






 本文详细介绍了池化在深度学习中的重要性,包括最大池化、平均池化、LP池化、自适应池化、分数阶最大池化以及反最大池化等。通过PyTorch示例展示了这些池化操作的实现和应用场景,强调了自定义池化层的重要性。
本文详细介绍了池化在深度学习中的重要性,包括最大池化、平均池化、LP池化、自适应池化、分数阶最大池化以及反最大池化等。通过PyTorch示例展示了这些池化操作的实现和应用场景,强调了自定义池化层的重要性。
参考文章1、一文弄懂各大池化Pooling操作 - 知乎 (zhihu.com)
2、池化(Pooling)的种类与具体用法——基于Pytorch-CSDN博客https://blog.csdn.net/weixin_60737527/article/details/127024456
1、基本原理
池化Pooling是卷积神经网络中常见的一种操作,Pooling层是模仿人的视觉系统对数据进行降维,其本质是降维。在卷积层之后,通过池化来降低卷积层输出的特征维度,减少网络参数和计算成本的同时,降低过拟合现象。
池化操作通常在卷积神经网络中使用,并且与卷积操作配合使用,可以起到调节数据维数,并且具有抑制噪声、降低信息冗余、降低模型计算量、防止过拟合等作用。池化没有可以学习的参数,所以某种程度上与激活函数较为相似,池化在一维或多维张量上的操作与卷积层也有很多相似之处。
池化操作最初是用来减小数据大小,使模型更容易训练,这个过程即为下采样(downsampling),这里可以称为下池化。随着之后的发展,池化也可以增加数据大小,此时的池化操作为上采样(upsmapling)或上池化。
数据的池化,根据被池化的张量维数的不同,一般可分为一维池化、二维池化与三维池化。池化操作都有一个固定的窗口,可以称为池化窗口,类似与卷积操作中的卷积核。 对于池化,大多数都需要池化窗口kernel size、步长stride、填充padding、dilation这几个参数。
池化窗口kernel size表示选取的数据范围,
stride步长表示池化窗口每次沿某个方向的长度,
padding表示对input池化前是否在周围补充0,
dilation为膨胀率。
对于池化,大多数都需要池化窗口kernel size、步长stride、填充padding、dilation这几个参数。池化窗口表示选取的数据范围,步长表示池化窗口每次沿某个方向的长度,padding表示对input池化前是否在周围补充0,dilation为膨胀率。
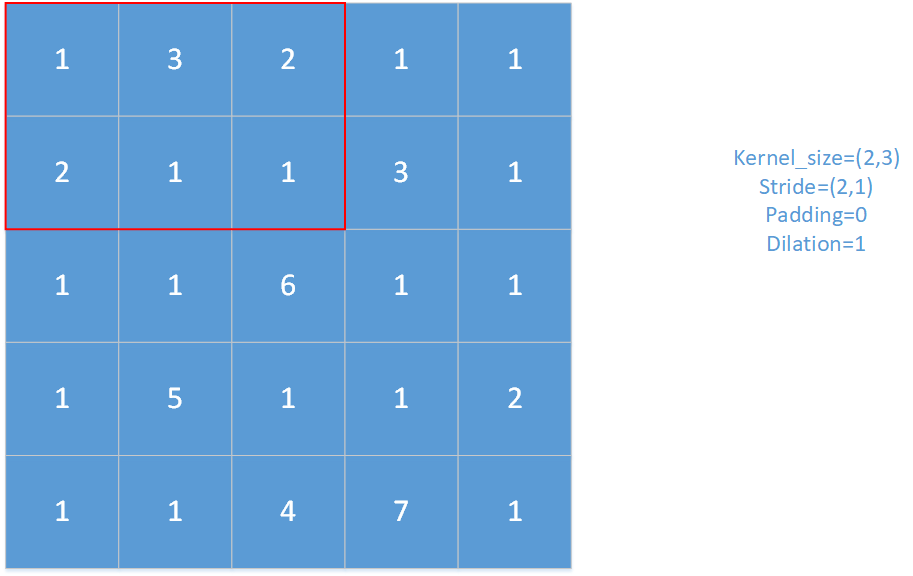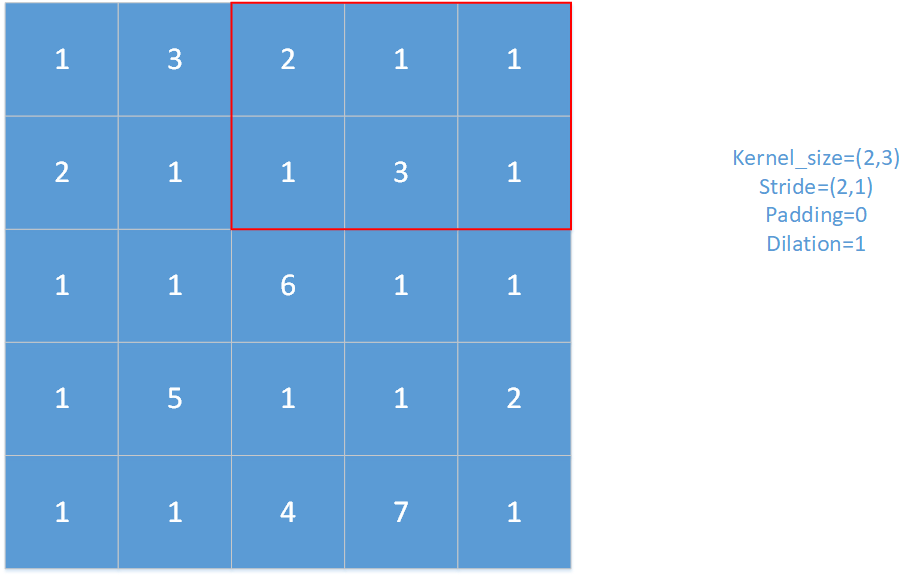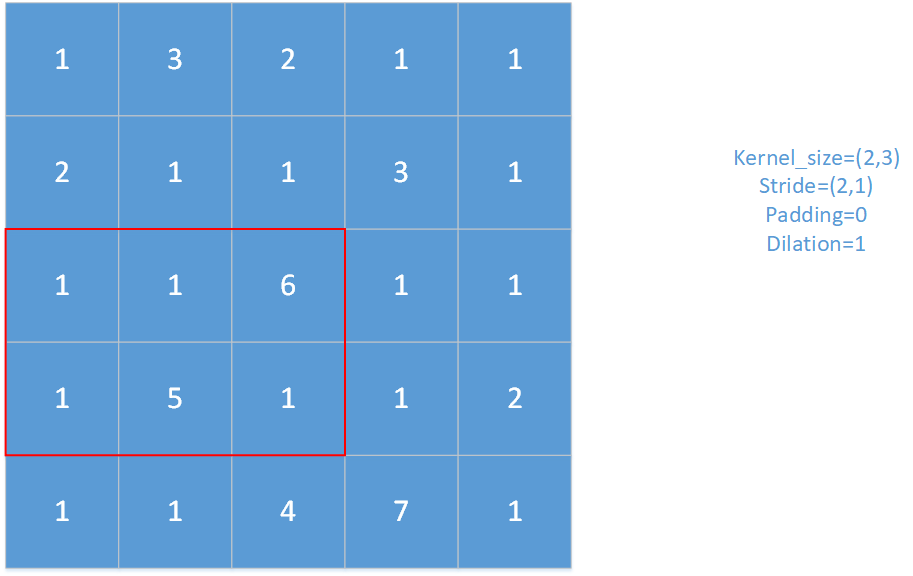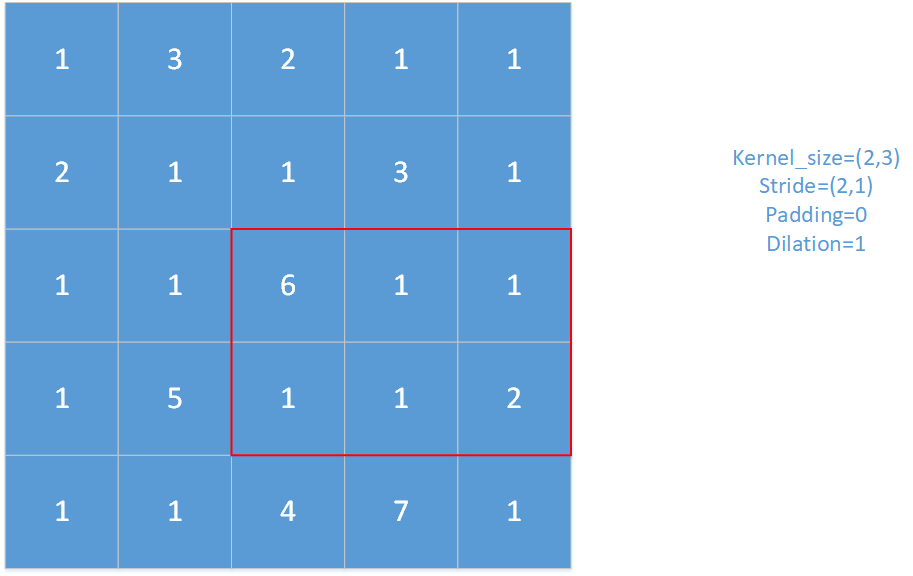
对于上图,红框即为池化窗口。
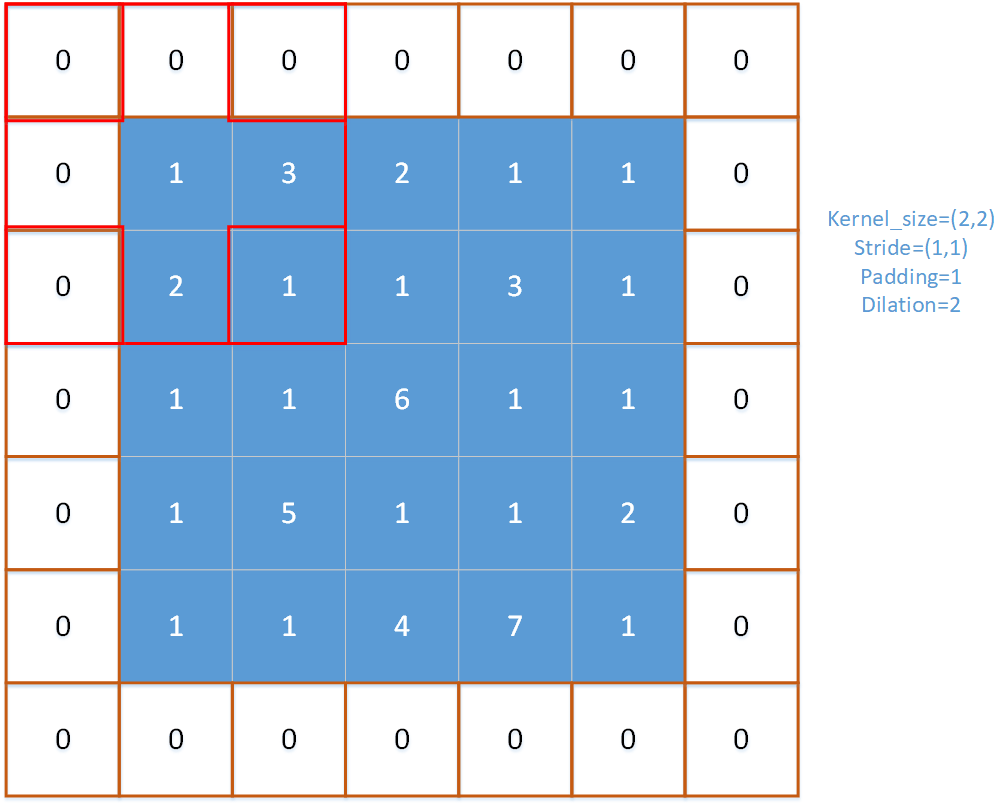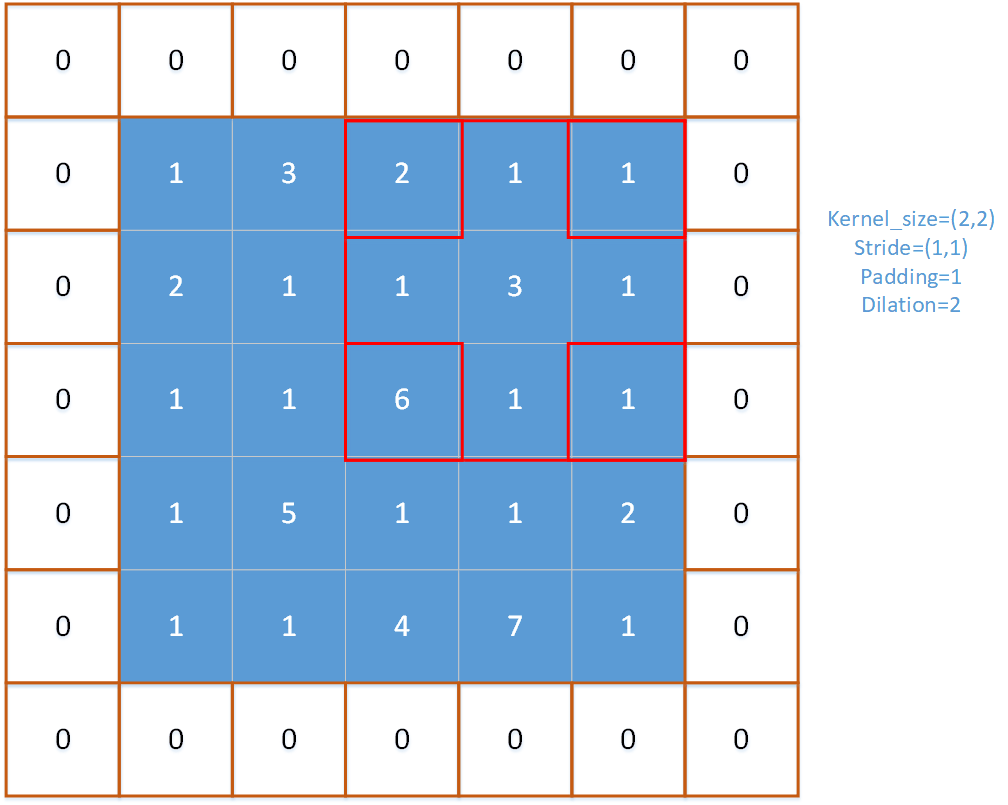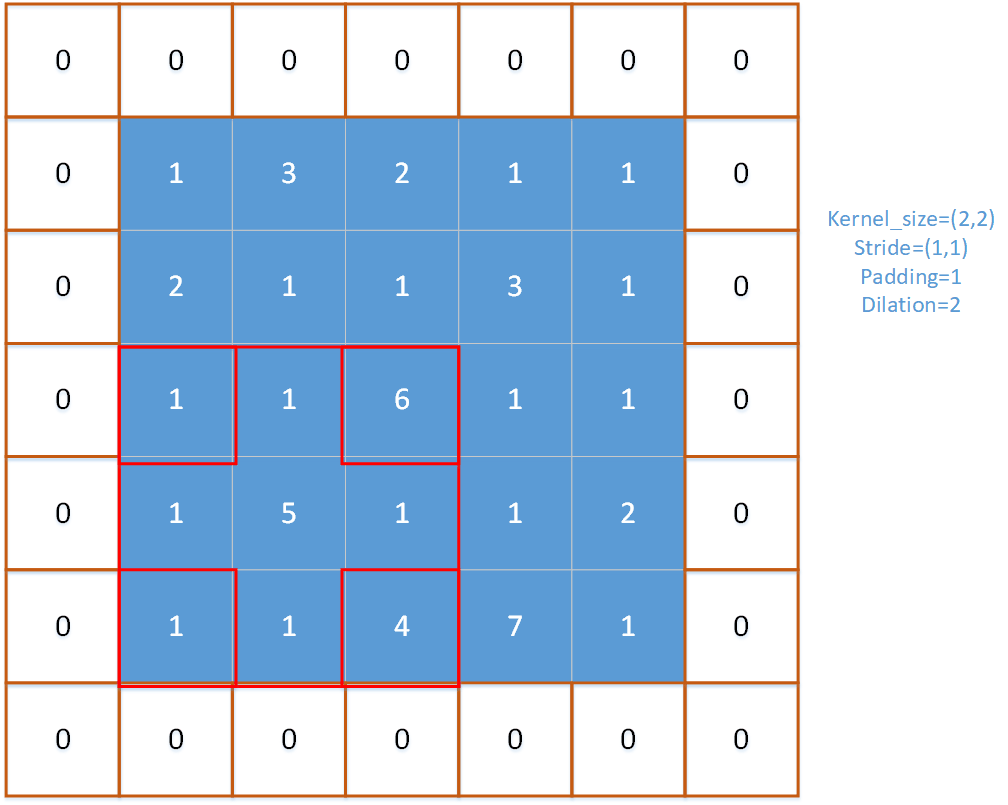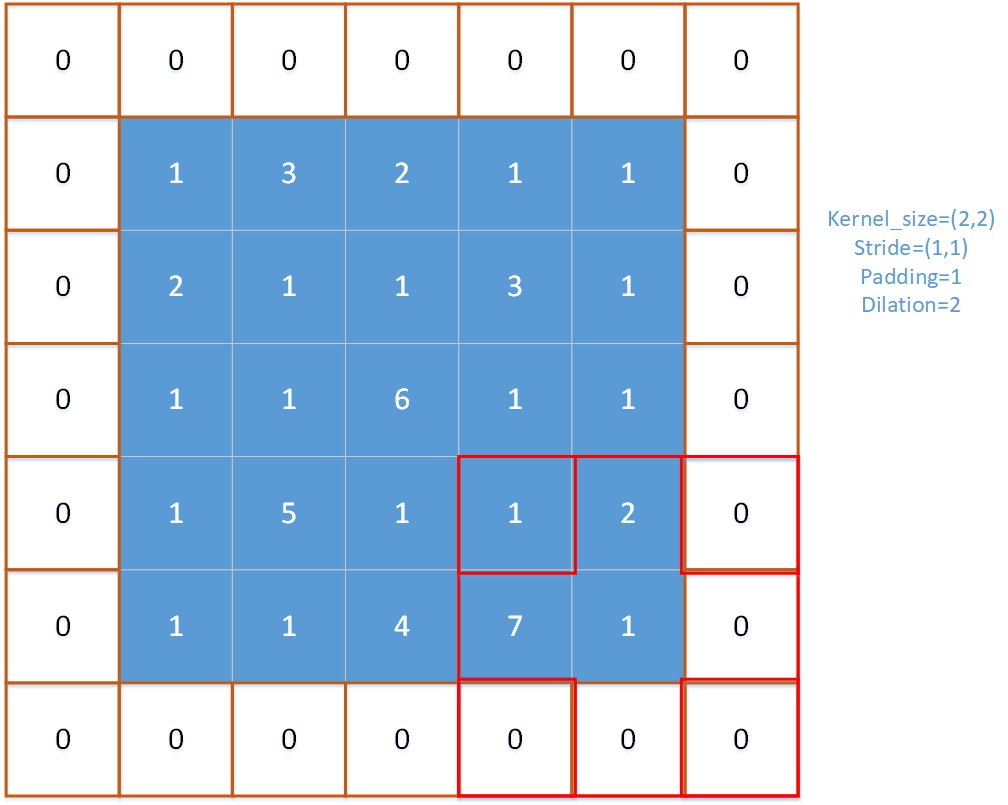
对于上图,padding=1,stride=(1,1),kernel_size=(2,2),dilation=2。
(注:在Pytorch中,padding大小不能超过池化窗口的一半,否则报错)
2:下池化
2.1.最大池化:MaxPool
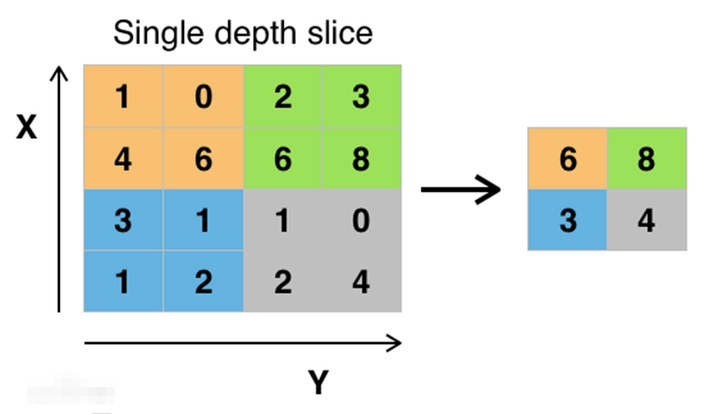
最大池化,即每次选取移动框内数的最大值。它可以分为一维、二维和三维张量数据的池化。
2. 1.1一维数据最大池化
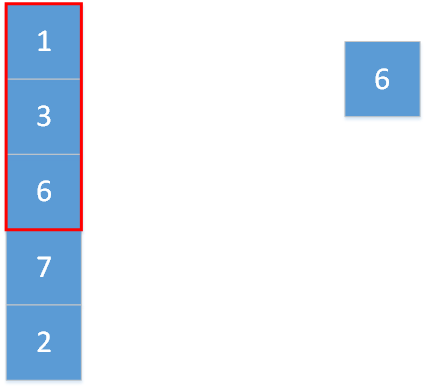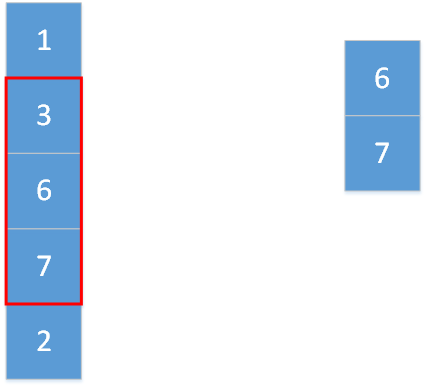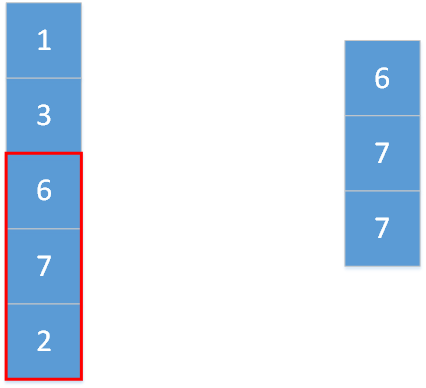
上图显示的便是kernel_size=3,stride=1,padding=0的一维最大池化。
import torch
from torch import nn
input=torch.randint(0,2,size=(2,2,5),dtype=torch.float32)
maxpool1d=nn.MaxPool1d(kernel_size=3,stride=1,padding=0,dilation=1)
output=maxpool1d(input)
print(input,output)2.1.2二维数据与三维数据最大池化
对于二维数据与三维数据的最大池化,与一维情况基本相同。只不过此时的池化窗口为2维张量或三维张量。移动步长也分为两个或三个方向。
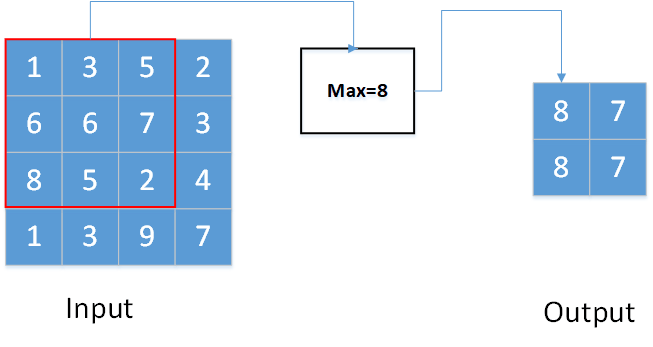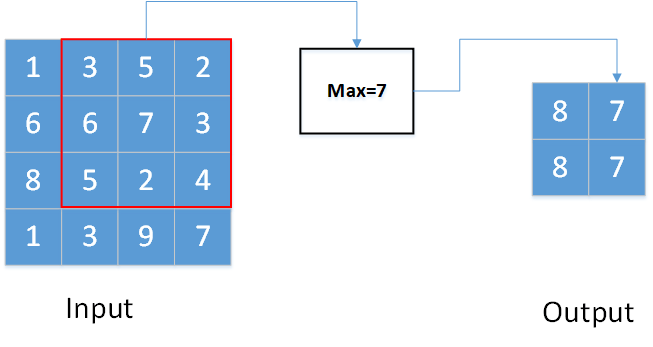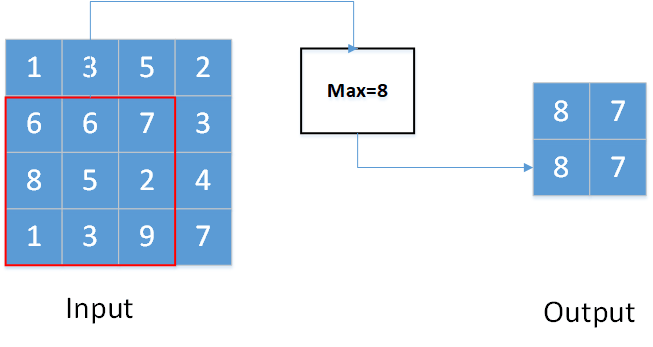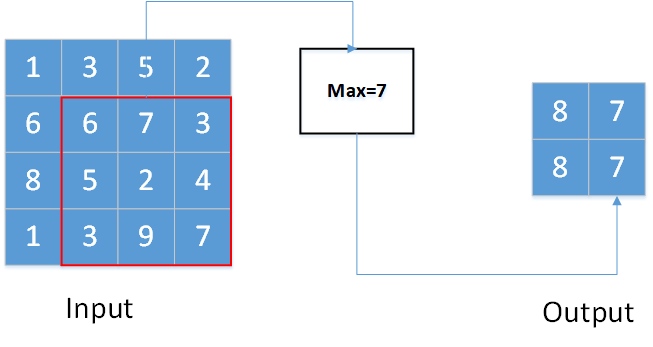
上图显示的是一个kernel_size为(3,3),stride=(1,1),padding=0的二维最大池化。
python中 MaxPool2d 的使用
上面描述的是自适应的池化如何使用,可以很清楚的看到只需要关心每个 channel 中最后 feature 输出的大小即可,并不用亲自设计 kernel size 和 stride 的移动以及 padding 等。那么下面的代码将会在非 adaptive 的情况下,设计 kernel 以及 stride 的步长来展示池化过程中是如何提取特征的
2.1.2.1 方法说明

2D 最大池化要求输入一个信号这个信号有多个 channel 。我们需要输入图像的大小,还有 kernal 的大小。如果 padding 传入的不是 0的话,有一个参数是关于添加膨胀的,这一部分我没太看懂,大体意思是,添加膨胀这种做法会有一个比较好的作用,但是又很难解释到底为什么好。更多内容可以跳转官方文档连接
2.1.2.2 参数说明

池化和卷积一样都是有 Kernel 进行特征提取, Kernel 不断移动。
2.1.2.3 代码理解
1.定义数据
为了方便观察数值的变化,这里定义了一组等差数列作为 feature map 中 pixel 的值,这张 feature map 就是一个 [12,8] 的二维图像,然后将其转化成 [1(N),1( C ),12(H),8(W)] 的格式
feature = torch.arange(12*8.).reshape(1,1,12,8).to(float)
2. nn.Max2dPool 的定义
max_pool = nn.MaxPool2d(kernel_size=(2,3),stride=(1,3))这里定义了一个最大池化,感受野为 [3,3] ,步长为 [1,3] kernel 的移动方向我经常搞混所以这里单独说明一下
因为 kernel 移动是按照 dim 维度进行的,所以先垂直移也就是在 dim=0 的方向上运动,再运动水平
stride:
第一个值:垂直走向的距离,即在 dim=0 时的移动步长
第二个值:水平走向距离,即在 dim=1 时的移动步长3.输出结果
feature_pool = max_pool(feature)下图就是输出结果,输出结果的大小可以根据官网的文档提供的公式进行计算,需要进行解释的是为什么会出现这个结果
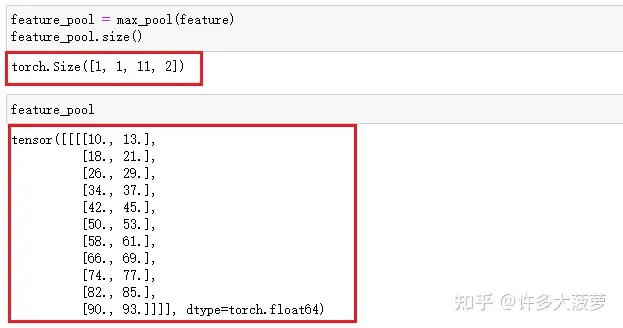
Step1:
下图为在 dim=1 上的移动

Step2: 下图为在 dim=0 上的移动

根据 stride 的大小,我们在垂直方向走一个单位长度,所以在垂直方向移动的时候 kernel 会在红框中的位置
对于平均池化上面的的原理依旧适用
2.2平均池化:AvgPool
平均池化与前面最大池化所有的参数与意义完全相同,并且也分为1d、2d、3d池化。只不过它的输出是池化窗口所有数的平均值,而不是最大值。
import torch
from torch import nn
input=torch.randint(0,2,size=(2,2,5,4),dtype=torch.float32)
avgpool2d=nn.AvgPool2d(kernel_size=(3,3),stride=(2,1),padding=0)
output=avgpool2d(input)
print(input,output)2.3.LP池化:LPPool
LP池化是一类受视觉皮层内阶层结构启发建立的池化模型。它的输出为池化窗口内每个数的p次方后求和再求均值,最后均值的1/p次方即为该部分窗口的输出结果。所以该函数需要参数norm_type,来指定p值,如果p为1,即与均值池化相同;如果p为无穷,则与最大池化相同。

在Pytorch中,LP池化只有一维与二维两种。
import torch
from torch import nn
input=torch.randint(0,2,size=(2,2,5,4),dtype=torch.float32)
lppool2d=nn.LPPool2d(kernel_size=(2,2),stride=1,norm_type=1.5)
output=lppool2d(input)
print(input,output)2.4.自适应最大/平均池化:AdaptiveMaxPool与AdaptiveAvgPool
自适应池化的特点是:无论输入数据的size是多少,最终输出的size始终是函数指定的size。而背后的原理是:该函数可以根据输入size与我们指定的输出size来自动调整池化窗口、步长等参数。所以该函数没有kernel_size,stride,padding等参数,只需要指定输出size大小即可。如果需要让某一维度为原来大小,可以直接指定该部分参数为None。
import torch
from torch import nn
input=torch.randint(0,2,size=(2,2,5,4),dtype=torch.float32)
adaptivemaxpool2d=nn.AdaptiveMaxPool2d((None,2))
output=adaptivemaxpool2d(input)2.4.1 AdaptiveAvgPool2D 的使用
首先先说明一下自适应的池化操作,相比于非自适应的池化操作我们不需要关心池化中的 kernal 应该如何在 feature map 中进行滑动,只需要关心我们最后输出图像的 feature 大小是多少

2.4.1.1 方法说明
使用一个 2D 自适应的池化操作,可以输入一个输入信号(输入信号可以理解为一个 batch size 的图像),这个输入信号由许多输入平面组成(输入平面可以理解为 channel) 不管输入是什么维度,最后可以输出任意的 HxW 的维度组,最后输出 feature 的数量等于输入的 planes(channel) 的数量,也就是说我们最后输出的 channel 数量是不变的
2.4.1.2参数说明
output_size 目标所要输出的 HxW 的大小,这个参数可以传一个 tuple 也可以传单个 H,这样我们的输出就默认是 HxH ,传入的类型是 int 类型,如果传入 None 代表返回原先 input 的维度
2.4.1.3 代码理解
下面我使用 tensor.arange 的方法构建等差数列的矩阵当做 data,并转成图像维度,然后使用自适应平均池化对 image 提取特征
1.定义数据
数据:定义了2张 image ,每张 image 有 3 个 channel ,height = 16 width =8

2.定义池化操作及输出
因为我们传入的图像信号是一个有 channel ,有height ,有 width 的二维图像,所以这里使用的是 2D 的 Pooling ,参数传的是 1 ,也就是让传入的 HxW 的图像坍成 1x1 的一个点
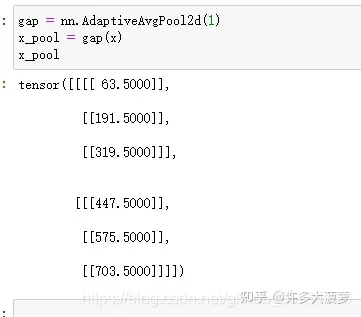
x_pool 的输出维度是 [2,3,1,1],
63 的值可以用等差数列的累加和公式计算出来,是第一张图像第一个 channel 中每个像素点的累加值,也就是 (0+127) 的平均值
总结
以上就是对于池化的简单了解。首先介绍了一下池化的基本知识,主要介绍的是最大池化和平均池化。然后通过代码的方式分别记录了使用自适应池化和非自适应池化的区别。
2.5.分数阶最大池化:FractionalMaxPool
关于分数阶最大池化,兔兔发现它似乎并没有太多的实际用处。函数中仍需要kernel_size,如果指定output_size,它就可以输出指定大小的张量,类似于自适应最大池化;如果指定output_ratio,它就会根据输出大小与输入大小的比例output_ratio来决定输出大小,所以output_ratio为0~1。并且函数不能同时接受output_ratio与output_size,毕竟这两个参数都决定输出大小,同时使用势必会引起冲突。
input=torch.randint(0,20,size=(1,1,5,5),dtype=torch.float32)
pool=nn.FractionalMaxPool2d(kernel_size=(3,3),output_ratio=0.7)
out=pool(input)
print(out)3:上池化
3.1.反最大池化 :MaxUnpool
反池化与前面的池化基本相同,参数一般仍然需要kernel_size,stride,padding等。对于反最大池化,我们还需要提供参数indices。indices表示下池化过程中池化窗口返回那个最大值的位置索引。事实上,在前面的最大池化中,参数return_indices即表示是否返回索引,只不过该函数默认为False。
input=torch.randint(0,2,size=(1,1,5,5),dtype=torch.float32)
pool=nn.MaxPool2d(kernel_size=3,stride=1,padding=0,return_indices=True)
out=pool(input)
print(input)
print(out[0]) #池化后结果
print(out[1]) #池化indice
那么,现在对于反最大池化就比较好理解了,这个函数根据传入的参数indices,来使得上池化后该位置索引为池化窗口最大值,其余都为0。这里需要注意的是,indices不能传给nn.MaxUnpool,而是传给它的forward()函数中。
input=torch.randint(0,2,size=(1,1,5,5),dtype=torch.float32)
pool=nn.MaxPool2d(kernel_size=3,stride=1,padding=0,return_indices=True)
out,indices=pool(input)
unpool=nn.MaxUnpool2d(kernel_size=3,stride=1,padding=0)
out=unpool(out,indices=indices)
print(out)
4:其它
对于前面的讲到的池化,实际的池化种类远远不止这些,但Pytorch中也并未提供其它种类的池化方法,所以此时需要我们能够根据池化原理来设计池化层。兔兔在这里以一种随机池化为例,来实现该方法。
随机池化(Stochastic Pooling)是每次以一定的概率来选取池化窗口的值,并且窗口中的值越大,被选中作为输出的概率越大。所以需要用窗口中每一个数除以窗口中所有数的和,此时每个位置的值即为该位置被选中输出的概率。
import torch
from torch import nn
import numpy as np
class stochasticPool2d(nn.Module):
def __init__(self,kernel_size,stride):
super().__init__()
self.kernel_size=kernel_size
self.stride=stride
def forward(self,input):
b,c,h,w=input.shape
output=[]
for B in range(b):
batch=[]
for C in range(c):
channel=[]
for i in range(0,h-self.kernel_size[0]+1,self.stride[0]):
l=[]
for j in range(0,w-self.kernel_size[1]+1,self.stride[1]):
kernel=input[B,C,i:i+self.kernel_size[0],j:j+self.kernel_size[1]]
num=kernel.detach().numpy().reshape((1,-1))[0]
pro=(kernel/kernel.sum()).detach().numpy()
pro=pro.reshape((1,-1))[0]
out=np.random.choice(a=num,p=pro,replace=True)
l.append(out)
channel.append(l)
batch.append(channel)
output.append(batch)
return torch.tensor(output,dtype=torch.float32)
if __name__=='__main__':
input=torch.randint(0,2,size=(1,1,5,5))
pool=stochasticPool2d(kernel_size=(3,3),stride=(1,1))
print(pool(input))5、总结
池化作为深度学习中常用的一种方法,具有对于模型的优化具有重要意义。事实上,池化的种类是非常多的,但是在Pytorch中并未提供所有的方法。一方面我们可以根据Pytorch中已有的池化方法,调整其中的参数来实现我们想要的池化方法;另一方面,我们也应该学会在已有方案都无法实行的情况下,能够自己方法原理设计池化层。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:https://blog.csdn.net/weixin_60737527/article/details/127024456
![]()
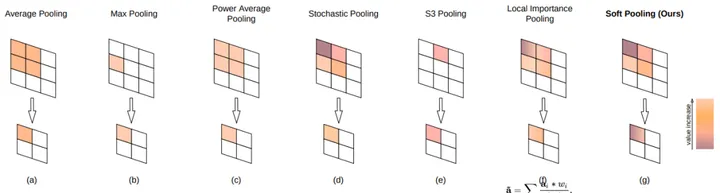
4、 几种常见的池化操作

最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。即,取局部接受域中值最大的点。同理,平均池化(Average Pooling)为取局部接受域中值的平均值。
![]()
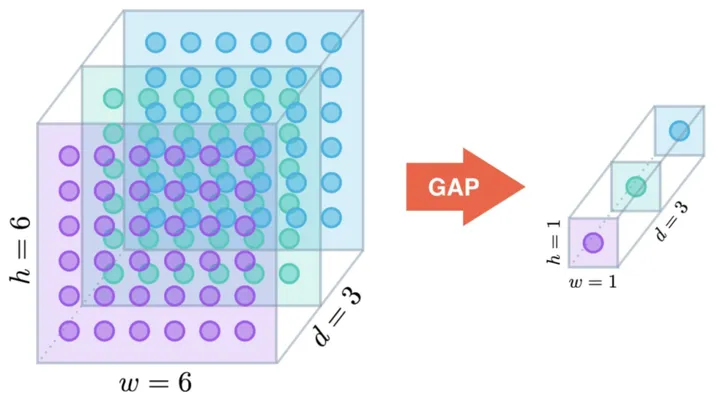
Global Pooling就是Pooling的滑窗size和整个Feature Map的size一样大。在滑窗内的具体pooling方法可以是任意的,所以就会被细分为Global Average Pooling,Global Max Pooling等。
![]()
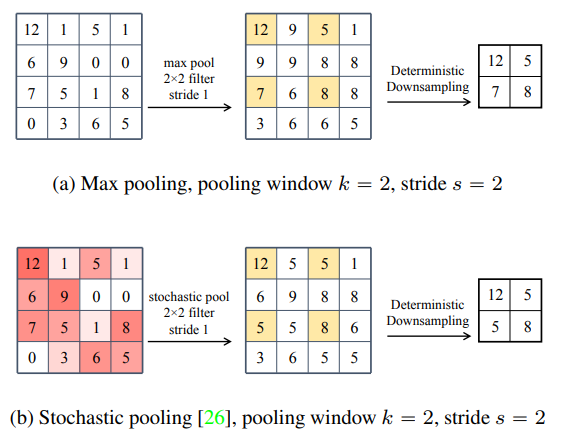
Stochastic pooling是论文《Stochastic Pooling for Regularization of Deep Convolutional Neural Networks》中提到的一种池化策略,大意是只需对特征区域元素按照其概率值大小随机选择,元素值大的被选中的概率也大。
![]()
Mix Pooling是同时利用最大值池化Max Pooling与均值池化Average Pooling两种的优势而引申的一种池化策略。常见的两种组合策略:拼接Cat与叠加Add。
![]()

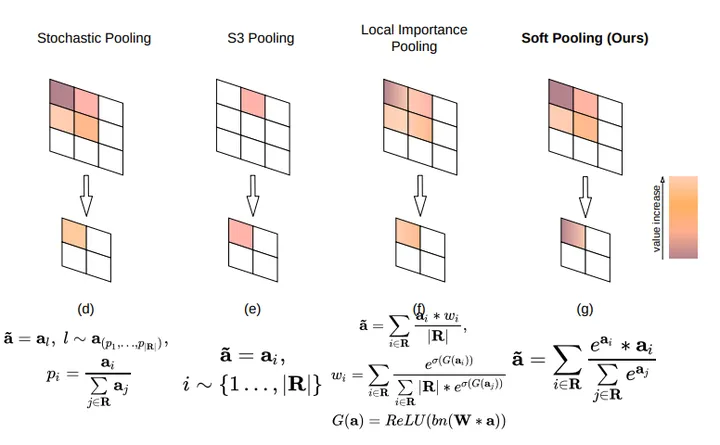
SoftPool是一种变种的Pooling,它可以在保持池化层功能的同时尽可能减少池化过程中带来的信息损失。上图展示了SoftPool操作的Forward阶段与Backward阶段,6*6大小的区域表示的是激活映射a。
![]()
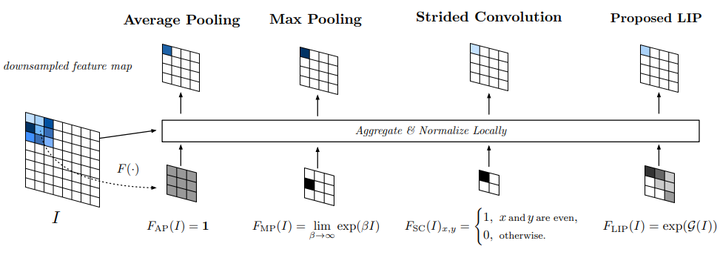
Local Importance-based Pooling提出通过一个基于输入特征的子网络自动学习重要性。它能够自适应地确定哪些特征更重要,同时在采样过程中自动增强识别特征。具体思路是,在原feature map上学习一个类似于attention的map,然后和原图进行加权求平均。需要说明的是,这里采样的间隔其实还是固定的,不符合上述描述的第一条,但是作者认为,由于importance是可变,从而实现变形的感受野。
![]()
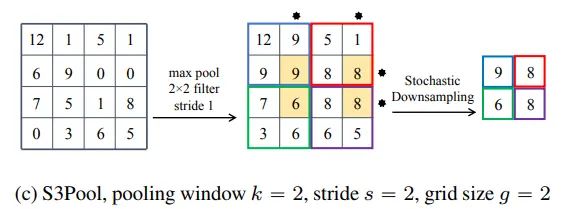
S3Pool提出一种随机位置池化策略,集成了随机池化Stochastic Pooling与最大值池化Max Pooling。
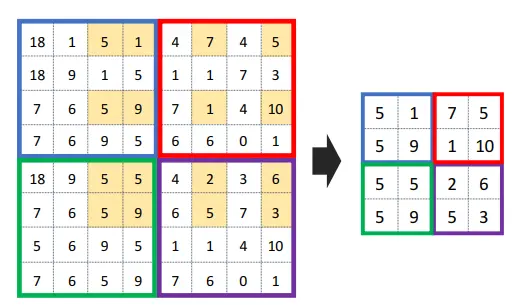
![]()
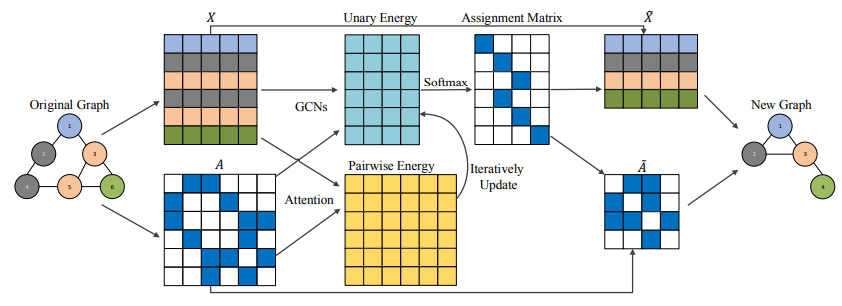
图池化是基于条件随机场的,它是将图池化视为一个节点聚类问题,并使用CRF在不同节点的分配之间建立关系。并通过结合图拓扑信息来推广这个方法,使得图池化可以控制CRF中的成对团集。
![]()

Region of Interest Pooling是在目标检测任务中广泛使用的操作。它对于来自输入列表的每个感兴趣区域,它采用与其对应的输入特征图的一部分并将其缩放到某个预定义的大小。这可以显着加快训练和测试时间,它允许重新使用卷积网络中的特征映射,同时也允许以端到端的方式训练物体检测系统。

















 3039
3039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









