







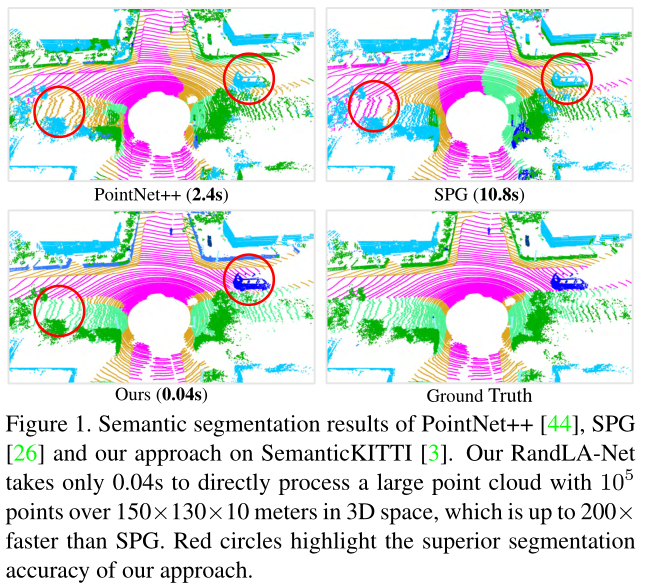
文章目录
前言
1. 为什么要做这个研究?
目前的语义分割模型由于其计算复杂度和内存占用量无法直接移植到大规模点云上,RandLA-Net主要研究大规模3D点云的高效语义分割问题。
2. 实验方法是什么样的?
文章首先探究了随机抽样在大规模3D点云上的计算速度和内存消耗方面的优势,由于随机采样可能会丢失关键特征点,所以作者设计了一个局部特征聚合模块,使用扩展的残差块将单个关键点的感受野经过2次扩展后能够接受 K 2 K^2 K2个邻居点的特征。
3. 得到了什么结果?
RandLA-Net在三个公开数据集室外Semantic3D和SemanticKITTI,以及室内S3DIS上进行了实验,均取得了不错的效果。
感想:对于小规模数据集如ModelNet40、ShapeNet上,使用随机抽样是不必要的,也如作者所说适合用在大规模点云上。另外,通过扩展的残差块来扩展每个中心点的感受野或许比较有用。
摘要
本文主要研究大规模3D点云的高效语义分割问题。大多数现有方法受限于开销昂贵的采样技术或计算量大的预处理/后处理步骤,只能运行于小规模点云。本文提出的RandLA-Net是一种高效且轻量级的神经架构,用于直接推断大规模点云的点语义。RandLA-Net的关键在于使用随机点采样,而不是更复杂的点选择方法。这样做计算和存储的效率会非常高,但随机采样可能会偶然丢弃关键特征。为了克服这一点,作者引入了一个新的局部特征聚合模块来逐步增强每个3D点的感受野,从而有效保留几何细节。大量实验表明,RandLA-Net可以在一次处理100万个点,比现有方法快200倍。此外,RandLA-Net在两个大规模基准Semantic3D和SemanticKITTI上明显超过了最先进的语义分割方法。
1.介绍
目前针对大规模点云的识别和分割存在以下限制:
- 点采样方法或计算昂贵,或内存不足。例如,广泛使用的最远点采样需要超过200秒才能对100万个点中的10%进行采样。
- 大多数现有的局部特征学习器通常依赖于计算昂贵的内核化或图构造,因此无法处理大量的点。
- 对于通常由数百个目标组成的大规模点云,由于感受野的大小有限,现有的局部特征学习器要么无法捕获复杂结构,要么效率低下。
本文设计了一个内存和计算效率高的神经网络架构,能够直接处理大规模的三维点云,而不需要任何预处理或后处理步骤,如体素化、块划分或图构造。该任务需要:
- 一个内存和计算高效的抽样方法来降采样大规模点云。
- 一个有效的局部特征学习器来增加感受野的大小,保留复杂的几何结构。
为此,作者首先系统的证明了随机采样是深层神经网络有效处理大规模点云的关键。然而,随机采样会丢弃关键信息,特别是对于点稀疏的对象。为了消除随机抽样潜在的不利影响,作者提出了一种新的有效的局部特征聚合模块,以捕获越来越小的点集上的复杂局部结构。
- 对于每个3D点,作者引入一个局部空间编码(LocSE)单元,明确地保留局部几何结构;
- 其次,利用注意力池化来自动保留有用的本地特征;
- 将多个LocSE单元和注意力池化堆叠成一个扩张的残差块,大大增加了每个点的有效感受野。
其中,所有的神经组件都是作为共享mlp实现的,因此具有显著的内存和计算效率。这里的共享mlp实际上就是使用Conv1d或Conv2d来替代mlp,大大减少了计算参数。
基于简单随机采样和有效的局部特征聚合器,RandLA-Net在大规模点云上比现有方法快200倍,而且在Semantic3D和SemanticKITTI基准测试上也超越了最先进的语义分割方法。
主要贡献在:
- 作者分析比较了现有的采样方法,认为随机采样是大规模点云上最适合的有效学习方法。
- 作者提出了一种有效的局部特征聚合模块,通过逐步增加每个点的感受野来保持复杂的局部结构。
- 作者在baseline上展示了显著的内存和计算增益,并在多个大规模基准上超越了最先进的语义分割方法。
2.相关工作
从3D点云中提取特征,最近的基于学习的方法主要包括基于投影的、基于体素的和基于点的方案。
- 基于投影和体素的网络。主要为了利用2D CNN的成功,问题在于几何细节可能会丢失,计算量大。
- 基于点的网络。局部特征学习方法大致可分为:邻近特征池化、图信息传递、基于核的卷积和基于注意力的聚合。这些网络在小点云上得到了很好的结果,但由于高昂的计算和内存成本,无法直接扩展到大型场景。与它们相比,RandLA-Net有三个特点:
- 它只依赖于网络内部的随机抽样,因此需要更少的内存和计算量;
- 提出的局部特征聚合器通过显式考虑局部空间关系和点特征,可以获得连续较大的感受野,从而对复杂的局部模型学习更加有效和鲁棒;
- 整个网络仅由共享的mlp组成,而不依赖于任何昂贵的操作,如图构造和核化,因此对于大规模点云非常高效。
- 大规模点云学习。RandLA-Net是端到端可训练的,不需要额外的前/后处理步骤。
3.RandLA-Net
3.1. Overview
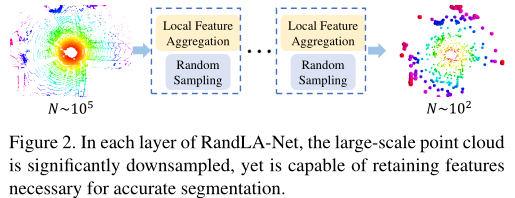
大规模点云包含了数百万的点,跨度达数百米,因此需要在模型中逐步高效地向下采样这些点,并保留有用的点特征。在RandLA-Net中,作者使用简单快速的随机抽样方法来降低点密度,同时使用局部特征聚合器来保留突出的特征。这使得网络在效率和性能之间实现了较好的平衡。
3.2. The quest for efficient sampling
现有的点采样方法大致可分为启发式方法和基于学习的方法,目前还没有适合大规模点云的标准采样策略。以下是对各种采样方法的相对优点和复杂性的分析比较。
(1)启发式采样
- 最远点采样(FPS):广泛用于小点集的语义分割,能够较好的覆盖整个点集,计算复杂度为 O ( N 2 ) O(N^2) O(N2)。对于大规模点云 ( 1 0 6 ) (10^6) (106),FPS在单个GPU上的处理时间高达200秒,这说明FPS并不适合大规模点云。
- 反密度重要性抽样(IDIS):根据每个点的密度对所有点重新排序,选取最上面的K个点,计算复杂度为 O ( N ) O(N) O(N),效率更高,对异常值也更敏感。处理 1 0 6 10^6 106个点大于需要10秒,在实时系统中任然太慢。
- 随机采样(RS):随机抽样从原始N个点中均匀选取K个点,计算复杂度是 O ( 1 ) O(1) O(1)。与输入点的总数无关,也就是说,RS方法是常数时间,因此具有内在的可伸缩性。与FPS和IDIS相比,无论输入点云的规模如何,随机采样的计算效率最高。处理 1 0 6 10^6 106只需要0.004秒。
(2)基于学习的采样
- 基于生成器的采样(GS):GS学习生成一个小点集,以近似表示原始大点集。然而,在推理阶段,为了将生成的子集与原始集进行匹配,通常会使用FPS,导致额外的计算。在实验中,采样 1 0 6 10^6 106个点中的10%需要1200秒。
- 基于连续松弛的采样(CRS):CRS方法使用重参数化技巧将采样操作松弛到一个连续域,进行端到端训练。具体来说,每个采样点都是基于整个点云的加权和来学习的。当用一次矩阵乘法同时采样所有新点时,会产生一个较大的权矩阵,导致难以承受的存储成本。例如,估计要占用超过300gb的内存才能采样 1 0 6 10^6
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









