







 本文介绍了判别模型与生成模型的区别,重点讨论了高斯判别分析(GDA)的原理和应用。GDA是一种假设输入特征符合多变量正态分布的模型,与logistic回归存在联系。同时,文章提到了朴素贝叶斯模型在处理离散特征时的应用,并讨论了解决数据稀疏问题的拉普拉斯平滑方法。
本文介绍了判别模型与生成模型的区别,重点讨论了高斯判别分析(GDA)的原理和应用。GDA是一种假设输入特征符合多变量正态分布的模型,与logistic回归存在联系。同时,文章提到了朴素贝叶斯模型在处理离散特征时的应用,并讨论了解决数据稀疏问题的拉普拉斯平滑方法。
判别、生成区别:http://blog.sciencenet.cn/home.php?mod=space&uid=248173&do=blog&id=227964
朴素贝叶斯和高斯判别分析:https://www.cnblogs.com/zyber/p/6490663.html
一:判别、生成
1、 生成模型:无穷样本==》概率密度模型 = 产生模型==》预测:隐马尔科夫模型、朴素贝叶斯模型、高斯混合模型、LDA、Restricted Boltzmann Machine等,求的是联合概率
2、 判别模型:有限样本==》判别函数 = 预测模型==》预测 :线性回归、对数回归、线性判别分析、支持向量机、boosting、条件随机场、神经网络等。 求的是条件概率
概要:简单的说,假设o是观察值,q是模型。
如果对P(o|q)建模,就是Generative模型。其基本思想是首先建立样本的概率密度模型,再利用模型进行推理预测。要求已知样本无穷或尽可能的大限制。
这种方法一般建立在统计力学和bayes理论的基础之上。
如果对条件概率(后验概率) P(q|o)建模,就是Discrminative模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。代表性理论为统计学习理论。
这两种方法目前交叉较多。
利用贝叶斯公式发现两个模型的统一性:
![clip_image011[8]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103052258382648.png)
由于我们关注的是y的离散值结果中哪个概率大(比如山羊概率和绵羊概率哪个大),而并不是关心具体的概率,因此上式改写为:

其中p(y|x)称为后验概率,![]() 称为先验概率。
称为先验概率。
由![]() ,因此有时称判别模型求的是条件概率,生成模型求的是联合概率。
,因此有时称判别模型求的是条件概率,生成模型求的是联合概率。
二、高斯判别分析:gaussian discriminant analysis
1) 多值正态分布
多变量正态分布描述的是n维随机变量的分布情况,这里的![]() 变成了向量,
变成了向量,![]() 也变成了矩阵
也变成了矩阵![]() 。写作
。写作![]() 。假设有n个随机变量X1,X2,…,Xn。
。假设有n个随机变量X1,X2,…,Xn。![]() 的第i个分量是E(Xi),而
的第i个分量是E(Xi),而![]() 。
。
概率密度函数如下:
![clip_image018[28]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103052258471723.png)
其中|![]() 是
是![]() 的行列式,
的行列式,![]() 是协方差矩阵,而且是对称半正定的。
是协方差矩阵,而且是对称半正定的。
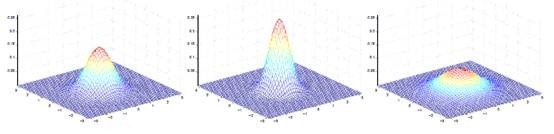
当![]() 是二维的时候可以如下图表示:
是二维的时候可以如下图表示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6956
6956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}