







 偏差-方差分解是解释机器学习算法泛化性能的重要工具。偏差衡量预测值与真实值的差距,方差则表示预测值的离散程度。在训练集上,过于复杂的模型可能导致过拟合,简单的模型可能导致欠拟合。Error=Bias+Variance揭示了模型预测错误率的两个关键因素,偏差关乎模型复杂度不足,方差关乎模型过度复杂带来的不确定性。
偏差-方差分解是解释机器学习算法泛化性能的重要工具。偏差衡量预测值与真实值的差距,方差则表示预测值的离散程度。在训练集上,过于复杂的模型可能导致过拟合,简单的模型可能导致欠拟合。Error=Bias+Variance揭示了模型预测错误率的两个关键因素,偏差关乎模型复杂度不足,方差关乎模型过度复杂带来的不确定性。
对机器学习算法除了通过实验评估方法用某一个性能度量来估计泛化性能,我们还是关心如何解释算法的泛化性能。于是我们就要讨论下‘’偏差-方差分解‘’了。
数学上的偏差(bias)和方差(variance)
偏差:预测值与真实值之间的差距,差距越大,则其偏离真实值的程度越大。
方差:预测值的变化范围、离散程度,该值越大,其取值越离散。
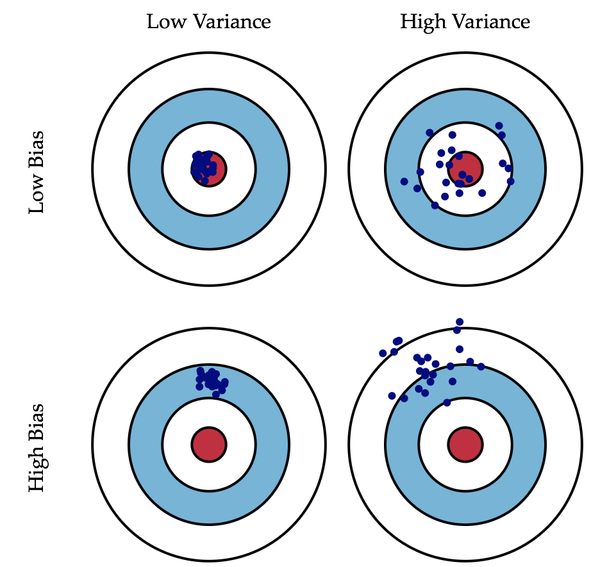
机器学习中bias和variance
首先,假设你知道训练集和测试集的关系。简单来讲是我们要在训练集上学习一个模型,然后拿到测试集去用,效果好不好要根据测试集的错误率来衡量。但很多时候,我们只能假设测试集和训练集的是符合同一个数据分布的,但却拿不到真正的测试数据。这时候怎么在只看到训练错误率的情况下,去衡量测试错误率呢?
由于训练样本很少(至少不足够多),所以通过训练集得到的模型,总不是真正正确的。(就算在训练集上正确率100%,也不能说明它刻画了真实的数据分布,要知道刻画真实的数据分布才是我们的目的,而不是只刻画训练集的有限的数据点)。而且,实际中,训练样本往往还有一定的噪音误差,所以如果太追求在训练集上的完美而采用一个很复杂的模型,会使得模型把训练集里面的误差都当成了真实的数据分布特征,从而得到错误的数据分布估计。这样的话,到了真正的测试集上就错的一塌糊涂了(这种现象叫过拟合)。但是也不能用太简单的模型,否则在数据分布比较复杂的时候,模型就不足以刻画数据分布了(体现为连在训练集上的错误率都很高,这种现象叫欠拟合)。过拟合表明采用的模型比真实的数据分布更复杂,而欠拟合表示采用的模型比真实的数据分布要简单。
在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为Error = Bias +Variance。这里的Error大概可以理解为模型的预测错误率,是有两部分组成的,一部分是由于模型太简单而带来的估计不准确的部分——偏差(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性——方差(Variance)
偏差(bias)和方差(variance)是统计学的概念,首先得明确,方差是多个模型间的比较,而非对一个模型而言的,对于单独的一个模型,比如说:
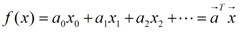
这样的一个给定了具体系数的估计函数,是不能说f(x)的方差是多少。而偏差可以是单个数据集中的,也可以是多个数据集中的,这个得看具体的定义。
方差和偏差一般来说,是从同一个数据集中,用科学的采样方法得到几个不同的子数据集,用这些子数据集得到的模型,就可以谈他们的方差和偏差的情况了。方差和偏差的变化一般是和模型的复杂程度成正比的,就像本文一开始那四张小图片一样,当我们一味的追求模型精确匹配,则可能会导致同一组数据训练出不同的模型,它们之间的差异非常大。这就叫做方差,不过他们的偏差就很小了。















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









