









论文:SDC-Net: Video prediction using spatially-displaced convolution
地址1:https://link.springer.com/chapter/10.1007/978-3-030-01234-2_44
地址2:http://openaccess.thecvf.com/content_ECCV_2018/papers/Fitsum_Reda_SDC-Net_Video_prediction_ECCV_2018_paper.pdf
关键字:视频预测
简介
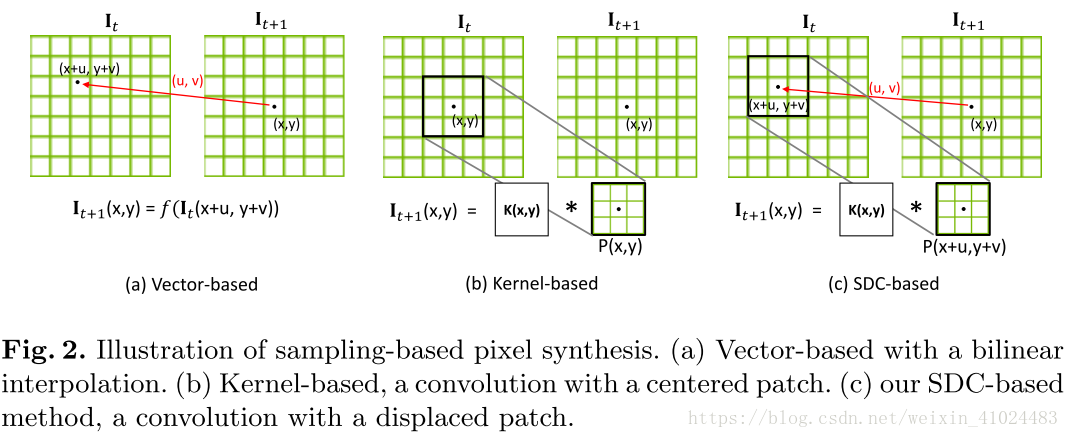
论文针对视频预测中的图像模糊问题,提出一种预测网络:将kernal-based与vector-based的预测方式相结合,既可以预测较大范围的运动(large motion),又可以避免斑点噪声(speckled noise)的影响,从而生成较为逼真的图像。
kernal-based:如图(a),优点是可以预测较大范围的运动,缺点是容易受到噪声斑点的影响;
vector-based:如图(b),优点是可以避免噪声斑点的影响,缺点是如果想预测较大范围的运动,就要求网络中卷积核非常大,从而使得参数数量过多,计算复杂;
SDCNet:如图©,结合了二者的优点,同时避免了各自的缺点
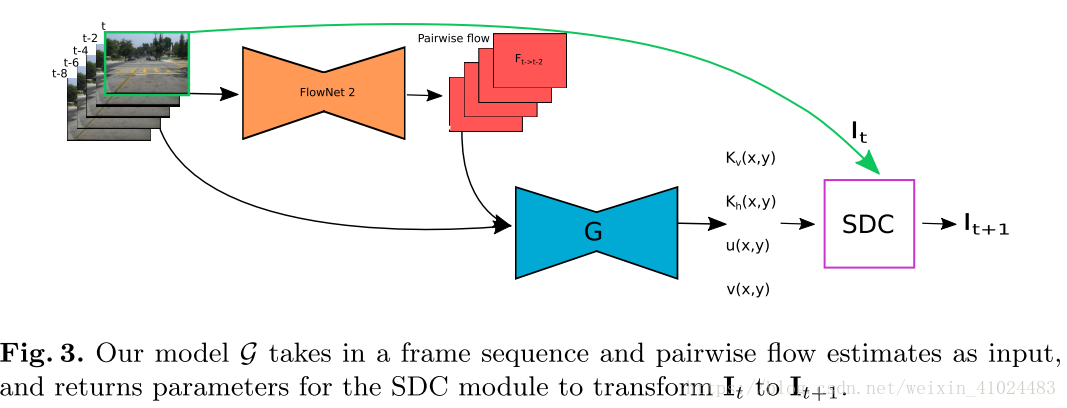
网络
- 将图像 I 1 : T I_{1:T} I1:T 送入FlowNet2中,得到光流 F;
- 将图像RGB通道与光流的两个通道级联,送入G网络,针对每一个像素生成对应的位移向量 (u, v) 和核向量 K h , K v K_h, K_v Kh,Kv;其中G是一个全卷积网络,包含 encoder 和 decoder;
- 将图像 I t I_t It 与 u , v , K h , K v u, v, K_h, K_v u,v,Kh,Kv 送入预测网络 SDCNet 中,预测得到下一帧图像; I t + 1 ( x , y ) = K ( x , y ) ∗ P t ( x + u , y + v ) I_{t+1}(x, y) = K(x, y) * P_t(x+u, y+v) It+1(x,y)=K(x,y)∗Pt(x+u,y+v)
注:1. 作者使用的光流预测网络FlowNet2是Ilg, E.等人提出的,而且是预先训好的,训练时未改变其权重;
2. 作者为了进一步压缩参数数量,用两个向量 K h , K v K_h, K_v Kh,Kv 合成卷积核;
代价函数
- I t + 1 I_{t+1} It+1 为预测输出, I t + 1 g I_{t+1}^g It+1g 为ground truth;
L 1 = ∣ ∣ I t + 1 − I t + 1 g ∣ ∣ 1 L_1 = || I_{t+1} - I_{t+1}^g ||_1 L1=∣∣It+1−It+1g∣∣1
- Ψ l ( I i ) \Psi_l(I_i) Ψl(Ii)是预训练好的ImageNet VGG-16中第 l 层 feature map, κ l \kappa_l κl 是归一化系数 1 / C l H l K l 1/C_lH_lK_l 1/ClHlKl(channel, height, width);
L p e r c e p t u a l = ∑ l = 1 L κ l ∣ ∣ Ψ l ( I t + 1 ) − Ψ l ( I t + 1 g ) ∣ ∣ 1 L_{perceptual} = \sum_{l=1}^L \kappa_l || \Psi_l(I_{t+1}) - \Psi_l(I_{t+1}^g) ||_1 Lperceptual=l=1∑Lκl∣∣Ψl(It+1)−Ψl(It+1g)∣∣1 L s t y l e = ∑ l = 1 L κ l ∣ ∣ ( Ψ l ( I t + 1 ) ) T ( Ψ l ( I t + 1 ) ) − ( Ψ l ( I t + 1 g ) ) T ( Ψ l ( I t + 1 g ) ) ∣ ∣ 1 L_{style} = \sum_{l=1}^L \kappa_l || (\Psi_l(I_{t+1}))^T(\Psi_l(I_{t+1})) - (\Psi_l(I_{t+1}^g))^T(\Psi_l(I_{t+1}^g)) ||_1 Lstyle=l=1∑Lκl∣∣(Ψl(It+1))T(Ψl(It+1))−(Ψl(It+1g))T(Ψl(It+1g))∣∣1
注:此处作者设置 L p e r c e p t u a l , L s t y l e L_{perceptual}, L_{style} Lperceptual,Lstyle的作用是什么?是为了使预测的图像有意义、从语义特征上更接近于ground truth?
- 作者定义了下面的损失函数用于 “初始化” 各个像素点的 kernal weight,在训练时用到可以加速训练,其中 1 < N / 2 > 1^{<N/2>} 1<N/2> 为 middle-one-hot vector;
L k e r n a l = ∑ x = 1 W ∑ y = 1 H ( ∣ ∣ K u ( x , y ) − 1 < N / 2 > ∣ ∣ 2 2 + ∣ ∣ K v ( x , y ) − 1 < N / 2 > ∣ ∣ 2 2 ) L_{kernal} = \sum_{x=1}^W \sum_{y=1}^H \left(||K_u(x, y) -1^{<N/2>}||_2^2 + ||K_v(x, y) -1^{<N/2>}||_2^2 \right) Lkernal=x=1∑Wy=1∑H(∣∣Ku(x,y)−1<N/2>∣∣22+∣∣Kv(x,y)−1<N/2>∣∣22)
- 整体loss为
L f i n e t u n e = ω l L 1 + ω s L s t y l e + ω p L p e r c e p t u a l L_{finetune} = \omega_l L_1 + \omega_s L_{style} + \omega_p L_{perceptual} Lfinetune=ωlL1+ωsLstyle+ωpLperceptual
训练过程
使用 Adam 优化, β 1 = 0.9 , β 2 = 0.999 \beta_1 = 0.9, \beta_2 = 0.999 β1=0.9,β2=0.999, 没有权重衰减。
- 首先用 L 1 L_1 L1 损失学习 (u, v) ,可以找到一个大致的方向(此时 K u , K v K_u, K_v Ku,Kv应该刚被初始化为middle-one-hot vector);
- 固定其他参数,用 L k e r n a l L_{kernal} Lkernal 损失来学习 K u , K v K_u, K_v Ku,Kv,以此初始化每个像素的kernal,使其为 middle-one-hot vectors;
- 使用 L 1 L_1 L1 损失同时学习 ( u , v ) , ( K u , K v ) (u, v), (K_u, K_v) (u,v),(Ku,Kv);
- 使用 L f i n e t u n e L_{finetune} Lfinetune 学习所有权重;
注:这里关于 L k e r n a l L_{kernal} Lkernal 有个疑问,作者这种定义方式不会使得最终训练结果 K u , K v K_u, K_v Ku,Kv 就是 1 < N / 2 > 1^{<N/2>} 1<N/2> 吗?或者说由于作者的初始化值就是 middle-one-hot vector,使得 L k e r n a l L_{kernal} Lkernal 一直为0?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









