







Molmo 是最先进的开放式多模态人工智能模型系列。在广泛的学术基准和人类评估中,我们最强大的模型缩小了开放系统与专利系统之间的差距。我们较小的模型性能优于其 10 倍大小的模型。
虽然目前的多模态模型可以解释多模态数据并用自然语言进行表达,但其全部潜力仍有待开发。Molmo 则更进一步。通过学习指向它所感知到的东西,Molmo 能够与物理和虚拟世界进行丰富的交互,为下一代能够与环境进行互动的应用程序提供支持。
开放、前沿、可操作
当今最先进的多模态模型仍然是专有的。利用开放数据建立视觉语言模型(VLM)的研究工作明显落后于最先进的水平。最近比较强大的开放权重模型在很大程度上依赖于来自专有 VLM 的合成数据来实现良好的性能,从而有效地将这些封闭模型提炼为开放模型。因此,对于如何从零开始建立性能良好的 VLM,社区仍然缺乏基础知识。
我们推出的 Molmo 是最先进的 VLM 新系列。从预先训练好的视觉编码器(CLIP)和纯语言 LLM 开始,我们的 VLM 管道的全部剩余部分–权重、代码、数据和评估–都是开放的,无需经过 VLM 提炼。我们的关键创新是一个新颖、高度详细的图像标题数据集,该数据集完全由使用语音描述的人类注释者收集。为了实现广泛的功能,我们还引入了多样化的数据集混合物进行微调。其中包括创新的二维指向数据,使 Molmo 不仅能使用自然语言,还能使用非语言线索回答问题。我们相信,这为虚拟语言识别(VLM)开辟了重要的未来发展方向,使代理能够在虚拟和物理世界中进行交互。我们的方法能否取得成功,取决于对模型架构细节的精心选择、经过良好调整的训练管道,最关键的是我们新收集的数据集的质量,所有这些数据集都将发布。
Molmo 系列中的同类最佳模型不仅在开放权重和数据模型方面优于其他同类产品,而且与 GPT-4o、Claude 3.5 和 Gemini 1.5 等专有系统相比也毫不逊色。我们将在不久的将来公布我们所有的模型权重、字幕和微调数据以及源代码。部分模型权重、推理代码和公开演示(使用 Molmo-7B-D 模型)从即日起开始提供。

VLM 开放性比较。我们根据三个模型组件(VLM 及其两个预训练组件、LLM 骨干和视觉编码器)的两个属性(开放权重、开放数据和代码)来描述 VLM 的开放性。除了开放与封闭之外,我们还使用 "蒸馏 "标签来表示用于训练 VLM 的数据包括由不同的专有 VLM 生成的图像和文本,这意味着如果不依赖于专有 VLM,则无法复制该模型。
PixMo: 数据质量优于数量
大型 VLM 通常是在来自网络的数十亿图像文本对上进行训练的。这种海量文本往往噪音极大,需要模型在训练过程中将信号与噪音分离开来。噪声文本还会导致模型输出出现幻觉。我们采用了一种截然不同的方法来获取数据,并对数据质量给予了高度关注,我们能够使用不到 100 万对图像文本来训练功能强大的模型,这比许多竞争方法少了 3 个数量级的数据。
Molmo 系列模型成功的最关键因素是 Molmo 的训练数据 PixMo。Pixmo 包括两大类数据:(1)用于多模态预训练的密集字幕数据;(2)用于实现各种用户交互的监督微调数据,包括问题解答、文档阅读和指向等行为。在收集这些数据时,我们的主要限制条件是避免使用现有的 VLM,因为我们希望从头开始建立一个性能良好的 VLM,而不是通过对现有系统的提炼(请注意,我们确实使用了纯语言 LLM,但我们从未将图像传递给这些模型)。
在实践中,从人类注释者那里收集密集的标题数据集是一项挑战。如果要求撰写图片说明,结果往往只能提及几个突出的视觉元素,缺乏细节。如果强制要求最低字数,注释者要么会花很长时间打字,导致收集不经济,要么会复制粘贴专有 VLM 的回复,从而规避了我们避免提炼的目标。因此,开放研究社区一直在努力创建此类数据集,而不依赖于专有 VLM 的合成数据。我们的关键创新在于一种简单而有效的数据收集方法,它可以避免这些问题:我们要求注释者用 60 到 90 秒的语音描述图像,而不是要求他们写出描述。我们要求注释者详细描述他们所看到的一切,包括空间定位和关系的描述。根据经验,我们发现使用这种模式切换 “技巧”,注释者可以在更短的时间内提供更详细的描述,而且我们会为每段描述收集音频收据(即注释者的录音),证明没有使用 VLM。我们总共为 712k 幅图像收集了详细的音频描述,这些图像是从 50 个高级主题中抽取的。
我们的微调数据混合物包括标准学术数据集和几个新收集的数据集,我们也将发布这些数据集。学术数据集主要让模型在基准数据集上运行良好,而我们新收集的数据集则实现了广泛的重要功能,包括在与用户聊天时回答有关图像的一般问题,超出了学术基准数据集的范围;改进了以 OCR 为中心的任务(如阅读文档和图表);实现了对模拟时钟的准确读取;以及让模型指向图像中的一个或多个视觉元素。指向功能提供了以图像像素为基础的自然解释,从而为 Molmo 带来了新的改进功能。我们相信,未来指向功能将成为 VLM 与代理之间的重要沟通渠道。例如,机器人可以向支持指向功能的 VLM 询问航点或要拾取的物体的位置,网络代理也可以向 VLM 询问要点击的用户界面元素的位置。
新收集的数据集说明如下。
PixMo-Cap
PixMo-Cap 是一个用于预训练 VLM 以了解图像细节的数据集。该数据集包含 712,000 张不同的图像和大约 130 万个密集的图像标题。这些标题是由人类注释者生成的,他们对不同的网络图像提供了 60-90 秒的详细口语描述,然后使用语言模型对其进行转录和完善。该数据集涵盖了广泛的主题,包括对图像内容、对象、文本、位置、微妙细节、背景、风格和颜色的详细描述。
PixMo-AskModelAnything
PixMo-AskModelAnything 是一个数据集,旨在帮助人工智能模型回答有关图像的各种问题。该数据集包含 73,000 张图片的 162,000 个问题-答案对,创建过程中,人类注释者选择图片、编写问题,并根据图片说明和 OCR 输出迭代改进语言模型生成的答案。该数据集还纳入了不寻常的要求,例如将答案倒过来写,以增加多样性。
PixMo-Points
PixMo-Points 是一个包含图像标题数据的数据集,在这个数据集中,人类注释者被要求指向图像中的物体并写出对它们的描述。该数据集包含来自 42.8 万张图片的 230 万个问题点对,其中包括注释者指向描述对象的每个出现点的情况,以及图片中没有出现对象的情况。该数据集旨在使模型能够指向文本描述的任何内容,通过指向来计算对象,并将指向作为一种视觉解释形式。
PixMo-CapQA
该数据集包含 214,000 对问题和答案,这些问题和答案是使用语言模型从 165,000 个图片标题中生成的。问题涵盖不同的主题和风格,以增加多样性。
PixMo-Docs
该数据集包括 255,000 张文本和图文并茂的图片(图表、文档、表格、示意图),以及由语言模型生成的相应代码。它还包含基于生成代码的 230 万个问答对。
PixMo-Clocks
这是一个合成数据集,包含 826,000 张模拟时钟图像以及相应的时间问答。该数据集包含约 50 种不同的手表类型和 160,000 种逼真的手表表面样式,以及随机选择的时间。
基准评估和大规模人类偏好排名
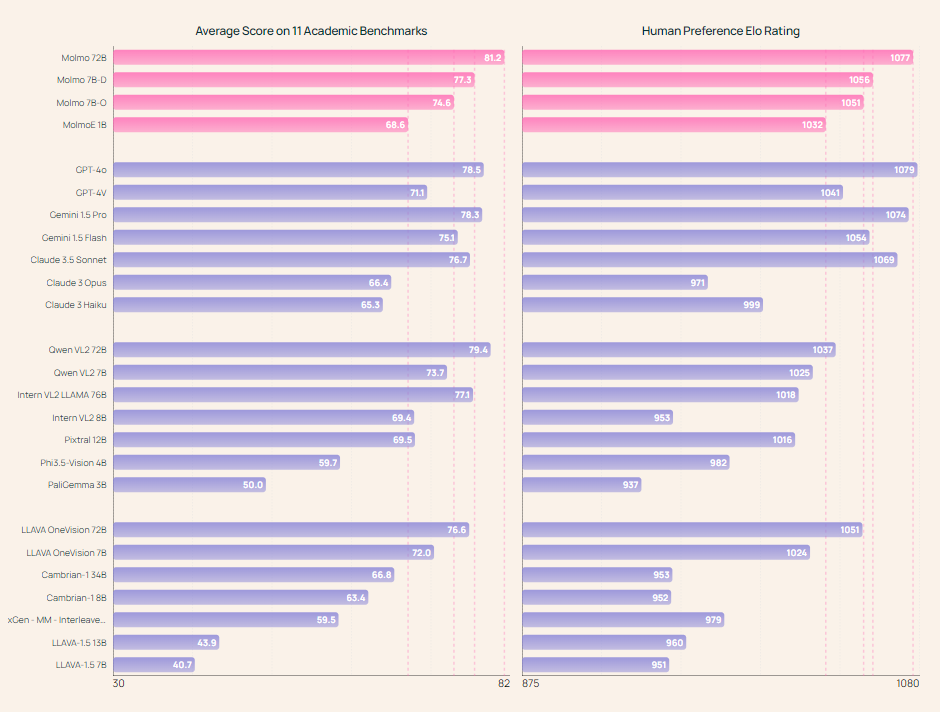
随着新的学术基准不断出现,视觉语言模型评估也在迅速发展。这些基准可以很好地评估特定技能,但要在这些基准上取得好成绩,往往需要以特定基准的风格回答问题。这些答案往往很简短,在其他环境下效果不佳。因此,学术基准只能部分反映模型的性能。作为对这些基准的补充,我们还进行了人工评估,以便根据用户偏好对模型进行排序。
在学术基准测试方面,我们试图收集所有模型在一组 11 个常用学术基准测试中的结果[1]。如果没有结果,我们会尝试从其他技术报告或公开排行榜(如 OpenVLM 排行榜)中找到之前报告的最佳值。最后,如果某个值仍然缺失,我们就自行计算。我们注意到,计算结果在实践中是很困难的,对于一个固定的模型,特定基准的结果可能相差很大(例如 10 个百分点),这取决于评估的细节。使问题更加复杂的是,在许多情况下,可能无法获得关键的评估细节,如使用了哪些提示或如何处理数据,从而难以复制已公布的结果。这些问题凸显了公开评估的重要性。
我们也避免将声称的 "零点 "性能(通常是针对封闭数据模型的报告)与明确在基准训练集上训练的模型的监督性能强加区分。有监督训练和 "零次 "传输之间的区别并不明确,因为我们可以策划新的数据源,作为任何给定基准的字面训练数据的有效替代。当训练数据未公开时,社区就没有办法评估 "零转移 "的说法。
在我们的人工评估中,我们收集了一系列不同的图像和文本提示对,并询问了一组 VLM 以获得响应。然后,我们将所有 VLM 配对的图像-文本-回复三元组提交给一组约 870 名人类注释者,由他们给出配对偏好排名。根据这些偏好排名,我们按照 LMSYS Org’s Chatbot Arena 的方法,使用 Bradley-Terry 模型计算了 ELO 排名。我们在 27 个模型中收集了超过 325,231 次成对比较,这是迄今为止对多模态模型进行的最大规模的人类偏好评估。作为参考,我们的 ELO 排名是基于比 Chatbot Arena (LMSYS) 多 3 倍的视觉模型投票。
总体而言,学术基准结果和人工评估结果基本一致,但 Qwen VL2 除外,它在学术基准上表现优异,而在人工评估中表现相对较差。
AI2D test, ChartQA test, VQA v2.0 test, DocQA test, InfographicVQA test, TextVQA val, RealWorldQA, MMMU val, MathVista testmini, CountBenchQA, Flickr Count (we collected this new dataset that is significantly harder than CountBenchQA).

人类偏好评估。我们的 Elo 人类偏好评估使用了 15k 对图像和文本提示。我们询问了每个 VLM 的回复,并将所有 VLM 配对的图像-文本-回复三元组提交给一组 870 位人类注释者,由他们给出成对偏好排名,27 个模型共进行了 325,231 次成对比较,这是迄今为止针对多模态模型进行的最大规模人类偏好评估。作为参考,我们的 ELO 排名是基于比 Chatbot Arena (LMSYS) 多 3 倍的视觉模型投票。
参考
https://molmo.allenai.org/blog


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









