篇就随便做点补充。ok here we go!
Qwen2-VL
先说下这次Qwen2-VL的几个“卖点”(好的我就是个带货主播)。
基础能力提升
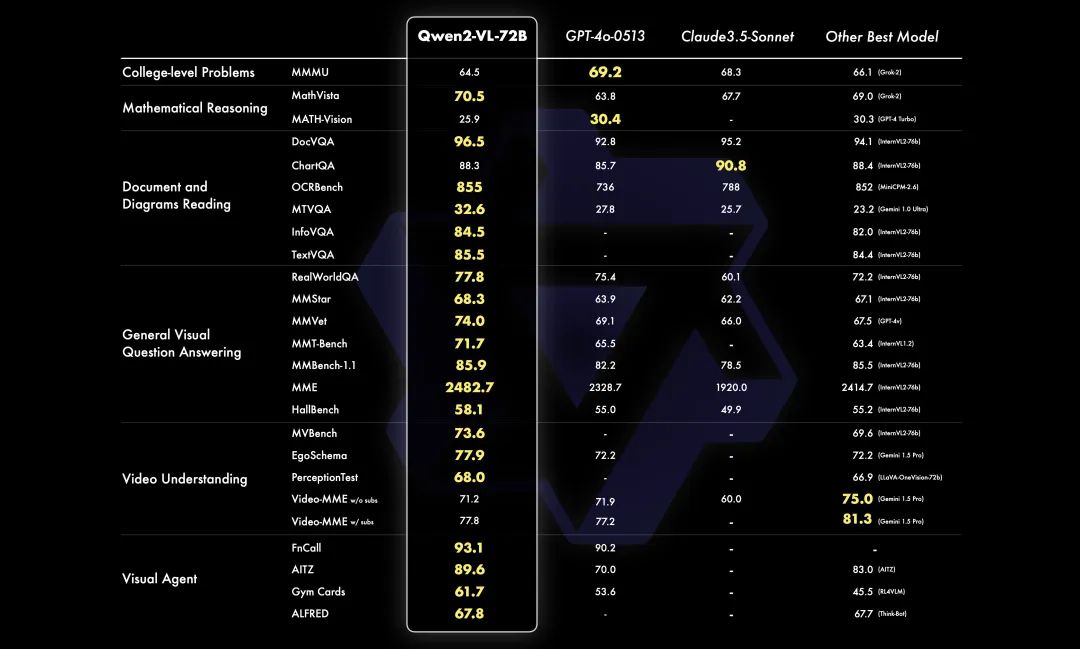
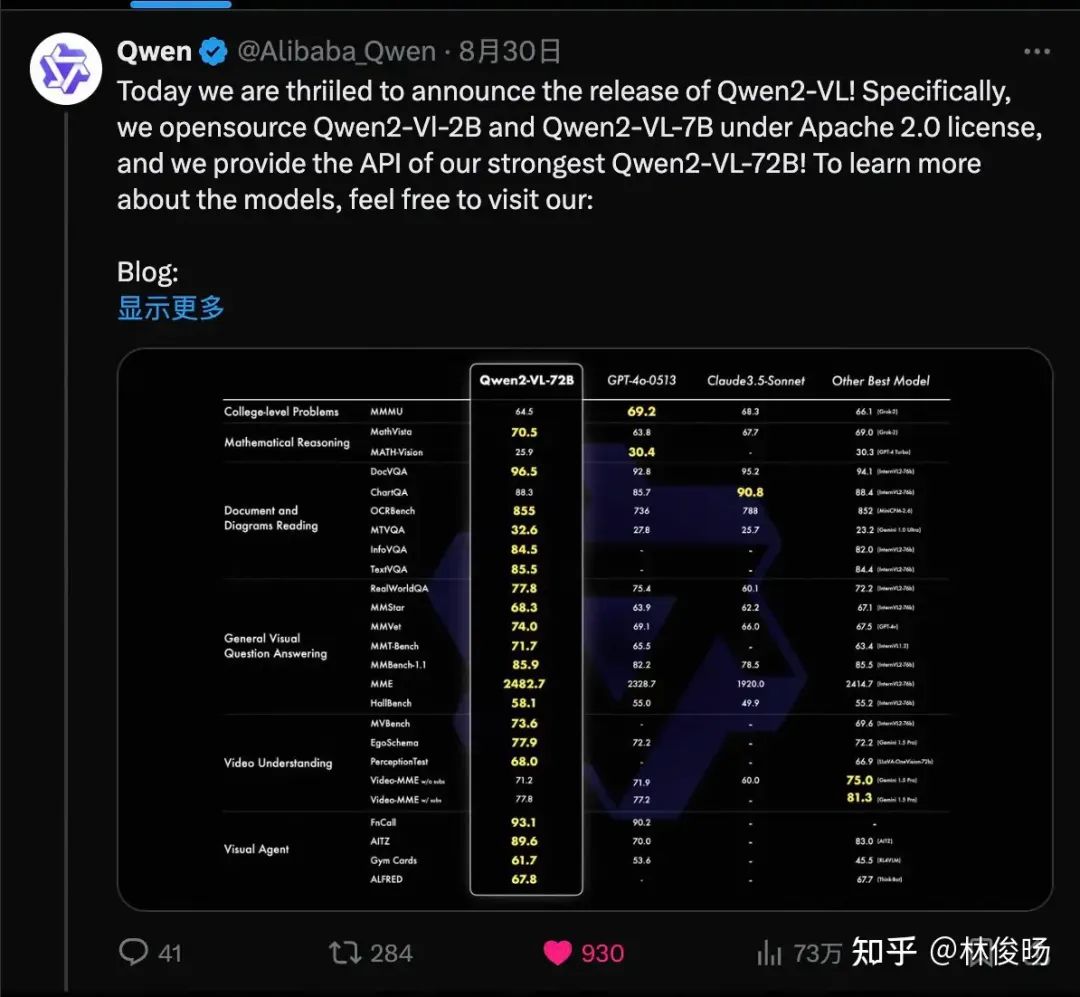
相比此前的Qwen-VL-Max (如果你不知道它我也不怪你毕竟闭源,也许你只记得初代7B的 Qwen-VL ),最大的卖点其实就是基础能力的大幅提升。也许大家总是希望有更多从零到一的新能力冲击,但说实话,对我们来说,最重要的事情就是基础能力能真正意义上一个台阶。先来看看本次主打的最强的Qwen2-VL-72B的表现。(BTW 这个图的风格算是我们团队的设计师(主业搞设计副业训模型)辛苦原创, Qwen2 就是用的这个风格的图,这次 Qwen2-VL 给字体整黄了。俺也不知道为什么俺也不敢问。)
 Qwen2-VL-72B
Qwen2-VL-72B
多个评测数据集上无惧GPT-4o,主要的文档理解、OCR和VQA的评测上面基本都能超过它不少,当然像MMMU这种特别难的,我们也是尽力了,64.5分之后实在搞不上去了估计还是LLM不够强的原因。我整体感觉确实模型质量还可以,当然出于“狗头保命”,我们的同学看了量子位的帖子之后转发都要来一句“还是有差距”之类的话哈哈。然后我在直播上轻描淡写,主持人就直接点我“哥,说重点,你就说,你们超越了GPT-4o!”
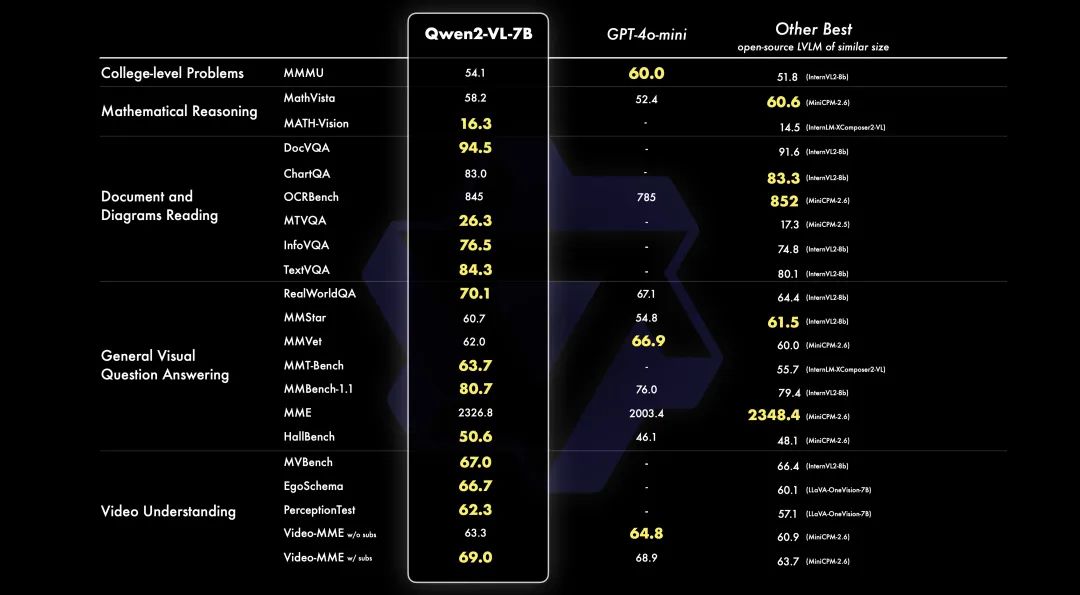
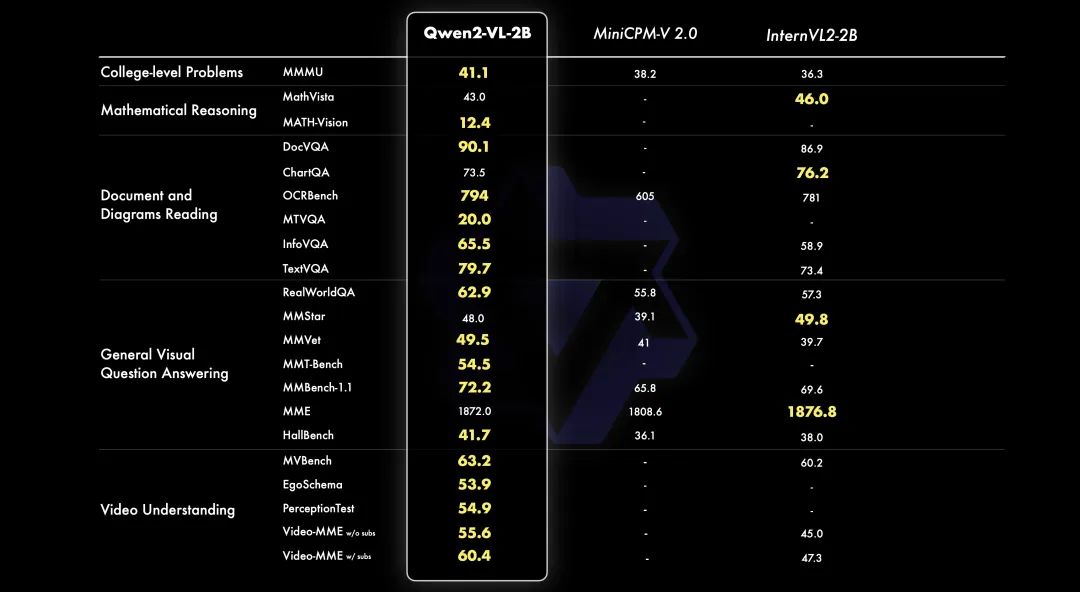
另外还开源了7B和2B两个模型,7B是一个大家比较常玩的size,就属于标配开源了。2B算是我们第一次试水小模型,暂时看起来小VL模型能做一些简单任务,也许未来在端上有发展空间。跑分如下我就不赘述了,基本都是市面上最强的不管开源还是闭源的都对比了。
7B模型对比
小模型对比
跑分仅供参考,跑分也就算是做 VL 模型的一个敲门砖吧。接下来我们说下还有新的特性。
视频支持
首先,本次我们增加了对视频的支持,基本20分钟以上的视频传入模型让模型做视频理解,比如视频问答、视频对话等,应对起来都还OK。这主要是因为Qwen2-VL这次支持的context length已经达到128K token。未来我们还会支持更长的序列,这样能够更好地支持长视频理解。下面是一个视频理解的例子(虽然视频不是很长)
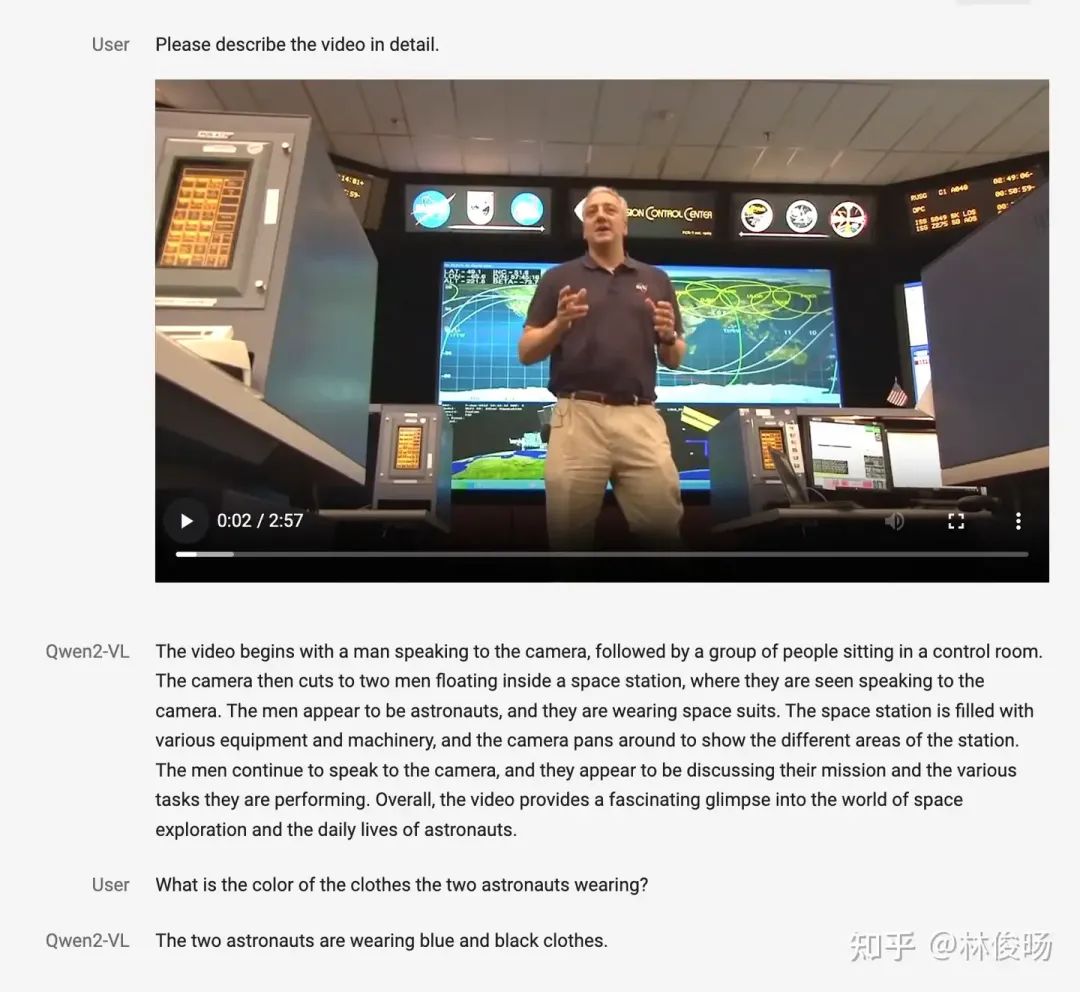
这个比较中规中矩,我比较喜欢这个demo。当时几个哥做了个实时摄像头录像,然后跟VL模型交互,不过最后考虑到用户打字速度总是会过慢,以及产品体验的问题等没放出来。下面是一个录屏的例子:
其实我自己玩的时候当时对着摄像头确实一时半会不知道该干点啥。有什么好点子请赶紧告诉我!
Visual Agent能力
LLM 的 Agent 已经被广泛讨论了,结合function call、tool use 以及 planning 的能力,基于 LLM 的 Agent 相比原始 LLM 更能针对性地理解需求和解决相对复杂的任务,更重要的是 Agent 能够跟环境实现交互。但当前 Agent 没办法解决的问题是 LLM 不具备视觉信息的理解能力,而与环境的交互过程中,Agent实际接收的信息就是多模态的。从这一个角度上说,使用 VL 模型来做 Agent 可能才是未来的方向。这一次,我们比较大幅度地提升了 Qwen2-VL 的 function call 以及 Agent 能力。除了上述的一些评测指标表明模型的能力外,下面我们通过一些例子来解释 Visual Agent 大概达到什么水平。
我们先看最简单的case,即让模型根据视觉信息和指令,调用插件回答问题。
这种主要考验的其实是 VL 模型对 图像中的文字的理解,并在此理解基础上结合工具调用。首先我们上传了一个航班信息的截图,用户的指令是询问到达时间以及到达地点的天气。到达时间这种相对简单,VL 模型只要理解了图像中的文字,找到到达时间即可。但是到达城市的天气,除了找到到达城市是什么以外,还得通过插件去查询当地的天气。目前看起来做一些简单的插件调用问题不大。
再更进一步,比如我们想让模型直接写代码和执行,那么我们可以考虑今天大家常说的 code interpreter 的形式。可以看看这个例子:
这个例子里,我们看到一张流程图的图片,而我们希望模型根据这个架构图写出可执行的代码。我很喜欢这个llama 3的架构图(不过它这个我觉得应该叫流程图hh),然后指挥模型写出相应代码。可以看到模型写的基本逻辑都是对的,而它也不知道具体每个模块长什么样,就直接偷懒 pass 了(虽然我觉得你就算告诉它长什么样它也偷懒 pass),但可以看到模型理解流程图架构图然后写出可用的 python 代码,简单的场景还是可以对付的。
那么接下来来到更复杂更能被看作属于 Agent 领域的场景了。首先是操控 UI,这其实是形势比较简单的 Agent 任务了,但其实就这事能干清楚的模型也没几个。先看这个手机屏幕操作的小例子,其中左边是手机屏幕,右边是 Agent framework 每个 step 的状态,让大家看看这个 Agent 在干嘛。
可以看到,这个 Agent 就是一个手机屏幕前的你(没错你就是一个Agent!)。此时的你具备四种技能。一是点击,点击就是找到你想要点击的位置按下去,那么考验的是你找位置的能力。二是滑动,无非就是上下左右四个方向滑动的基本操作。三是 Home 键,不知道了咋整就整个退出来呗。四就是回车确认。然后我们收到一个任务,就是查询 San Diego 的好餐厅。
此时的你,看到邮件页面一脸蒙蔽,于是决定遇事不决点 Home 键回到快乐老家,看到了一堆App,想了一下觉得还是 Google Chrome 搜一搜比较靠谱,于是你找到了 Google Chrome 的所在位置 (也就是我们所说的bounding box)然后大力按下去,却来到了一个滑板的页面。你在搜索框点了一下发现不好使,你发现旁边有个X号,你决定点一下清除搜索框的内容,然后输入你的问题。于是你便能够查询到圣地亚哥的好餐厅了。
你找到心仪的餐厅,吃饱喝足以后,决定跟电脑打牌,休闲娱乐一下。于是你这个 Agent 开始了一场24点:
这个打牌也很简单,就是看着场上牌局形势决定要不要翻牌,让自己最接近21点,447的情况下感觉确实可以再抽一张,但爆牌的风险也不小吧。算了算了,不如我们来操控机械臂搬点东西(看起来更呆)。
整个操作其实就是一个起始位置和终止位置的判断,考验的还是模型的方位理解能力,可见其实 Visual Agent 即便和机器人结合也不会一个过于复杂的算法问题,但却实实在在地考验了模型的定位能力。
实话说,这次的模型的定位能力我们觉得提高的空间依然很大,我们会先把图像的定位做到足够好的基础上,进一步扩展到视频上,这样可以玩的东西就会更多。比如我们现在也能整出一些有趣的视频case:
这一块好玩的点很多,当然真正做到水平顶尖难度也极大。
不足之处
Qwen2-VL 整体质量还可以,但是具体到很多细节问题,还有比较多有待解决的问题,这里重点列出几个:
1.位置感还需要增强,Agent 才能真正意义做起来。这个上面也已经提到了
2.目前对人物、景点这类的识别还没做优化,所以容易产生一些奇怪的幻觉
3.指令理解能力还有比较大的提升空间。某种程度上 VL 的对齐也许比 LLM
更难,毕竟上下文包含了图像信息,注定是复杂了很多
4.数数能力还是相对较弱,尤其视频场景中的数数。看起来数数是一件对人
来说很简单的事情,但我们这些早年做 VQA 的,也许最能理解这破模型咋
数个数都数不明白!
未完待续
半夜写作确实有点难顶,过两天再写比较有意思的模型技术篇,以及一些内部的技术发展历程。Stay tuned!
啊对了,欢迎关注坤坤的官推,Qwen2-VL的推文已经 73 万阅读量了,能不能破百万就看各位看官了!
 ·················END·················
·················END·················
分享
收藏
点赞
在看















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









