







📌数据库-基础知识
- 存储引擎和体系结构
- InnoDB 四大特性知道吗?
- mysql的引擎有哪些?
- InnoDB 和 MyISAM 的区别?
- 怎么设计数据库表
- 项目中设计SQL表的设计原则
- 数据库的NF范式
- 数据库三范式
- 数据库用过哪些?
- 除了MySQL还用过什么数据库?
- Mysql, redis存储上的区别
- 关系型数据库和非关系型数据库区别?
- 有用过什么关系型数据库吗
- mysql表示时间的类型你知道有哪些?
- 怎么用MySQL命令行进行大量访问测试
- 怎么验证sql写的没有问题
- 16、select * from profile limit 800000,20 会有什么问题?怎么解决?
- 如何从百万级别的表中查出想要的记录?
- 如果一个数据库表中,是支付信息,已支付完成的信息不再改动,主要是查询操作。未支付完成的信息会有增删改查。数据表规模很大,怎么优化效率
- 数据库增删查改的幂等性
Java后端各科最全八股自用整理,获取方式见:
存储引擎和体系结构
InnoDB 四大特性知道吗?
插入缓冲(insert buffer):
- 索引是存储在磁盘上的,所以对于索引的操作需要涉及磁盘操作。如果我们使用自增主键,那么在插入主键索引(聚簇索引)时,只需不断追加即可,不需要磁盘的随机 I/O。但是如果我们使用的是普通索引,大概率是无序的,此时就涉及到磁盘的随机 I/O,而随机I/O的性能是比较差的(Kafka 官方数据:磁盘顺序I/O的性能是磁盘随机I/O的4000~5000倍)。
- 因此,InnoDB 存储引擎设计了 Insert Buffer ,对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池(Buffer pool)中,若在,则直接插入;若不在,则先放入到一个 Insert Buffer 对象中,然后再以一定的频率和情况进行 Insert Buffer 和辅助索引页子节点的 merge(合并)操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
- 插入缓冲的使用需要满足以下两个条件:
1)索引是辅助索引;
2)索引不是唯一的。 - 因为在插入缓冲时,数据库不会去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有随机读取的情况发生,从而导致 Insert Buffer 失去了意义。
二次写(double write):
- 脏页刷盘风险:InnoDB 的 page size一般是16KB,操作系统写文件是以4KB作为单位,那么每写一个 InnoDB 的 page 到磁盘上,操作系统需要写4个块。于是可能出现16K的数据,写入4K 时,发生了系统断电或系统崩溃,只有一部分写是成功的,这就是 partial page write(部分页写入)问题。这时会出现数据不完整的问题。
- 这时是无法通过 redo log 恢复的,因为 redo log 记录的是对页的物理修改,如果页本身已经损坏,重做日志也无能为力。
- doublewrite 就是用来解决该问题的。doublewrite 由两部分组成,一部分为内存中的 doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间中连续的128个页,即2个区(extent),大小也是2M。
- 为了解决 partial page write 问题,当 MySQL 将脏数据刷新到磁盘的时候,会进行以下操作:
1)先将脏数据复制到内存中的 doublewrite buffer
2)之后通过 doublewrite buffer 再分2次,每次1MB写入到共享表空间的磁盘上(顺序写,性能很高)
3)完成第二步之后,马上调用 fsync 函数,将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写)。 - 如果操作系统在将页写入磁盘的过程中发生崩溃,InnoDB 再次启动后,发现了一个 page 数据已经损坏,InnoDB 存储引擎可以从共享表空间的 doublewrite 中找到该页的一个最近的副本,用于进行数据恢复了。
自适应哈希索引(adaptive hash index):
- 哈希(hash)是一种非常快的查找方法,一般情况下查找的时间复杂度为 O(1)。但是由于不支持范围查询等条件的限制,InnoDB 并没有采用 hash 索引,但是如果能在一些特殊场景下使用 hash 索引,则可能是一个不错的补充,而 InnoDB 正是这么做的。
- 具体的,InnoDB 会监控对表上索引的查找,如果观察到某些索引被频繁访问,索引成为热数据,建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive)的。自适应哈希索引通过缓冲池的 B+ 树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB 会自动根据访问的频率和模式来为某些页建立哈希索引。
预读(read ahead):
- InnoDB 在 I/O 的优化上有个比较重要的特性为预读,当 InnoDB 预计某些 page 可能很快就会需要用到时,它会异步地将这些 page 提前读取到缓冲池(buffer pool)中,这其实有点像空间局部性的概念。
- 空间局部性(spatial locality):如果一个数据项被访问,那么与他地址相邻的数据项也可能很快被访问。
- InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)。
- 其中,线性预读以 extent(块,1个 extent 等于64个 page)为单位,而随机预读放到以 extent 中的 page 为单位。线性预读着眼于将下一个extent 提前读取到 buffer pool 中,而随机预读着眼于将当前 extent 中的剩余的 page 提前读取到 buffer pool 中。
- 线性预读(Linear read-ahead):线性预读方式有一个很重要的变量 innodb_read_ahead_threshold,可以控制 Innodb 执行预读操作的触发阈值。如果一个 extent 中的被顺序读取的 page 超过或者等于该参数变量时,Innodb将会异步的将下一个 extent 读取到 buffer pool中,innodb_read_ahead_threshold 可以设置为0-64(一个 extend 上限就是64页)的任何值,默认值为56,值越高,访问模式检查越严格。
- 随机预读(Random read-ahead): 随机预读方式则是表示当同一个 extent 中的一些 page 在 buffer pool 中发现时,Innodb 会将该 extent 中的剩余 page 一并读到 buffer pool中,由于随机预读方式给 Innodb code 带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃。要启用此功能,请将配置变量设置 innodb_random_read_ahead 为ON。
mysql的引擎有哪些?

在上述列表中,我们最常用的存储引擎有以下 3 种:
1.InnoDB
2.MyISAM
3.MEMORY
- 内存型数据库引擎,所有的数据都存储在内存中,因此它的读写效率很高,但 MySQL 服务重启之后数据会丢失。它同样不支持事务、不支持外键。MEMORY 支持 Hash 索引或 B 树索引,其中 Hash 索引是基于 key 查询的,因此查询效率特别高,但如果是基于范围查询的效率就比较低了。而前面两种存储引擎是基于 B+树的数据结构实现了。
- 优缺点分析
MEMORY 读写性能很高,但 MySQL 服务重启之后数据会丢失,它不支持事务和外键。适用场景是读写效率要求高,但对数据丢失不敏感的业务场景。
InnoDB 和 MyISAM 的区别?
1)事务:MyISAM不支持,InnoDB支持
2)锁类型:MyISAM只有表锁,InnoDB支持行锁、表锁
3)缓存:MyISAM只缓存索引,InnoDB缓存索引和数据
4)主键:MyISAM可以没有;InnoDB必须有,用于实现聚簇索引
5)MyISAM采用非聚集索引,InnoDB采用聚集索引
8)InnoDB支持hash索引,MyISAM不支持
6)记录存储顺序:InnoDB按主键大小有序插入;MyISAM按记录插入顺序保存
7)MyISAM存储表的总行数;InnoDB不存储总行数;
9)外键:InnoDB支持;MyISAM不支持
10)InnoDB关注事务;MyISAM关注性能
11)适用场景:【从数据结构出发考虑!】
- MyISAM适合:插入不频繁,查询非常频繁,如果执行大量的SELECT,MyISAM是更好的选择,没有事务。
- InnoDB适合:可靠性要求比较高,或者要求事务;表更新和查询都相当的频繁,大量的INSERT或UPDATE
怎么设计数据库表
项目中设计SQL表的设计原则
数据库的NF范式
数据库三范式

【粒度越来越小!一般第三范式就可】
- 第一范式(1NF):属性不可再分。即每个属性都是不可分的原子项。
- 第二范式(2NF):属性完全依赖主键。即每个非主键属性都完全依赖于主键,而不依赖于候选键的一部分。 【部分依赖】
- 第三范式(3NF):非主键属性不依赖于其他非主键属性。即每个非主键属性都不依赖于其他非主键属性。 【传递依赖】
- 巴斯-科德范式(BCNF):属性完全依赖于候选键。即每个非主属性都完全依赖于候选键,而不是依赖于候选键的一部分。
- 第四范式(4NF):多值依赖。即如果一个关系表中有多个多值依赖关系,应该将其拆分为多个关系表。
- 第五范式(5NF):联合依赖。即如果一个关系表中有多个联合依赖关系,应该将其拆分为多个关系表。
数据库用过哪些?
除了MySQL还用过什么数据库?
Mysql, redis存储上的区别
关系型数据库和非关系型数据库区别?
- 成本:Nosql数据库很容易部署,基本上是开源软件,无需像Oracle那样花费大量成本购买,比关系数据库便宜。
- 查询速度:Nosql数据库将数据存储在高速缓存中,不需要对SQL层进行分析。关系数据库在硬盘上存储数据,自然的查询速度远比Nosql数据库慢。
- 存储数据的格式:Nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
- 扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。Nosql基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
- 持久存储:Nosql不便用于持久存储,海量数据的持久存储,还需要关系型数据库
- 数据一致性:非关系数据库通常强调数据的最终一致性,而不是像关系数据库那样强数据一致性,以及从非关系数据库读取的数据可能仍处于中间状态,Nosql不提供对事务的处理。
有用过什么关系型数据库吗
当涉及关系型数据库时,常见的一些数据库包括:
- MySQL:一个流行的开源关系型数据库管理系统,广泛用于Web应用程序开发。
- PostgreSQL:一个强大的开源关系型数据库管理系统,具有丰富的功能和可扩展性。
- Microsoft SQL Server:由微软开发的关系型数据库管理系统,用于Windows平台。
- Oracle Database:由甲骨文公司开发的关系型数据库管理系统,用于大型企业应用程序。
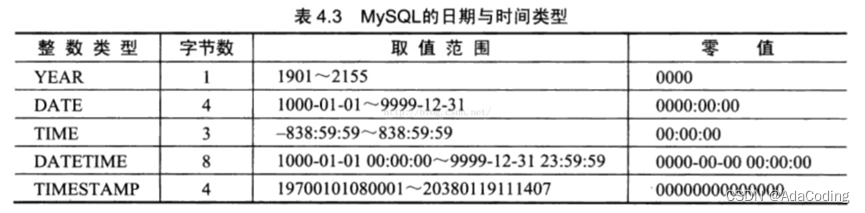
mysql表示时间的类型你知道有哪些?
https://bbs.huaweicloud.com/blogs/336102
MySQL有多种表示日期和时间的数据类型,不同的版本可能有所差异,MySQL8.0版本支持的日期和时间类型主要有:YEAR类型、TIME类型、DATE类型、DATETIME类型和TIMESTAMP类型。
• YEAR类型通常用来表示年
• DATE类型通常用来表示年、月、日
• TIME类型通常用来表示时、分、秒
• DATETIME类型通常用来表示年、月、日、时、分、秒
• TIMESTAMP类型通常用来表示带时区的年、月、日、时、分、秒
怎么用MySQL命令行进行大量访问测试
怎么验证sql写的没有问题
优化软件
16、select * from profile limit 800000,20 会有什么问题?怎么解决?
https://blog.csdn.net/jushisi/article/details/112960017
select * from table limit 0,10扫描满足条件的10行,返回10行。- 但当执行
select * from table limit 800000,20的时候数据读取就很慢,limit 800000,20的意思扫描满足条件的800020行,扔掉前面的800000行,返回最后的20行,可想而知这时会很慢,测试了一下达到37.44秒之久。 - 利用表的覆盖索引来加速分页查询。因为利用索引查找有优化算法,且数据就在查询索引上面,不用再回表查询数据行,这样节省了很多时间。
select * from product order by id limit 800000, 20
方法1:子查询,id>=的形式:
select * from product
where ID >= ( select id from product order by id limit 800000,1 ) limit 20
方法2:利用join(推荐这种方法) 取交集
select * from product a
JOIN ( select id from product order by id limit 800000,20 ) b on a.id = b.id
如何从百万级别的表中查出想要的记录?
https://bbs.huaweicloud.com/blogs/339717
1、使用分页查询:mysql在数据量大的情况下分页起点越大查询速度越慢,100万条起的查询速度已经需要7秒钟。这是一个我们无法接受的数值!
2、使用子查询改进;
3、使用索引表改进。
如果一个数据库表中,是支付信息,已支付完成的信息不再改动,主要是查询操作。未支付完成的信息会有增删改查。数据表规模很大,怎么优化效率
数据库增删查改的幂等性
同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。所有的安全方法也都是幂等的。
- 在正确实现的条件下,GET,HEAD,PUT和DELETE等方法都是幂等的,而POST 方法不是。
更多后端全部八股点击👉👉【闲鱼】https://m.tb.cn/h.5yHpgkY?tk=O8bhWpn1NBD CZ8908 「我在闲鱼发布了【京985计算机硕士自用后端八股文出售,不同于市面上的几块钱八】」
点击链接直接打开
Java后端各科最全八股自用整理,获取方式见:
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣
欢迎专注我的公众号AdaCoding 和 Github:AdaCoding123
















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









