








百川-Omni-1.5 代表了百川-omni 系列中最新、最先进的模型,通过端到端方法进行训练和推理。与开源模型相比,Baichuan-Omni-1.5 在理解文本、图像、音频和视频输入方面都有显著改进。值得注意的是,该模型在可控实时语音交互和跨各种模式的协作实时理解方面展示了令人印象深刻的能力。除了一般能力之外,百川-Omni-1.5 还是医疗领域最杰出的 MLLM。这为 AGI 为人类社会的福祉做出贡献开辟了令人兴奋的新可能性。
使用案例
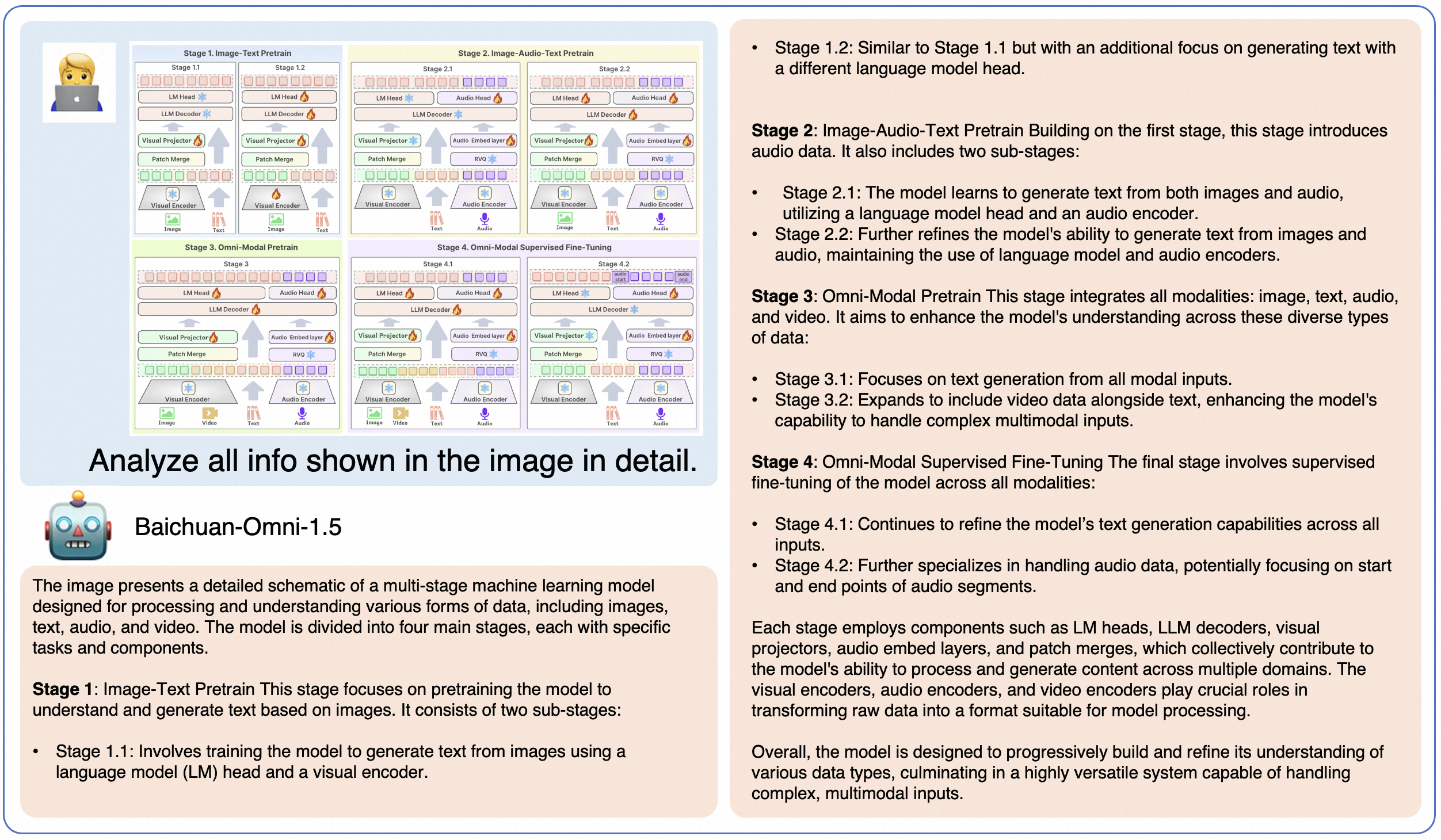

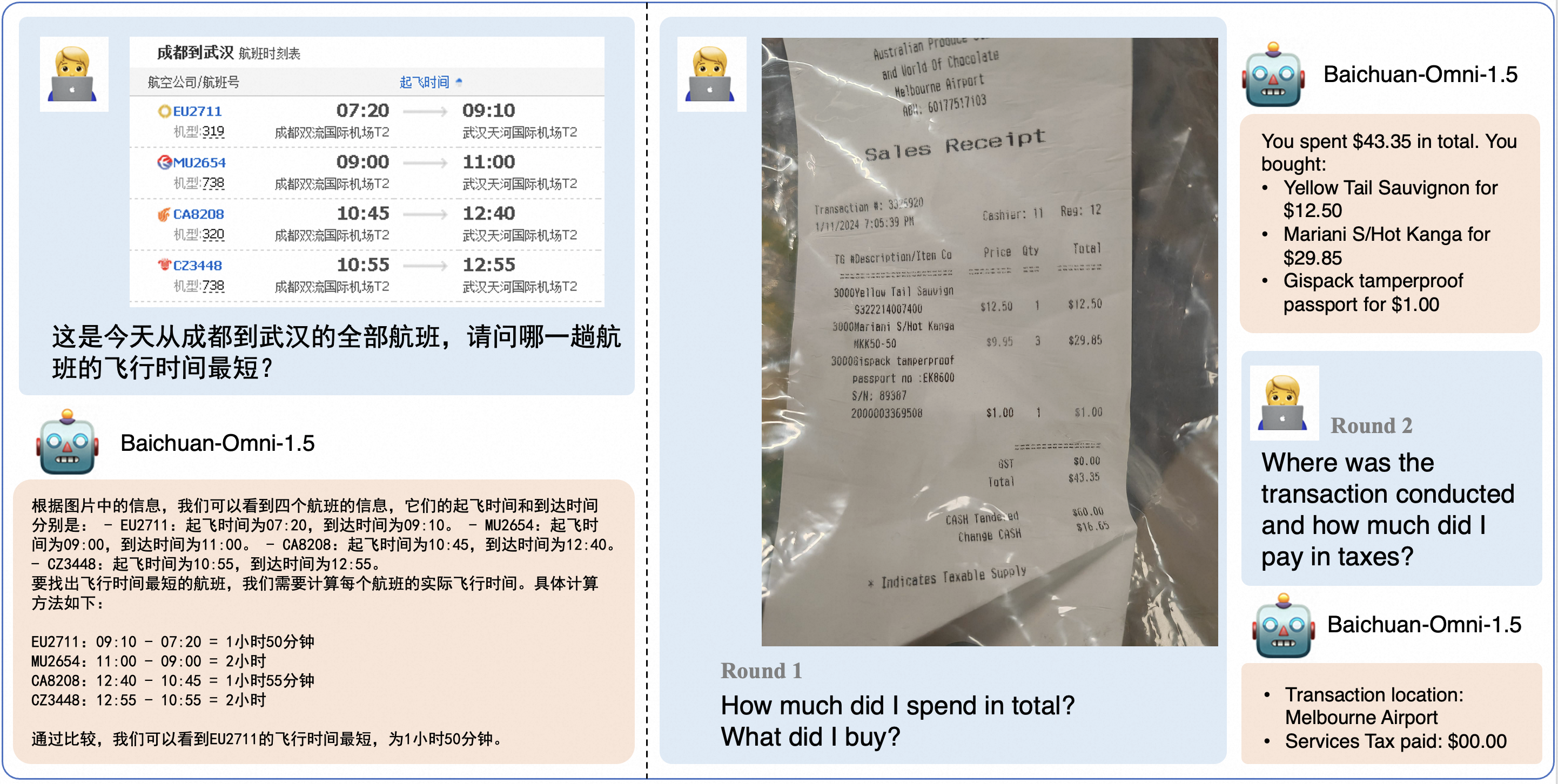
本地 WebUI Demo
准备工作
创建虚拟环境
conda create -n baichuan_omni python==3.12
conda activate baichuan_omni
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
pip install -r baichuan_omni_requirements.txt
pip install accelerate flash_attn==2.6.3 speechbrain==1.0.0 deepspeed==0.14.4
apt install llvm ffmpeg
下载模型并修改模型路径
修改 web_demo/constants.py 中的 MODEL_PATH 为本地模型路径
图像Demo
cd web_demo
python vision_s2s_gradio_demo_cosy_multiturn.py
音频Demo
cd web_demo
python s2s_gradio_demo_cosy_multiturn.py
视频Demo
cd web_demo
python video_s2s_gradio_demo_cosy_singleturn.py
开源评测集
OpenMM-Medical
为了更全面的评估模型医疗多模态能力,我们从公开医学图像数据集中收集了 OpenMM-Medical 评测集,包含 ACRIMA(眼底图像)、BioMediTech(显微镜图像)和 CoronaHack(X 射线)等,总共包含 88,996 张图像。
OpenAudioBench
为了更高效的评估模型的“智商”问题,我们构建了 OpenAudioBench,共包含5个音频端到端理解子评测集,分别是4个公开评测集(llama question、WEB QA、TriviaQA、AlpacaEval),以及百川团队自建的语音逻辑推理评测集,共2701条数据,能够综合反映模型“智商”水平。
致谢
- 视觉编码器架构:NaVit
- 自动语音识别(ASR, Automatic Speech Recognition)模型:Whisper
- 大语言模型(LLM):Qwen2.5 7B
- 视觉编码器的权重初始化于Qwen2-VL-7B:(https://arxiv.org/abs/2409.12191)
- 部分代码来自:CosyVoice和Matcha-TTS:(https://github.com/FunAudioLLM/CosyVoice, https://github.com/shivammehta25/Matcha-TTS/)
- 使用CosyVoice 2.0中的HiFi-GAN vocoder:(https://funaudiollm.github.io/cosyvoice2/)
Github:https://github.com/baichuan-inc/Baichuan-Omni-1.5/

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









