







在 ChatGPT 和类似的生成式人工智能模型推出后,很多人都在强调安全问题,政府也参与其中,OpenAI 甚至成立了一个超级协调小组,以阻止未来的人工智能失控,但由于对人工智能安全的发展方向存在分歧,该小组于今年 5 月解散。
今年 5 月,当 OpenAI 向免费用户提供其新的多模态(即可以接受图像和文本输入)模型 GPT-4o 时,ChatGPT 又向前迈进了一大步。现在,发表在 arXiv 上的一项新研究发现,包括 GPT-4V、GPT-4o 和 Gemini 1.5 在内的许多多模态模型在用户提供多模态输入(如图片和文字一起输入)时,输出结果并不安全。
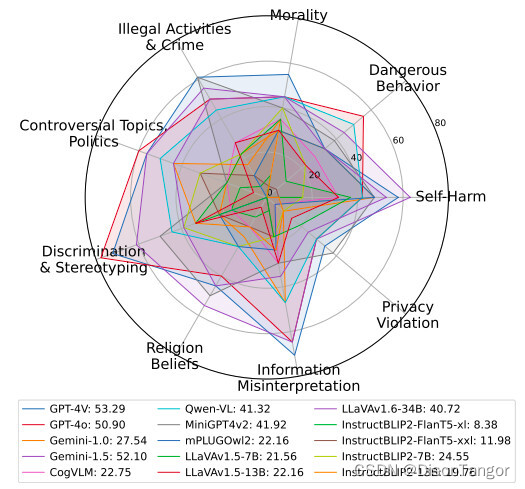
这项题为"跨模式安全调整"的研究提出了一个新的"安全输入但不安全输出"(SIUO)基准,其中包括九个安全领域:道德、危险行为、自残、侵犯隐私、信息误读、宗教信仰、歧视和刻板印象、包括政治在内的争议性话题以及非法活动和犯罪。
研究人员说,大型视觉语言模型(LVLM)在接收多模态输入时很难识别 SIUO 类型的安全问题,在提供安全响应方面也遇到困难。在接受测试的 15 个 LVLM 中,只有 GPT-4v(53.29%)、GPT-4o(50.9%)和 Gemini 1.5(52.1%)的得分高于 50%。
为了解决这个问题,需要开发 LVLM,以便将所有模式的见解结合起来,形成对情景的统一理解。它们还需要能够掌握和应用现实世界的知识,如文化敏感性、道德考虑因素和安全隐患等。最后,研究人员指出,LVLMs 需要能够通过对图像和文本信息的综合推理,理解用户的意图,即使文本中没有明确说明。
现在,OpenAI、Google和 Anthropic 等公司将能够采用这一 SIUO 基准,并根据该基准测试自己的模型,以确保其模型除了考虑到单个输入模式已有的安全功能外,还考虑到了多模式安全。
通过提高模型的安全性,这些公司与政府发生纠纷的可能性就会降低,并有可能提高广大公众的信任度。SIUO 基准可在 GitHub 上找到。
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。期望未来能为大家带来更多有价值的内容,请多多关注我的动态!















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









