







 本文详细介绍了K-近邻(KNN)算法,包括其基本原理、距离度量(如欧式距离、曼哈顿距离和切比雪夫距离)、K值选择方法以及分类决策规则。此外,文章重点讲解了k-d树在实现KNN中的应用,包括k-d树的构建过程和最邻近查找算法,阐述了k-d树在高维空间数据检索中的优势。通过实例展示了k-d树如何进行空间划分和查找最近邻的过程。
本文详细介绍了K-近邻(KNN)算法,包括其基本原理、距离度量(如欧式距离、曼哈顿距离和切比雪夫距离)、K值选择方法以及分类决策规则。此外,文章重点讲解了k-d树在实现KNN中的应用,包括k-d树的构建过程和最邻近查找算法,阐述了k-d树在高维空间数据检索中的优势。通过实例展示了k-d树如何进行空间划分和查找最近邻的过程。
https://www.cnblogs.com/eyeszjwang/articles/2429382.html
kd树详解 https://blog.csdn.net/v_JULY_v/article/details/8203674
一、K-近邻算法(KNN)概述
一个训练对象被分到了多个类的问题,与相邻K个的值,K值中个数最多的那个分类,就判定为那个类别。

模型三个基本要素:距离度量,K值选择,分类决策规则。
二、距离度量
1、欧式距离
2、曼哈顿距离

3. 切比雪夫距离,若二个向量或二个点p 、and q,其座标分别为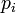 及
及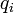 ,则两者之间的切比雪夫距离定义如下:
,则两者之间的切比雪夫距离定义如下:


三、K值的选择
交叉验证法 一部分样本做训练集,一部分样本做测试集,选择最优值K
四、分类决策规则
多数表决,即输入实例K个邻近的训练实例中多数类决定输入实例的类。多数表决规则等价于经验风险最小化。
五、k近邻的实现:kd树
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。本质上说,Kd-树就是一种平衡二叉树。

应用背景
SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。
索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。
特征匹配算子大致可以分为两类。一类是线性扫描法,即将数据集中的点与查询点逐一进行距离比较,也就是穷举,缺点很明显,就是没有利用数据集本身蕴含的任何结构信息,搜索效率较低&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









