






 超级会员免费看
超级会员免费看
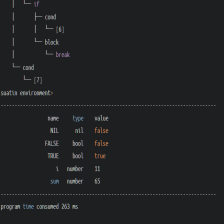
 本文介绍了基于C语言自制编程语言的词法分析器,通过添加特定前缀解决函数命名冲突问题,并提供了词法分析的Demo,包括头文件、源文件和测试案例,展示了运行结果。
本文介绍了基于C语言自制编程语言的词法分析器,通过添加特定前缀解决函数命名冲突问题,并提供了词法分析的Demo,包括头文件、源文件和测试案例,展示了运行结果。
前言
这本书的**************——至于其他特点我忘了,还记得的就是Demo中部分函数命名很简单、简单到与其他库函数产生冲突了。。。。
几个月前写(抄)的项目,后面的语法分析、制作C语言的面向对象、设计虚拟机等等内容没时间看下去了,只能讲讲废话了——
加前缀
C语言做的,因为没有前缀,所以一是不好看,二是容易冲突。只有一个解决办法,就是用专有的前缀。所以,我在每个函数、每个结构体、每个枚举、许多个宏的前面,都加上相同的前缀 hj
词法分析的Demo
头文件
//hj_common.h
/*
hj_common.h文件是整个项目的最底层的文件,这个文件里只有宏
整个项目是C写的,没有命名空间,所以很容易发生重命名!
规定:
1.变量、结构体、枚举、函数等,所有的非宏标识符前都要有前缀 hj
2.特殊宏前后都有两个下划线。特殊宏就是那些特别简单,分不清是枚举还是宏的
3.所有的前缀都是hj,把整个项目所有的hj都删除了基本
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 8667
8667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











