







目录
- 示意图
- 二分类问题描述
- 开始求解
- 1. Primal problem:带 ω , b \omega,b ω,b约束的优化
- 2. 拉格朗日乘子法→对 ω , b \omega,b ω,b无约束的优化
- 3. 转化为强对偶问题
- 4. 求解对偶问题:解拉格朗日方程 m i n ω , b L ( ω , b , λ ) {min \atop \omega,b}L(\omega,b,\lambda) ω,bminL(ω,b,λ)
- (1) 求 ∂ L ∂ b = 0 {\frac {\partial L} {\partial b}}=0 ∂b∂L=0
- (2) 将 ∑ i = 1 N λ i y i = 0 \displaystyle\sum_{i=1}^N\lambda_iy_i=0 i=1∑Nλiyi=0代入到 L ( ω , b , λ ) L(\omega,b,\lambda) L(ω,b,λ)中
- (3) 求 ∂ L ∂ ω = 0 {\frac {\partial L} {\partial \omega}}=0 ∂ω∂L=0
- (4) 将 ω = ∑ i = 1 N λ i y i x i \omega=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i ω=i=1∑Nλiyixi代入到 L ( ω , b , λ ) L(\omega,b,\lambda) L(ω,b,λ)中
- (5) 对偶问题的最终优化式
- 5. KKT条件求解对偶问题
示意图
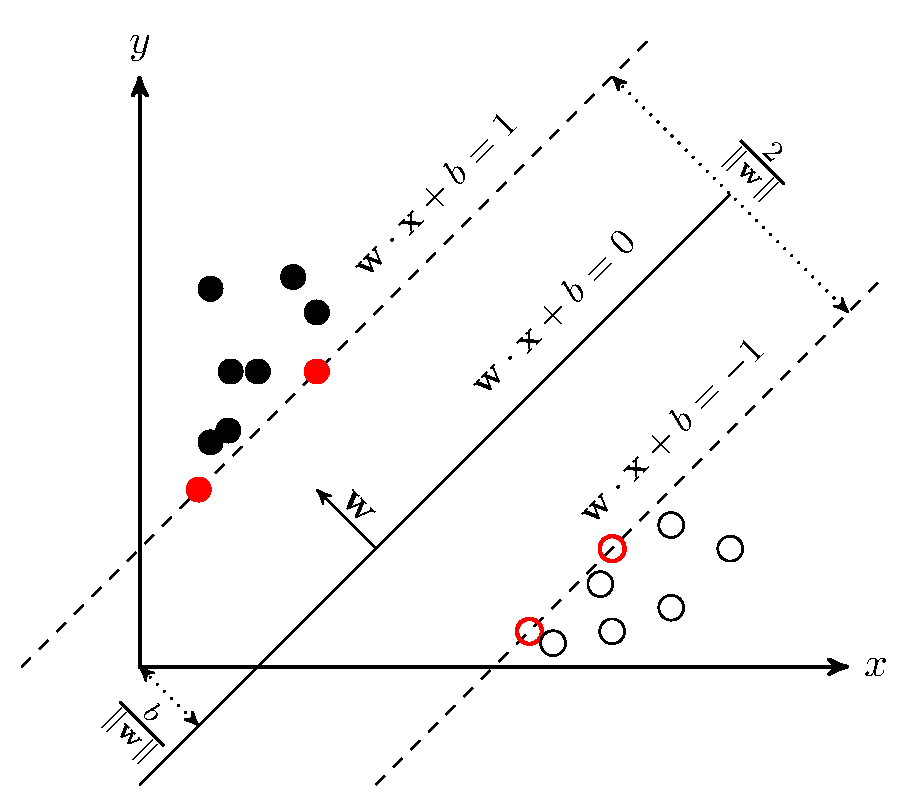
二分类问题描述
D
a
t
a
=
{
(
x
i
,
y
i
)
}
i
=
1
N
,
x
i
∈
R
p
,
y
i
∈
{
−
1
,
+
1
}
Data=\{(x_i, y_i)\}_{i=1}^N,x_i\in\R^p,y_i\in\{-1,+1\}
Data={(xi,yi)}i=1N,xi∈Rp,yi∈{−1,+1}
由于超平面
ω
T
x
+
b
\omega^Tx+b
ωTx+b有很多个,要找到最好的一个超平面,以得到最低的泛化误差(或测试误差、期望损失)。
hard-margin SVM判别模型,与概率无关:
f
(
ω
)
=
s
i
g
n
(
ω
T
x
+
b
)
=
{
ω
T
x
+
b
>
0
,
f
(
ω
)
=
1
ω
T
x
+
b
<
0
,
f
(
ω
)
=
−
1
f(\omega)=sign(\omega^Tx+b)=\begin{cases}\omega^Tx+b>0,f(\omega)=1\\\omega^Tx+b<0,f(\omega)=-1\end{cases}
f(ω)=sign(ωTx+b)={ωTx+b>0,f(ω)=1ωTx+b<0,f(ω)=−1
目标函数:
{
m
a
x
m
a
r
g
i
n
(
ω
,
b
)
s
.
t
.
{
ω
T
x
i
+
b
>
0
,
y
i
=
1
ω
T
x
i
+
b
<
0
,
y
i
=
−
1
⇒
y
i
(
ω
T
x
i
+
b
)
>
0
,
i
=
1...
,
N
\begin{cases}max\space margin(\omega,b) \\ s.t.\space \begin{cases}\omega^Tx_i+b>0,y_i=1\\\omega^Tx_i+b<0,y_i=-1\end{cases}\Rightarrow y_i(\omega^Tx_i+b)>0,i=1...,N\end{cases}
⎩⎪⎨⎪⎧max margin(ω,b)s.t. {ωTxi+b>0,yi=1ωTxi+b<0,yi=−1⇒yi(ωTxi+b)>0,i=1...,N
即,
{
m
a
x
m
a
r
g
i
n
(
ω
,
b
)
s
.
t
.
y
i
(
ω
T
x
i
+
b
)
>
0
,
i
=
1
,
.
.
.
,
N
\begin{cases}max\space margin(\omega,b) \\ s.t.\space y_i(\omega^Tx_i+b)>0,i=1,...,N\end{cases}
{max margin(ω,b)s.t. yi(ωTxi+b)>0,i=1,...,N
什么是margin?
答:一共有N个点到直线的距离,最小的那个就是margin。点到直线距离公式,
m a r g i n ( ω , b ) = m i n ω , b , x i d i s t a n c e ( ω , b , x i ) = m i n ω , b , x i 1 ∥ ω ∥ ∣ ω T x i + b ∣ margin(\omega,b)={min \atop \omega,b,x_i}distance(\omega,b,x_i)={min \atop \omega,b,x_i}{\frac 1 {\parallel\omega\parallel}}\mid\omega^Tx_i+b\mid margin(ω,b)=ω,b,ximindistance(ω,b,xi)=ω,b,ximin∥ω∥1∣ωTxi+b∣
则上式写为:
{
m
a
x
ω
,
b
m
i
n
ω
,
b
,
x
i
1
∥
ω
∥
∣
ω
T
x
i
+
b
∣
=
m
a
x
ω
,
b
m
i
n
x
i
1
∥
ω
∥
∣
ω
T
x
i
+
b
∣
=
m
a
x
ω
,
b
1
∥
ω
∥
m
i
n
x
i
y
i
(
ω
T
x
i
+
b
)
⇐
y
i
∈
{
−
1
,
+
1
}
s
.
t
.
y
i
(
ω
T
x
i
+
b
)
>
0
\begin{cases}{max \atop \omega,b}{min \atop \omega,b,x_i}{\frac 1 {\parallel\omega\parallel}}\mid\omega^Tx_i+b\mid\space ={max \atop \omega,b}{min \atop x_i}{\frac 1 {\parallel\omega\parallel}}\mid\omega^Tx_i+b\mid={max \atop \omega,b}{\frac 1 {\parallel\omega\parallel}}{min \atop x_i}y_i(\omega^Tx_i+b)\Larr y_i\in\{-1,+1\} \\ s.t.\space y_i(\omega^Tx_i+b)>0\end{cases}
{ω,bmaxω,b,ximin∥ω∥1∣ωTxi+b∣ =ω,bmaxximin∥ω∥1∣ωTxi+b∣=ω,bmax∥ω∥1ximinyi(ωTxi+b)⇐yi∈{−1,+1}s.t. yi(ωTxi+b)>0
y i ( ω T x i + b ) > 0 y_i(\omega^Tx_i+b)>0 yi(ωTxi+b)>0可以理解为: ∃ γ > 0 , s . t . m i n x i , y i y i ( ω T x i + b ) = γ \exist\space\gamma>0,s.t.\space {min \atop x_i,y_i}y_i(\omega^Tx_i+b)=\gamma ∃ γ>0,s.t. xi,yiminyi(ωTxi+b)=γ
γ \gamma γ的取值对式子(或超平面)是没有影响的,实际上就是对 ω , b \omega,b ω,b的缩放。
因此,令 γ = 1 \gamma=1 γ=1。
则, m a x ω , b 1 ∥ ω ∥ m i n x i y i ( ω T x i + b ) = m a x ω , b 1 ∥ ω ∥ γ = m a x ω , b 1 ∥ ω ∥ {max \atop \omega,b}{\frac 1 {\parallel\omega\parallel}}{min \atop x_i}y_i(\omega^Tx_i+b)={max \atop \omega,b}{\frac 1 {\parallel\omega\parallel}}\gamma={max \atop \omega,b}{\frac 1 {\parallel\omega\parallel}} ω,bmax∥ω∥1ximinyi(ωTxi+b)=ω,bmax∥ω∥1γ=ω,bmax∥ω∥1
则,上式可写为:
{ m a x ω , b 1 ∥ ω ∥ ⇒ m i n ω , b ∥ ω ∥ = m i n ω , b 1 2 ω T ω 硬 间 隔 ; 二 次 的 、 凸 优 化 , 可 直 接 求 解 s . t . m i n x i y i ( ω T x i + b ) = 1 ⇒ y i ( ω T x i + b ) ⩾ 1 , i = 1 , . . . , N 有 N 个 约 束 \begin{cases}{max \atop \omega,b}{\frac 1 {\parallel\omega\parallel}}\Rarr{min \atop \omega,b}{\parallel\omega\parallel}={min \atop \omega,b}{\frac 1 2}\omega^T\omega\space硬间隔;二次的、凸优化,可直接求解 \\s.t.\space {min\atop x_i}y_i(\omega^Tx_i+b)=1\Rarr y_i(\omega^Tx_i+b)\geqslant1,i=1,...,N\space 有N个约束 \end{cases} {ω,bmax∥ω∥1⇒ω,bmin∥ω∥=ω,bmin21ωTω 硬间隔;二次的、凸优化,可直接求解s.t. ximinyi(ωTxi+b)=1⇒yi(ωTxi+b)⩾1,i=1,...,N 有N个约束
则, ( 1 ) { m i n ω , b 1 2 ω T ω s . t . y i ( ω T x i + b ) ⩾ 1 , i = 1 , . . . , N (1)\begin{cases}{min \atop \omega,b}{\frac 1 2}\omega^T\omega\space \\s.t.\space y_i(\omega^Tx_i+b)\geqslant1,i=1,...,N \end{cases} (1){ω,bmin21ωTω s.t. yi(ωTxi+b)⩾1,i=1,...,N
开始求解
1. Primal problem:带 ω , b \omega,b ω,b约束的优化
( 1 ) { m i n ω , b 1 2 ω T ω s . t . y i ( ω T x i + b ) ⩾ 1 , f o r i = 1 , . . . , N ⇔ 1 − y i ( ω T x i + b ) ⩽ 0 (1)\begin{cases} {min \atop \omega,b}{\frac 1 2}\omega^T\omega \\ s.t. \space y_i(\omega^Tx_i+b)\geqslant1,for \space i=1,...,N \xLeftrightarrow{}1-y_i(\omega^Tx_i+b)\leqslant0\end{cases} (1){ω,bmin21ωTωs.t. yi(ωTxi+b)⩾1,for i=1,...,N 1−yi(ωTxi+b)⩽0
2. 拉格朗日乘子法→对 ω , b \omega,b ω,b无约束的优化
L
(
ω
,
b
,
λ
)
=
1
2
ω
T
ω
+
∑
i
=
1
N
λ
i
(
1
−
y
i
(
ω
T
x
i
+
b
)
)
L(\omega,b,\lambda)={\frac 1 2}{\omega^T}\omega+\displaystyle\sum_{i=1}^N\lambda_i(1-y_i(\omega^Tx_i+b))
L(ω,b,λ)=21ωTω+i=1∑Nλi(1−yi(ωTxi+b)),
λ
i
⩾
0
\lambda_i\geqslant0
λi⩾0
(
2
)
{
m
i
n
ω
,
b
m
a
x
λ
L
(
ω
,
b
,
λ
)
s
.
t
.
λ
i
⩾
0
(2)\begin{cases}{min \atop \omega,b} {max \atop \lambda}L(\omega,b,\lambda) \\ s.t.\space\lambda_i\geqslant0\end{cases}
(2){ω,bminλmaxL(ω,b,λ)s.t. λi⩾0
值得注意的是: 1 − y i ( ω T x i + b ) ⩽ 0 1-y_i(\omega^Tx_i+b)\leqslant0 1−yi(ωTxi+b)⩽0。为什么呢?
答:
直观上看,
如果 1 − y i ( ω T x i + b ) > 0 1-y_i(\omega^Tx_i+b)>0 1−yi(ωTxi+b)>0,则 m a x λ L = 1 2 ω T ω + ∞ = ∞ {max\atop\lambda}L={\frac 1 2}{\omega^T}\omega+\infty=\infty λmaxL=21ωTω+∞=∞
如果 1 − y i ( ω T x i + b ) ⩽ 0 1-y_i(\omega^Tx_i+b)\leqslant0 1−yi(ωTxi+b)⩽0,则 m a x λ L {max\atop\lambda}L λmaxL一定存在, m a x λ L = 1 2 ω T ω + 0 = 1 2 ω T ω ( λ i → 0 ) {max\atop\lambda}L={\frac 1 2}{\omega^T}\omega+0={\frac 1 2}{\omega^T}\omega\space(\lambda_i\rarr0) λmaxL=21ωTω+0=21ωTω (λi→0)
则, m i n ω , b m a x λ L ( ω , b , λ ) = m i n ω , b ( ∞ , 1 2 ω T ω ) = 1 2 ω T ω {min \atop \omega,b} {max \atop \lambda}L(\omega,b,\lambda)={min \atop \omega,b} (\infty,{\frac 1 2}{\omega^T}\omega)={\frac 1 2}{\omega^T}\omega ω,bminλmaxL(ω,b,λ)=ω,bmin(∞,21ωTω)=21ωTω
因此, 1 − y i ( ω T x i + b ) > 0 1-y_i(\omega^Tx_i+b)>0 1−yi(ωTxi+b)>0被丢弃了。
3. 转化为强对偶问题
( 3 ) { m a x λ m i n ω , b L ( ω , b , λ ) s . t . λ i ⩾ 0 (3)\begin{cases}{max \atop \lambda}{min \atop \omega,b}L(\omega,b,\lambda) \\s.t.\space \lambda_i \geqslant0\end{cases} (3){λmaxω,bminL(ω,b,λ)s.t. λi⩾0
什么是强、弱对偶?
答:凸优化二次规划问题,它的约束是线性的,目标函数是二次的,因此满足强对偶关系。(可证)
(1)弱对偶关系为 m i n m a x L ⩾ m a x m i n L min\space maxL\geqslant max\space minL min maxL⩾max minL,对应理解为“尾凤 ⩾ \geqslant ⩾头鸡”,即凤尾优于鸡头、瘦死的骆驼比马大。
(2)强对偶关系,就是把 ⩾ \geqslant ⩾改为=。
4. 求解对偶问题:解拉格朗日方程 m i n ω , b L ( ω , b , λ ) {min \atop \omega,b}L(\omega,b,\lambda) ω,bminL(ω,b,λ)
L ( ω , b , λ ) = 1 2 ω T ω + ∑ i = 1 N λ i ( 1 − y i ( ω T x i + b ) ) L(\omega,b,\lambda)={\frac 1 2}{\omega^T}\omega+\displaystyle\sum_{i=1}^N\lambda_i(1-y_i(\omega^Tx_i+b)) L(ω,b,λ)=21ωTω+i=1∑Nλi(1−yi(ωTxi+b)), λ i ⩾ 0 \lambda_i\geqslant0 λi⩾0
(1) 求 ∂ L ∂ b = 0 {\frac {\partial L} {\partial b}}=0 ∂b∂L=0
∂
L
∂
b
=
∂
∂
b
[
∑
i
=
1
N
λ
i
−
∑
i
=
1
N
λ
i
y
i
(
ω
T
x
i
+
b
)
]
=
∂
∂
b
[
−
∑
i
=
1
N
λ
i
y
i
b
)
]
=
−
∑
i
=
1
N
λ
i
y
i
=
0
{\frac {\partial L} {\partial b}}={\frac {\partial }{\partial b}}[\displaystyle\sum_{i=1}^N\lambda_i-\displaystyle\sum_{i=1}^N\lambda_iy_i(\omega^Tx_i+b)]={\frac {\partial }{\partial b}}[-\displaystyle\sum_{i=1}^N\lambda_iy_ib)]\\=-\displaystyle\sum_{i=1}^N\lambda_iy_i=0
∂b∂L=∂b∂[i=1∑Nλi−i=1∑Nλiyi(ωTxi+b)]=∂b∂[−i=1∑Nλiyib)]=−i=1∑Nλiyi=0
则,
∑
i
=
1
N
λ
i
y
i
=
0
\displaystyle\sum_{i=1}^N\lambda_iy_i=0
i=1∑Nλiyi=0
(2) 将 ∑ i = 1 N λ i y i = 0 \displaystyle\sum_{i=1}^N\lambda_iy_i=0 i=1∑Nλiyi=0代入到 L ( ω , b , λ ) L(\omega,b,\lambda) L(ω,b,λ)中
L ( ω , b , λ ) = 1 2 ω T ω + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i ( ω T x i + b ) = 1 2 ω T ω + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i ω T x i + ∑ i = 1 N λ i y i b = 1 2 ω T ω + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i ω T x i L(\omega,b,\lambda)={\frac 1 2}\omega^T\omega+\displaystyle\sum_{i=1}^N\lambda_i-\displaystyle\sum_{i=1}^N\lambda_iy_i(\omega^Tx_i+b)\\={\frac 1 2}\omega^T\omega+\displaystyle\sum_{i=1}^N\lambda_i-\displaystyle\sum_{i=1}^N\lambda_iy_i\omega^Tx_i+\displaystyle\sum_{i=1}^N\lambda_iy_ib\\={\frac 1 2}\omega^T\omega+\displaystyle\sum_{i=1}^N\lambda_i-\displaystyle\sum_{i=1}^N\lambda_iy_i\omega^Tx_i L(ω,b,λ)=21ωTω+i=1∑Nλi−i=1∑Nλiyi(ωTxi+b)=21ωTω+i=1∑Nλi−i=1∑NλiyiωTxi+i=1∑Nλiyib=21ωTω+i=1∑Nλi−i=1∑NλiyiωTxi
(3) 求 ∂ L ∂ ω = 0 {\frac {\partial L} {\partial \omega}}=0 ∂ω∂L=0
∂
L
∂
ω
=
1
2
⋅
2
⋅
ω
−
∑
i
=
1
N
λ
i
y
i
x
i
=
0
{\frac {\partial L} {\partial \omega}}={\frac 1 2}·2·\omega-\displaystyle\sum_{i=1}^N\lambda_iy_ix_i=0
∂ω∂L=21⋅2⋅ω−i=1∑Nλiyixi=0
则,
ω
=
∑
i
=
1
N
λ
i
y
i
x
i
\omega=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i
ω=i=1∑Nλiyixi
(4) 将 ω = ∑ i = 1 N λ i y i x i \omega=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i ω=i=1∑Nλiyixi代入到 L ( ω , b , λ ) L(\omega,b,\lambda) L(ω,b,λ)中
L ( ω , b , λ ) = 1 2 ( ∑ i = 1 N λ i y i x i ) T ( ∑ i = 1 N λ i y i x i ) + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i ( ∑ j = 1 N λ j y j x j ) T x i L(\omega,b,\lambda)={\frac 1 2}(\displaystyle\sum_{i=1}^N\lambda_iy_ix_i)^T(\displaystyle\sum_{i=1}^N\lambda_iy_ix_i)+\displaystyle\sum_{i=1}^N\lambda_i-\displaystyle\sum_{i=1}^N\lambda_iy_i(\displaystyle\sum_{j=1}^N\lambda_jy_jx_j)^Tx_i L(ω,b,λ)=21(i=1∑Nλiyixi)T(i=1∑Nλiyixi)+i=1∑Nλi−i=1∑Nλiyi(j=1∑Nλjyjxj)Txi
注意:
∵ λ i ∈ R , y i ∈ { − 1 , 1 } , x i ∈ R p \lambda_i\in\Reals,y_i\in\{-1,1\},x_i\in\Reals^p λi∈R,yi∈{−1,1},xi∈Rp
∴( ∑ i = 1 N λ i y i x i ) T = ∑ i = 1 N λ i y i x i T \displaystyle\sum_{i=1}^N\lambda_iy_ix_i)^T=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i^T i=1∑Nλiyixi)T=i=1∑NλiyixiT
∴ ω T ω = ( ∑ i N λ i y i x i T ) ⋅ ( ∑ j N λ j y j x j ) = ∑ i N ∑ j N λ i λ j y i y j x i T x j \omega^T\omega=(\displaystyle\sum_{i}^N\lambda_iy_ix_i^T)·(\displaystyle\sum_{j}^N\lambda_jy_jx_j)=\displaystyle\sum_{i}^N\displaystyle\sum_{j}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j ωTω=(i∑NλiyixiT)⋅(j∑Nλjyjxj)=i∑Nj∑NλiλjyiyjxiTxj
同理, ∑ i = 1 N λ i y i ( ∑ j = 1 N λ j y j x j ) T x i = ∑ i = 1 N λ i y i ∑ j = 1 N λ j y j x j T x i = ∑ i N ∑ j N λ i λ j y i y j x j T x i = ∑ i N ∑ j N λ i λ j y i y j x i T x j ⇐ x i T x j = x j T x i ∈ R \displaystyle\sum_{i=1}^N\lambda_iy_i(\displaystyle\sum_{j=1}^N\lambda_jy_jx_j)^Tx_i=\displaystyle\sum_{i=1}^N\lambda_iy_i\displaystyle\sum_{j=1}^N\lambda_jy_jx_j^Tx_i\\=\displaystyle\sum_{i}^N\displaystyle\sum_{j}^N\lambda_i\lambda_jy_iy_jx_j^Tx_i\\=\displaystyle\sum_{i}^N\displaystyle\sum_{j}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j\Larr x_i^Tx_j=x_j^Tx_i\in\Reals i=1∑Nλiyi(j=1∑Nλjyjxj)Txi=i=1∑Nλiyij=1∑NλjyjxjTxi=i∑Nj∑NλiλjyiyjxjTxi=i∑Nj∑NλiλjyiyjxiTxj⇐xiTxj=xjTxi∈R
发现上面两个结果一样!因此,可以约掉啦~
( ∑ i = 1 N λ i y i x i ) T ( ∑ i = 1 N λ i y i x i ) = ∑ i = 1 N λ i y i ( ∑ j = 1 N λ j y j x j ) T x i = ∑ i N ∑ j N λ i λ j y i y j x i T x j (\displaystyle\sum_{i=1}^N\lambda_iy_ix_i)^T(\displaystyle\sum_{i=1}^N\lambda_iy_ix_i)=\displaystyle\sum_{i=1}^N\lambda_iy_i(\displaystyle\sum_{j=1}^N\lambda_jy_jx_j)^Tx_i\\=\displaystyle\sum_{i}^N\displaystyle\sum_{j}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j (i=1∑Nλiyixi)T(i=1∑Nλiyixi)=i=1∑Nλiyi(j=1∑Nλjyjxj)Txi=i∑Nj∑NλiλjyiyjxiTxj
L
(
ω
,
b
,
λ
)
=
∑
i
=
1
N
λ
i
−
1
2
∑
i
N
∑
j
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
⇒
即
m
i
n
ω
,
b
L
(
ω
,
b
,
λ
)
L(\omega,b,\lambda)=\displaystyle\sum_{i=1}^N\lambda_i-{\frac 1 2}\displaystyle\sum_{i}^N\displaystyle\sum_{j}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j\xRightarrow{即} {min \atop \omega,b}L(\omega,b,\lambda)
L(ω,b,λ)=i=1∑Nλi−21i∑Nj∑NλiλjyiyjxiTxj即ω,bminL(ω,b,λ)
代入式(3)即,
(
4
)
{
m
a
x
λ
∑
i
=
1
N
λ
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
⇐
m
a
x
λ
m
i
n
ω
,
b
L
(
ω
,
b
,
λ
)
s
.
t
.
λ
i
⩾
0
,
∑
i
=
1
N
λ
i
y
i
=
0
(4)\begin{cases}{max \atop \lambda}\displaystyle\sum_{i=1}^N\lambda_i-{\frac 1 2}\displaystyle\sum_{i=1}^N\displaystyle\sum_{j=1}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j\Larr {max \atop \lambda}{min \atop \omega,b}L(\omega,b,\lambda) \\s.t.\space \lambda_i\geqslant0,\displaystyle\sum_{i=1}^N\lambda_iy_i=0 \end{cases}
(4)⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧λmaxi=1∑Nλi−21i=1∑Nj=1∑NλiλjyiyjxiTxj⇐λmaxω,bminL(ω,b,λ)s.t. λi⩾0,i=1∑Nλiyi=0
(5) 对偶问题的最终优化式
最优化问题常由
m
i
n
min
min表示
(
5
)
{
m
i
n
λ
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
N
λ
i
s
.
t
.
λ
i
⩾
0
,
∑
i
=
1
N
λ
i
y
i
=
0
(5)\begin{cases}{min \atop \lambda}{\frac 1 2}\displaystyle\sum_{i=1}^N\displaystyle\sum_{j=1}^N\lambda_i\lambda_jy_iy_jx_i^Tx_j-\displaystyle\sum_{i=1}^N\lambda_i \\s.t.\space \lambda_i\geqslant0,\displaystyle\sum_{i=1}^N\lambda_iy_i=0 \end{cases}
(5)⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧λmin21i=1∑Nj=1∑NλiλjyiyjxiTxj−i=1∑Nλis.t. λi⩾0,i=1∑Nλiyi=0
5. KKT条件求解对偶问题
定理:原问题和对偶问题具有强对偶关系 ⇔ 充 要 条 件 \xLeftrightarrow{充要条件} 充要条件 满足KKT条件
拉格朗日方程(上面第2点):
L ( ω , b , λ ) = 1 2 ω T ω + ∑ i = 1 N λ i ( 1 − y i ( ω T x i + b ) ) L(\omega,b,\lambda)={\frac 1 2}{\omega^T}\omega+\displaystyle\sum_{i=1}^N\lambda_i(1-y_i(\omega^Tx_i+b)) L(ω,b,λ)=21ωTω+i=1∑Nλi(1−yi(ωTxi+b)), λ i ⩾ 0 \lambda_i\geqslant0 λi⩾0根据定理可直接得到该问题的KKT(Karush-Kuhn-Tucker)条件:
{ ∂ L ∂ ω = 0 , ∂ L ∂ b = 0 , ∂ L ∂ λ = 0 λ i ⩾ 0 ⇒ 拉 格 朗 日 乘 子 法 的 要 求 1 − y i ( ω T x i + b ) ⩽ 0 ⇒ 上 面 第 2 点 解 释 了 λ i ( 1 − y i ( ω T x i + b ) ) = 0 ⇒ 此 时 , L ( ω , b , λ ) = 1 2 ω T ω , 为 最 大 值 ; 松 弛 互 补 条 件 , 求 解 b ∗ \begin{cases}{\frac {\partial L}{\partial \omega}}=0,{\frac {\partial L}{\partial b}}=0,{\frac {\partial L}{\partial \lambda}}=0 \\\lambda_i\geqslant0\Rarr 拉格朗日乘子法的要求 \\1-y_i(\omega^Tx_i+b)\leqslant0\Rarr 上面第2点解释了 \\\lambda_i(1-y_i(\omega^Tx_i+b))=0\Rarr此时,L(\omega,b,\lambda)={\frac 1 2}\omega^T\omega,为最大值;松弛互补条件,求解b^* \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧∂ω∂L=0,∂b∂L=0,∂λ∂L=0λi⩾0⇒拉格朗日乘子法的要求1−yi(ωTxi+b)⩽0⇒上面第2点解释了λi(1−yi(ωTxi+b))=0⇒此时,L(ω,b,λ)=21ωTω,为最大值;松弛互补条件,求解b∗
根据KKT条件,可求出最优的 ω ∗ , b ∗ \omega^*,b^* ω∗,b∗。
凸优化中对偶问题详解,尤其解释了什么是KKT条件。
(1) 最优解 ω ∗ = ∑ i = 1 N λ i y i x i \omega^*=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i ω∗=i=1∑Nλiyixi
就是之前(3)中 ∂ L ∂ ω = 0 {\frac {\partial L} {\partial \omega}}=0 ∂ω∂L=0的结果。
(2) 最优解 b ∗ = y k − ∑ i N λ i y i x i T x k b^*=y_k-\displaystyle\sum_i^N\lambda_iy_ix_i^Tx_k b∗=yk−i∑NλiyixiTxk
假设
∃
(
x
k
,
y
k
)
,
s
.
t
.
1
−
y
k
(
ω
T
x
k
+
b
)
=
0
\exist (x_k,y_k),\space s.t.\space 1-y_k(\omega^Tx_k+b)=0
∃(xk,yk), s.t. 1−yk(ωTxk+b)=0,即
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk)为支持向量,
ω
T
x
k
+
b
∈
{
−
1
,
1
}
\omega^Tx_k+b\in\{-1,1\}
ωTxk+b∈{−1,1}。
由
y
k
(
ω
T
x
k
+
b
)
=
1
∵
y
k
=
±
1
,
y
k
2
=
1
∴
y
k
2
(
ω
T
x
k
+
b
)
=
y
k
∴
ω
T
x
k
+
b
=
y
k
∴
b
∗
=
y
k
−
ω
T
x
k
=
y
k
−
(
ω
∗
)
T
x
k
=
y
k
−
∑
i
=
1
N
λ
i
y
i
x
i
T
x
k
由y_k(\omega^Tx_k+b)=1 \\∵y_k=±1,y_k^2=1 \\∴y_k^2(\omega^Tx_k+b)=y_k \\∴\omega^Tx_k+b=y_k \\∴b^*=y_k-\omega^Tx_k=y_k-(\omega^*)^Tx_k=y_k-\displaystyle\sum_{i=1}^N\lambda_iy_ix_i^Tx_k
由yk(ωTxk+b)=1∵yk=±1,yk2=1∴yk2(ωTxk+b)=yk∴ωTxk+b=yk∴b∗=yk−ωTxk=yk−(ω∗)Txk=yk−i=1∑NλiyixiTxk
(3) 根据 w ∗ , b ∗ w^*,b^* w∗,b∗得出超平面 w ∗ x + b ∗ w^*x+b^* w∗x+b∗
- f ( x ) = s i g n ( ( w ∗ ) T x + b ∗ ) f(x)=sign((w^*)^Tx+b^*) f(x)=sign((w∗)Tx+b∗)
- w ∗ = ∑ i = 1 N λ i y i x i w^*=\displaystyle\sum_{i=1}^N\lambda_iy_ix_i w∗=i=1∑Nλiyixi可看做是 D a t a = { ( x i , y i ) } i = 1 N , x i ∈ R p , y i ∈ { − 1 , + 1 } Data=\{(x_i, y_i)\}_{i=1}^N,x_i\in\R^p,y_i\in\{-1,+1\} Data={(xi,yi)}i=1N,xi∈Rp,yi∈{−1,+1}的线性组合
- λ i \lambda_i λi只对支持向量才有意义,即 1 − y i ( ω T x i + b ) = 0 1-y_i(\omega^Tx_i+b)=0 1−yi(ωTxi+b)=0上的点,此时, λ i ⩾ 0 \lambda_i\geqslant0 λi⩾0;对于非支持向量不起作用,此时 λ i = 0 \lambda_i=0 λi=0。














 7925
7925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









