









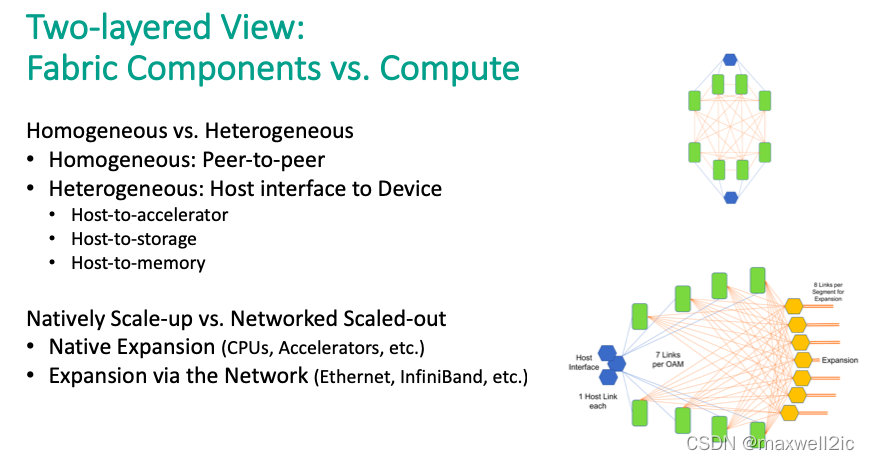
Background
- 异构计算系统中如何扩展cpu-加速器-存储的互联规模
- 扩大规模之后如何维持编程模型的简洁性和易用性
- 增加互联之后如何提高数据通信的效率(同时减少功耗)

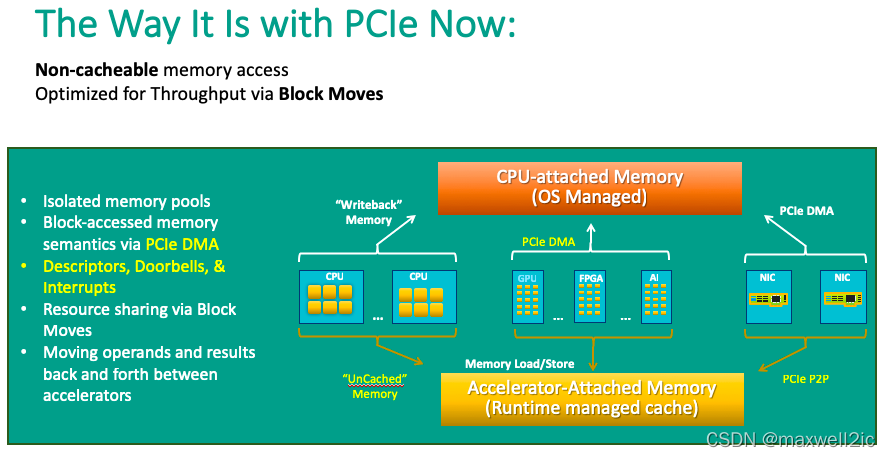
当前PCIe的做法不支持cacheable的访存方式;通过DMA进行大数据块搬运来提升带宽利用率。
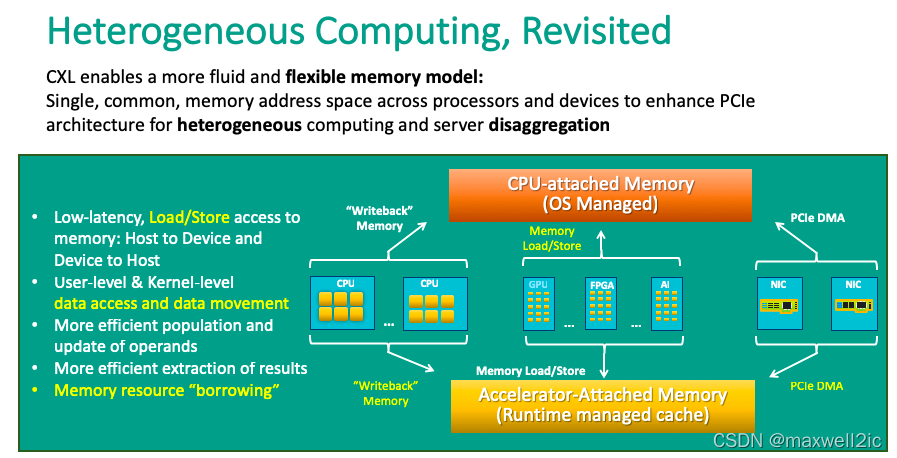
而CXL的做法则提供了更灵活的编程模型。
CXL Introduction
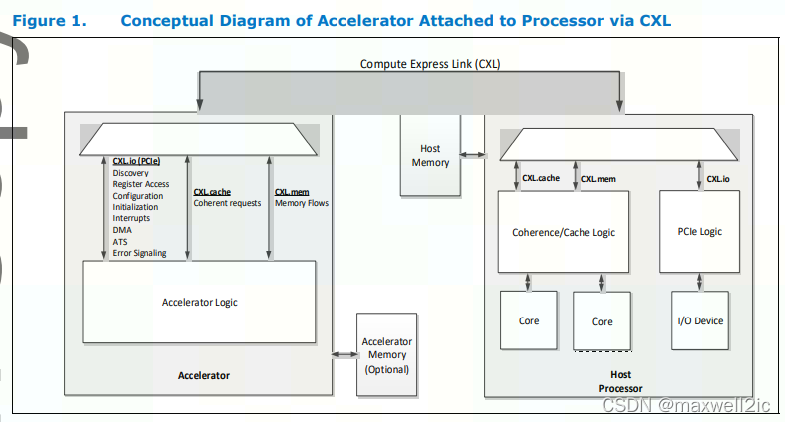
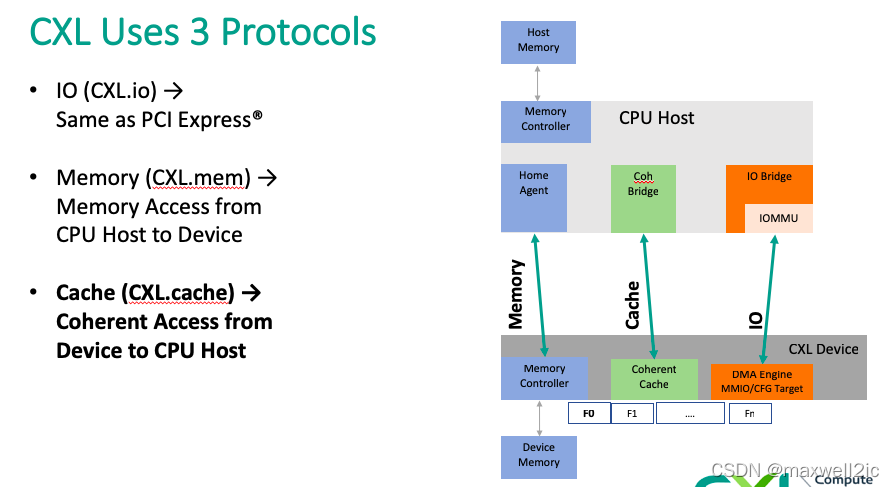
CXL (Compute Express Link)是一种支持加速器和存储设备的动态多协议技术。CXL在基于包交换的链路上提供如下3中协议操作:
- I/O 操作与PCIe类似,称为CXL.io,主要用于发现和枚举设备,报告错误,以及设备HPA(host physical address)的分配;
- 高速缓存操作,称为CXL.cache
- 存储操作,称为CXL.mem
CXL2.0向前兼容CXL1.1,并增加了对hot-plug, security enhancements, persistent memory support, memory error reporting, and telemetry的支持。并且CXL2.0增加了Switch的支持。
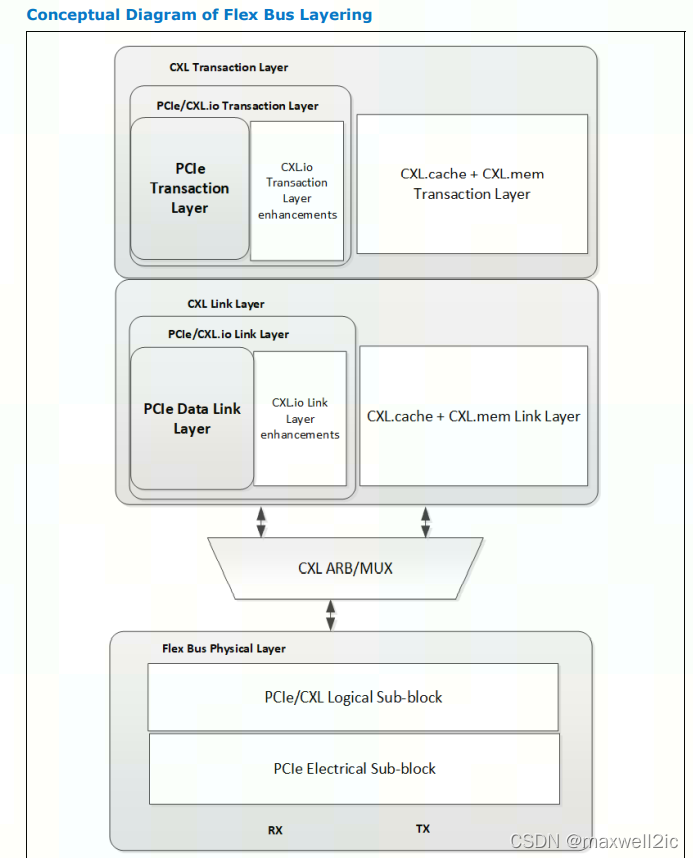
CXL协议通过引入Flex Bus Layer来兼容native PCIe或者CXL协议。并且在链路枚举阶段就需要协商决定Link工作在native PCIe还是CXL协议。
Flex Bus结构存在于CXL的多层协议中。Trans层和Data Link层将CXL.io与CXL.mem, CXL.cache分成独立的处理逻辑。CXL ARB/MUX可以交织地传输两种业务流。PCIe Trans层和Data Link层协议的实现是可选的,它们可以被融合进CXL.io的逻辑中。
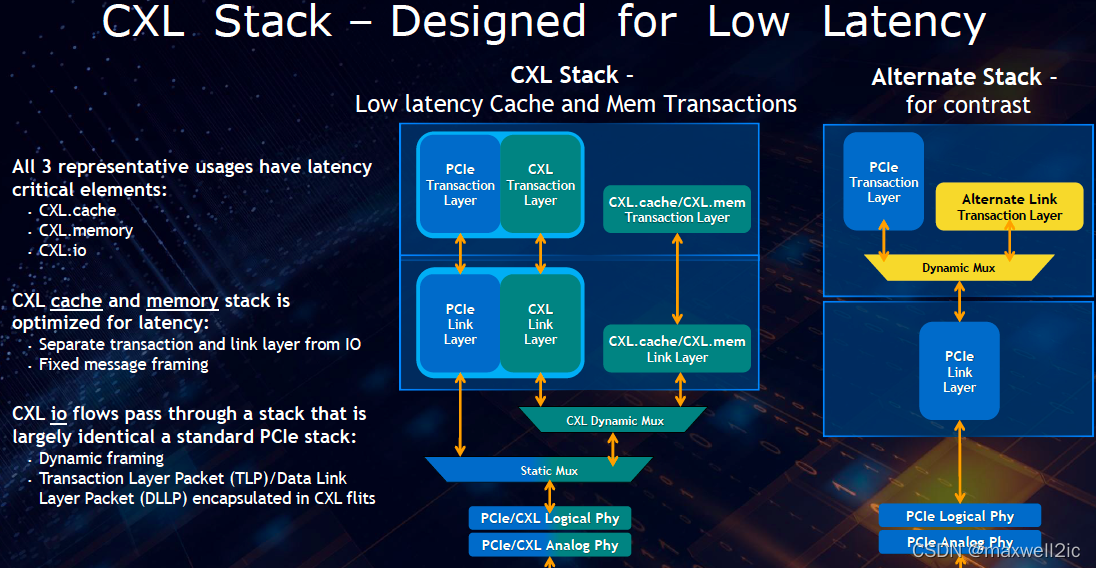
这种CXL Stack提供了低latency的cache/mem传输协议。
CXL Architecture
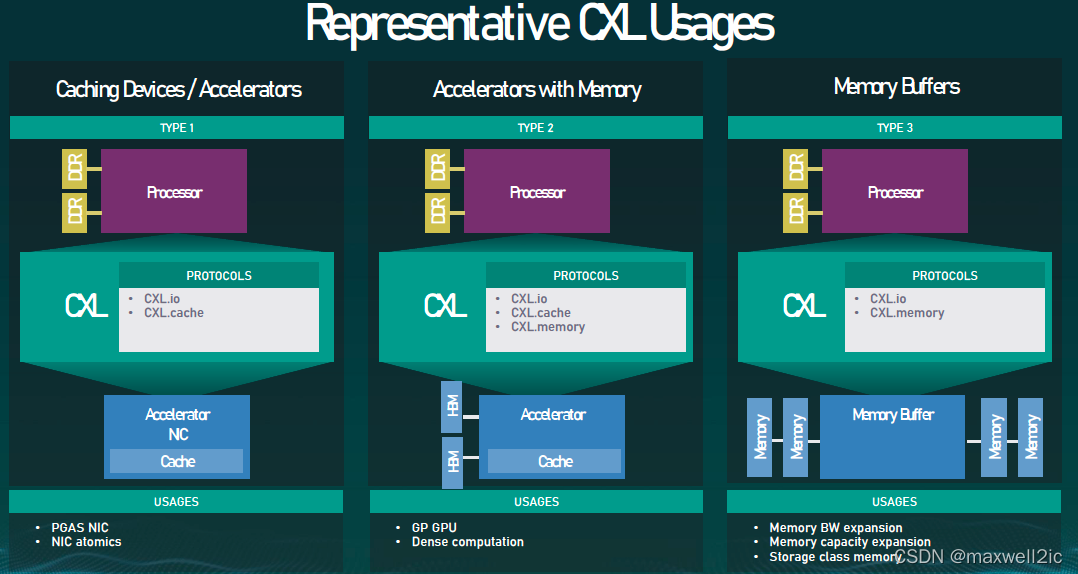
CXL.cache和CXL.mem是可选实现的协议特性,根据CXL Device实现的协议特性组合,CXL Device可以分为3种:
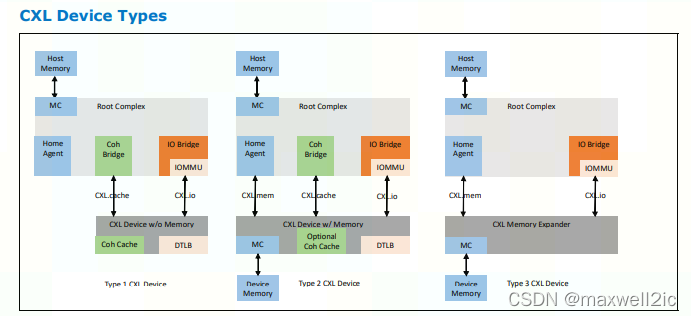
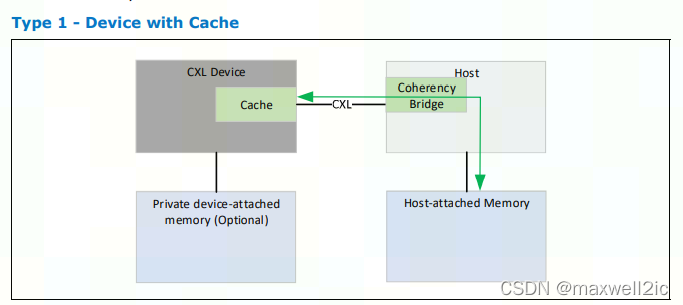
Type 1 CXL Device
如果对于某一类设备,标准的生产者-消费者编程模型很难满足它们的需求,比如设备需要实现的atomic操作是标准PCIe atomic操作无法实现的,那么Type 1 Device可以为其提供一套与Host侧的cache维持一致性的简单手段,并且cache大小不用受限于Host的snoop flitering能力。
基于此类实现,软件可以选择任意地编程模型或无限制地实现atomic操作。
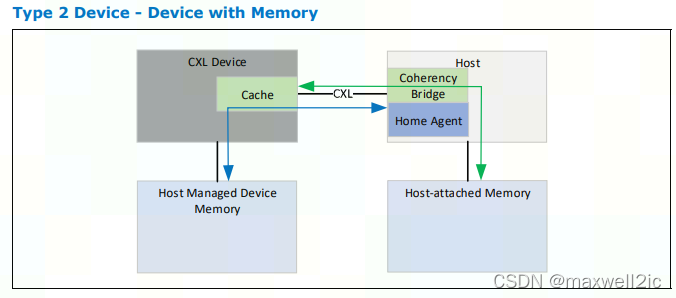
Type 2 CXL Device
此类CXL设备为Host提供手段可以直接把指令push进device memory并直接从device memory中读取运算结果。
协议把coherent system address mapped device-attached memory称为Host-managed Device Memory(HDM)。而把PCIe Device独立访问管理的存储空间称为traditional IO/PCIe Private Device Memory (PDM)。
PDM存在很明显的缺点就是在host memory和device-attached memory之间存在大量的数据copy。
Bias Based Coherency Model
CXL提供了2种运行HDM的编程模型:
- Host-bias:当一个device-attached memory处于host-bias-state时,这块memory表现地和host memory一样,如果device需要访问这块memory地址,则需要向host发送request,并由host来解决coherency问题。
- Device-bias:当一个device-attached memory处于device-bias-state时,host可以向device保证其cache内部没有缓存这部分memory的内容。也就是说device访问这块memory可以不需要向host发送request。
通过bias-based model,可以保证:
- Device-attached memory可以保证与host的cache一致性
- 保证device访问自己的memory的带宽不会因为一致性而收到明显影响
- 帮助host简化访问device memory的方式,host可以统一使用load-store的方式访问device memory,并且不需要软件关注一致性问题
为了保证上述bias-based model可以运行,type 2 device需要实现:
- 实现一个bias cache,以页表为粒度(e.g., 1b per 4KB page)记录bias table
- 实现一个TA(transition agent),用于bias state的切换,主要用于把host cache中属于该页表的缓存刷回memory(This essentially looks like a DMA engine for “cleaning up” pages, which essentially means to flush the host’s caches for lines belonging to that page.
- 实现对local memory进行load-store的支持(Build support for basic load and store access to accelerator local memory for the benefit of the Host.)
从上述特性中可以看出CXL的一致性model是不对称的,这样可以解决device访问local memory的带宽问题。
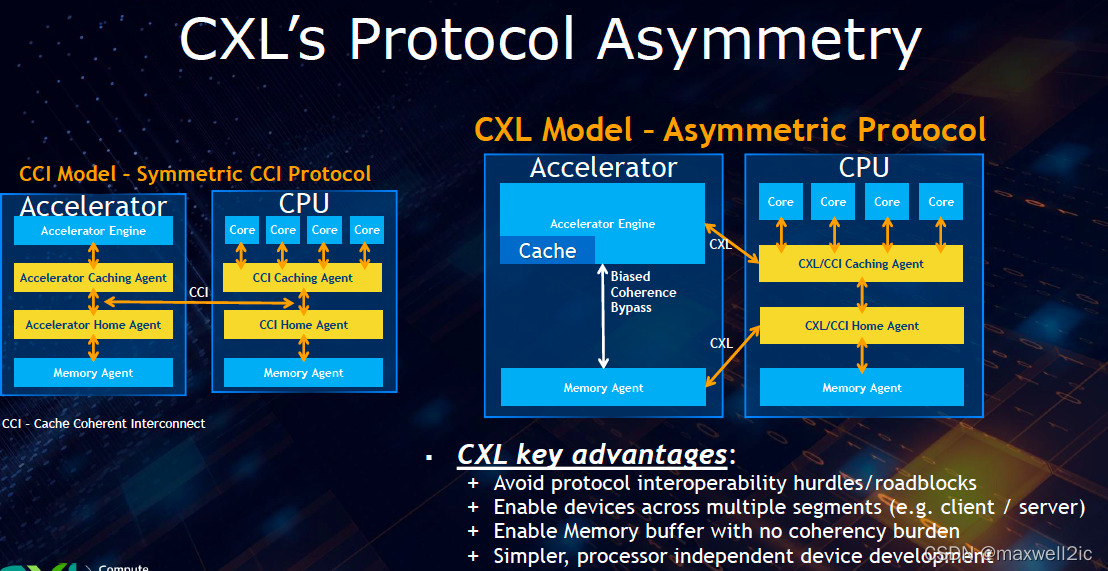
Host Bias
Host Bias state主要用于主机向device下发指令或读取结果时,此时host访问device memory能获得较大的吞吐量(如下图蓝色数据流);而device访问自己的memory则会徒增延迟(如下图绿色数据流)
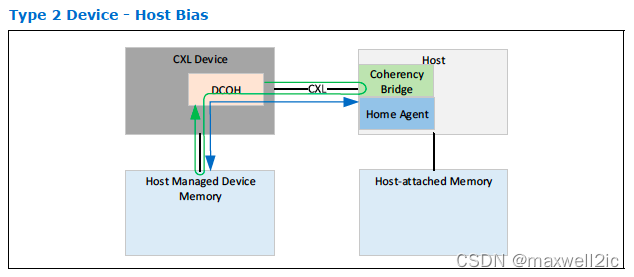
Device Bias
Device Bias state主要用于命令下发和结果完成之间的运算阶段,此时device通过片内总线访问自己的memory具有较大的带宽(如下图红色数据流);此时host也可以访问device-attached memory,但是有可能被device拒绝(如下图绿色数据流)。
Mode Management
CXL支持两种bias-state切换的方式,一种是软件切换,一种是硬件自动切换。
如果device不做bias切换相关的逻辑,则默认全都是host-bias-state,理论上device的所有访存都需要经过host。
Software Assisted Bias Mode Management
对于某些运算pattern非常规律的加速器,软件可以很明确地知道某个页表上现在正在运行什么任务(是host下发指令到device,还是device进行计算,还是host捞取结果),那么软件可以基于页表为粒度切换bias-state,从而对一致性的性能进行优化。
软件切换方式通常有以下特点:
- 在加速卡进行计算时,数据已经准备好了,此时software assistance可以发挥作用
- 如果数据没有事先存放到加速卡中,device通常能根据某些参考发送数据搬运的请求
- 对于device取数的时候,device需要能找到一些已经准备好的数据进行运算,否则它就会处于等待状态
- Device每空等待一轮,都会贡献到软件性能的恶化
- 一般加速器都掩盖不了取数的延迟
(说白了就是,如果软件不能非常好地设计加速器的pipeline,那软件切换这种方式就是自找苦吃)
Hardware Autonomous Bias Mode Management
软件切换对于一些简单的加速器是理想的,但对于实际应用中这种模式基本就是不可用的,并且软件需要频繁地感知去切换主机加速卡之间的coherency,这对于像pointer based, tree based or sparse data sets之类的问题简直就是灾难。
硬件切换方式有以下特点:
- 和软件切换一样以页表为粒度维护bias state
- 不需要软件在执行offload excitation之前去识别页表的bias属性
- 硬件可以动态切换
- 虽然这是一种硬件驱动的解决方案,硬件也可以只是暴露软件接口最终由软件触发bias切换(It is sufficient if hardware provides hints (e.g., “transition page X to bias Y now”) but leaves the actual transition operations under software control)
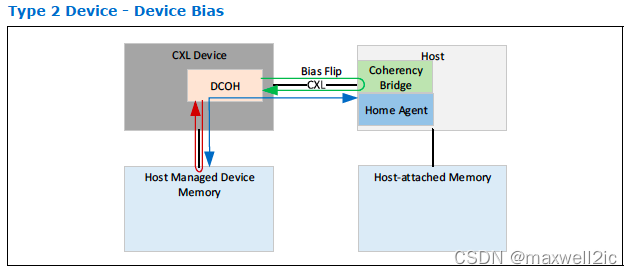
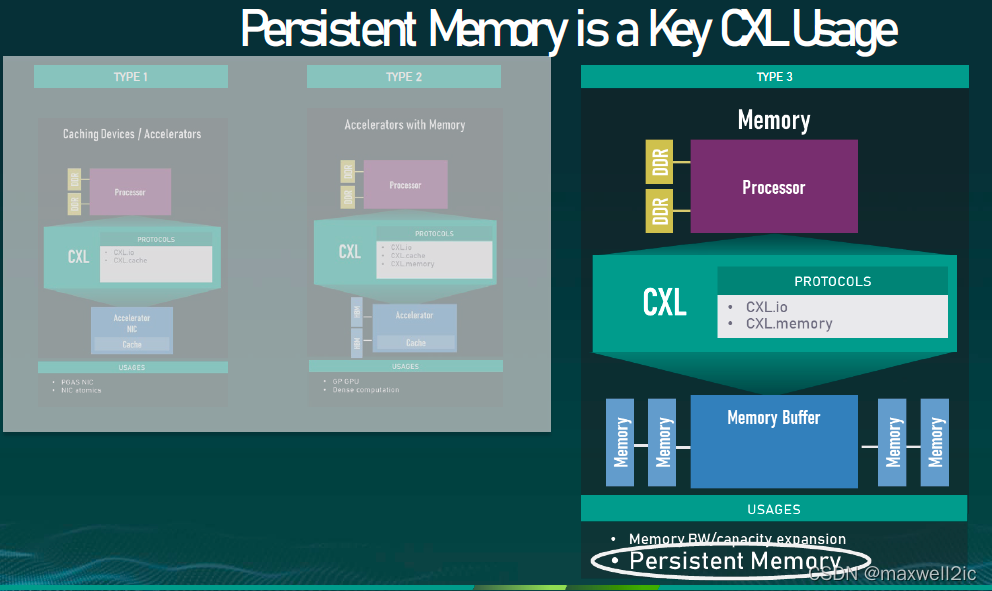
Type 3 CXL Device
Type 3设备不数据加速器,而更像是一个memory controller,host和device之间主要通过CXL.mem进行通信。
Type 3设备的一个主要应用就是对persistent memory的支持。
https://www.youtube.com/watch?v=FSMGQXVpf9M


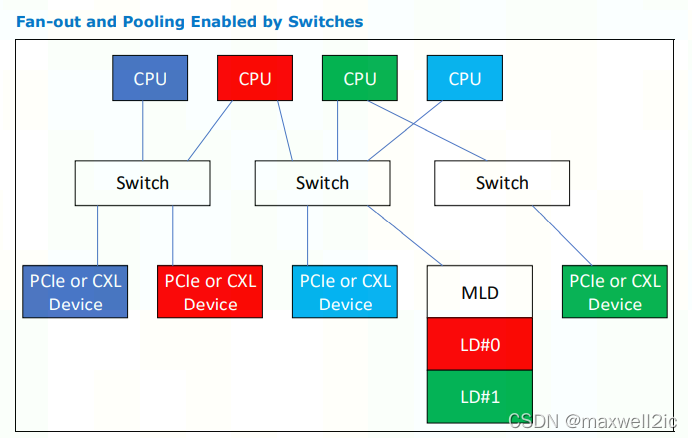
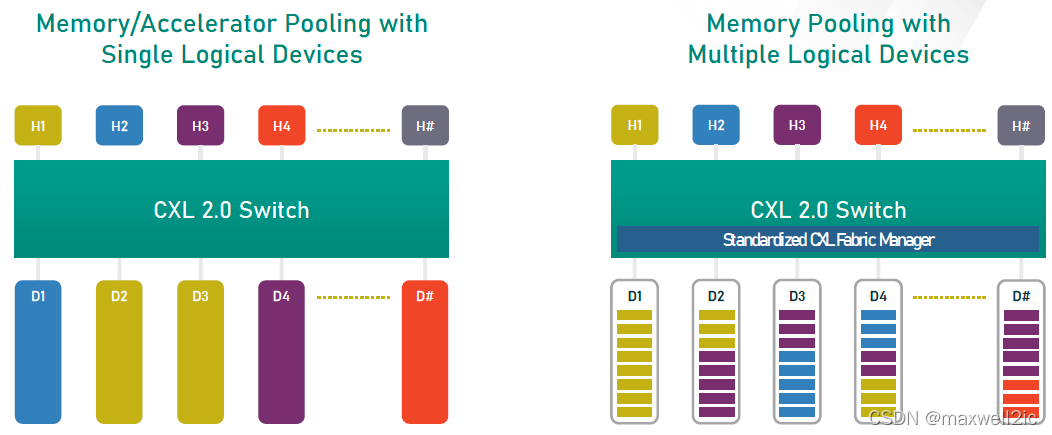
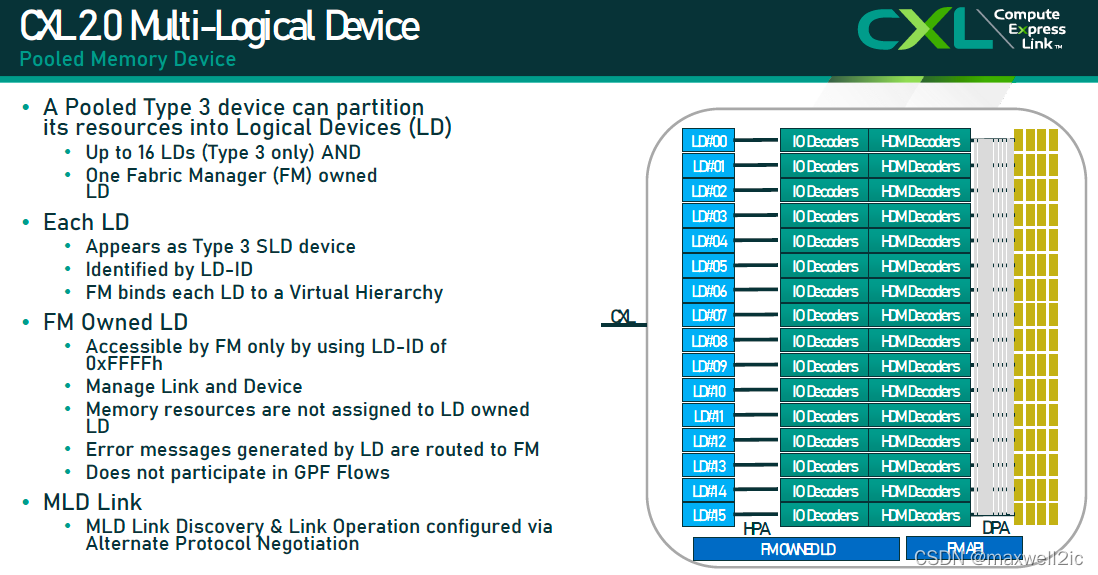
Multi Logical Device
CXL2.0只支持type 3的MLD (Multi-Logical Device),一个MLD可以最多划分为16个相互隔离的logical device,它们彼此之间通过Logical Device Identifier (LD-ID)区分。
该特性为memory polling提供了支持。
https://www.youtube.com/watch?v=FaIK_SFe_i8&t=7s

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









