








Baichuan-Omni-1.5是最新的端到端训练有素的全模态大型模型,支持综合输入模式(文本、图像、视频、音频)和双输出模式(文本和音频)。它以 Qwen2.5-7B 语言模型为基础,可以处理来自各种模式的输入,并以可控的方式生成高质量的文本和语音输出。
-
Baichuan-Omni-1.5-Base:为了促进全模态模型的发展,我们开源了一个在高质量、广泛的数据集上训练的基础模型。该模型没有经过指令监督微调(SFT),具有极大的灵活性,是目前可用的性能最佳的基础全模式模型 。
-
Baichuan-Omni-1.5:利用强大的百川-Omni-1.5-Base,该模型使用高质量的全模态对齐数据进行端到端训练。百川-Omni-1.5实现了与GPT-4o-mini. 相媲美的文本、图像、视频和音频理解能力。
Baichuan-Omni-1.5
Baichuan-Omni-1.5 代表了百川-omni 系列中最新、最先进的模型,通过端到端方法进行训练和推理。与开源模型相比,Baichuan-Omni-1.5 在理解文本、图像、音频和视频输入方面都有显著改进。值得注意的是,该模型在可控实时语音交互和跨各种模式的协作实时理解方面展示了令人印象深刻的能力。除了一般能力之外,Baichuan-Omni-1.5 还是医疗领域最杰出的 MLLM。这为 AGI 为人类社会的福祉做出贡献提供了令人兴奋的新可能性。根据评估结果,我们总结了Baichuan-Omni-1.5 的主要优势和贡献:
-
全模式交互:baichuan-Omni-1.5 设计用于处理文本、图像、音频和视频输入,提供高质量的文本和语音输出。它能够实现无缝、高质量的跨模态交互,而不会影响任何模态的功能。
-
卓越的视觉语言能力:baichuan-Omni-1.5 在十项图像理解基准测试中平均得分 73.3 分,超过GPT-4o-mini平均 6 分。
-
统一而出色的语音功能:我们设计了一种 8 层 RVQ 音频标记器(Baichuan-Audio-Tokenizer),在捕获语义信息和声学信息之间实现了最佳平衡,帧频为 12.5 Hz 的帧速率,支持 高质量的可控双语(中文和英文)实时对话。与此同时,我们还开源了音频理解和生成基准(OpenAudio-Bench),以评估音频的端到端功能。
-
领先的医学影像理解:我们收集了一个全面的医学理解基准:OpenMM-Medical 是对现有数据集的整合。我们的模型在 GMAI-MMBench 和 OpenMM-Medical上实现了最先进的性能。具体而言,在 OpenMM-Medical 上,Baichuan-Omni-1.5 使用 7B LLM 得到 83.8% 的分数,超过 Qwen2-VL-72B 的 80.7% 分数。
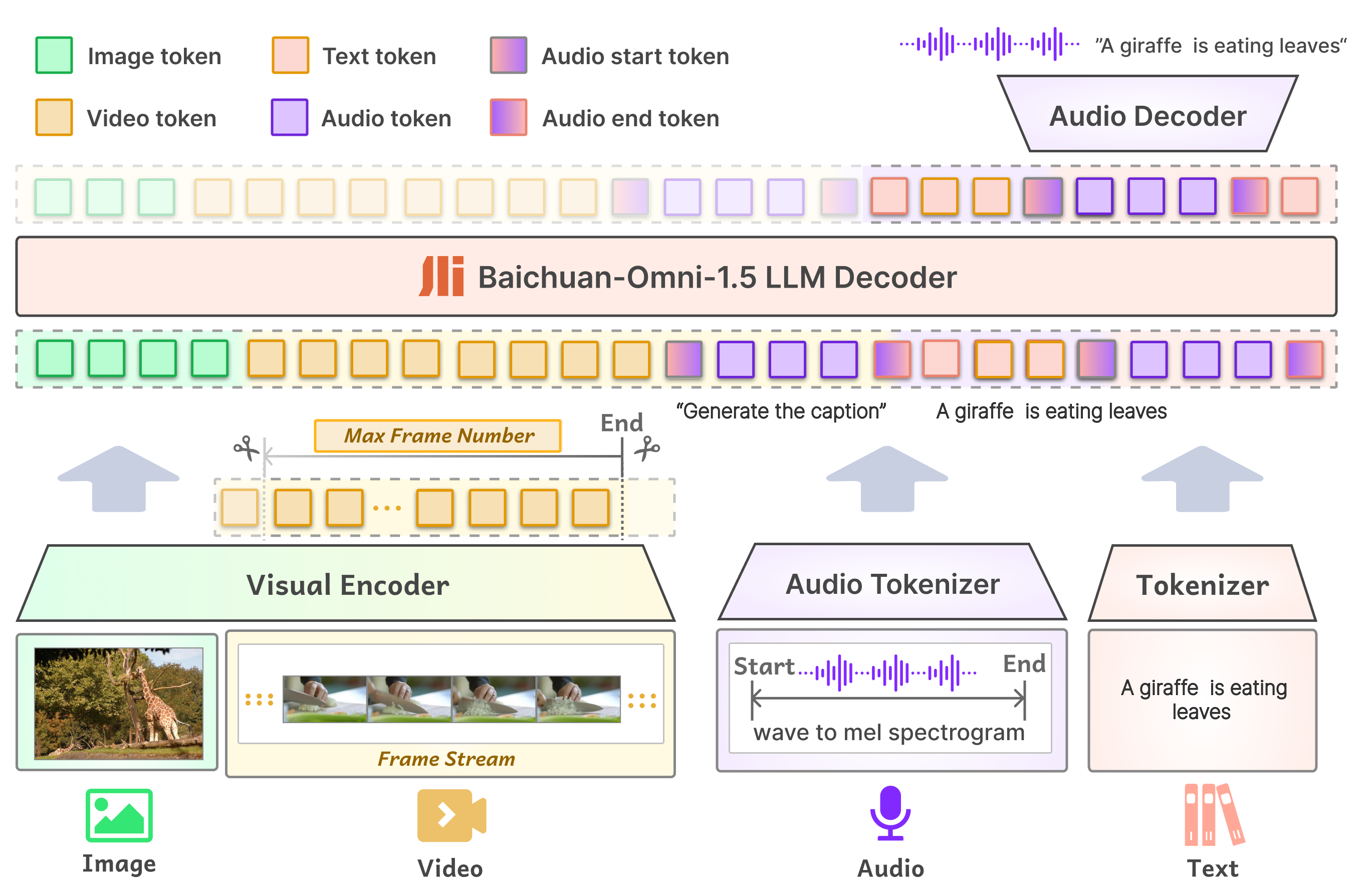
模型架构
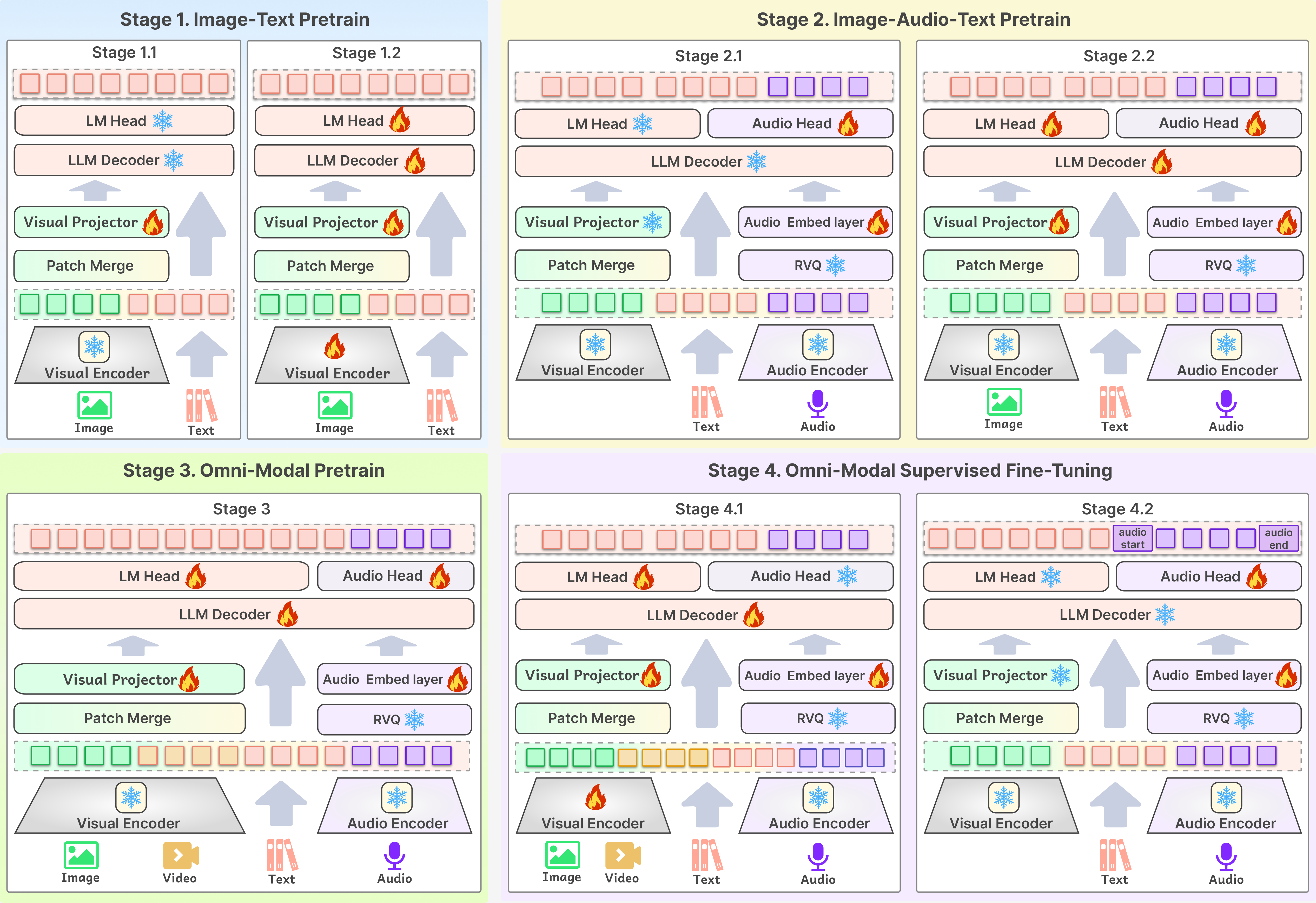
多阶段全方位训练框架
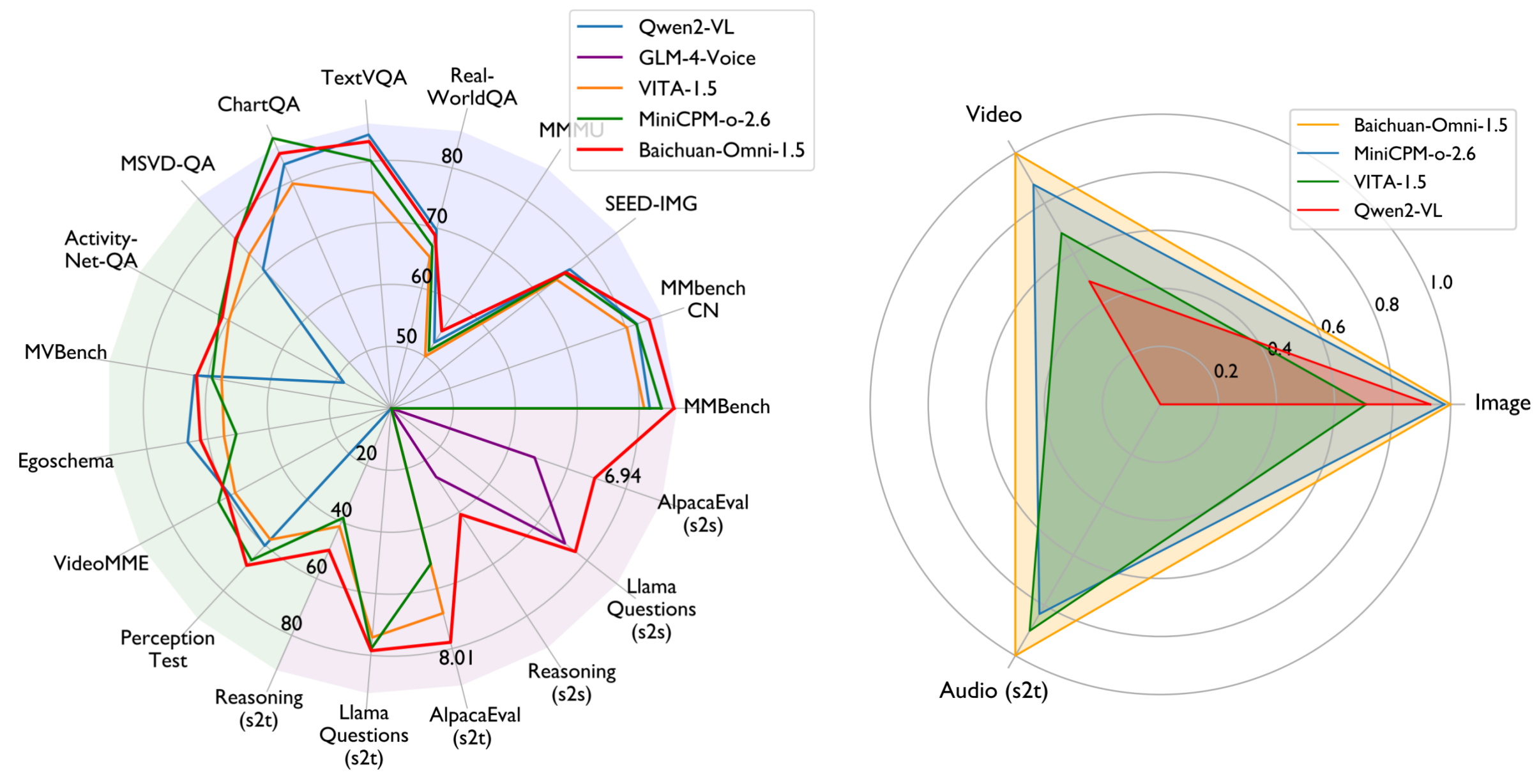
绩效评估
纯文本理解能力
| Comprehensive Tasks | ||||||
|---|---|---|---|---|---|---|
| Model | Size | MMLU (Acc.) | CMMLU (Acc.) | AGIEval (Acc.) | C-Eval (Acc.) | GAOKAO (Acc.) |
| Proprietary Models | ||||||
| GPT 4o | - | 88.0♢ | 78.3♢ | 62.3♢ | 86.0♢ | - |
| GPT 4o mini | - | 82.0 | 67.6 | 52.2 | 63.6 | 70.8 |
| Open-source Models (Pure text) | ||||||
| MAP-Neo | 7B | 58.2 | 55.1 | 33.9 | 57.5 | - |
| Qwen1.5-Chat | 7B | 61.5 | 68.0 | 39.3 | 68.8 | - |
| Llama3-Instruct | 8B | 67.1 | 51.7 | 38.4 | 50.7 | - |
| OLMo | 7B | 28.4 | 25.6 | 19.9 | 27.3 | - |
| Open-source Models (Omni-modal) | ||||||
| VITA | 8x7B | 71.0* | 46.6 | 46.2* | 56.7* | - |
| VITA-1.5 | 7B | 71.0 | 75.1 | 47.9 | 65.6 | 57.4 |
| Baichuan-Omni | 7B | 65.3 | 72.2 | 47.7 | 68.9 | - |
| MiniCPM-o 2.6 | 7B | 65.3 | 63.3 | 50.9 | 61.5 | 56.3 |
| Baichuan-Omni-1.5 | 7B | 72.2 | 75.5 | 54.4 | 73.1 | 73.5 |
图像理解能力
| Multi-choice & Yes-or-No Question | ||||||||
|---|---|---|---|---|---|---|---|---|
| Model | Size | MMBench-EN (Acc.) | MMbench-CN (Acc.) | SEED-IMG (Acc.) | MMMU-val (Acc.) | HallusionBench (Acc.) | ||
| Proprietary Models | ||||||||
| GPT-4o | - | 83.4♢ | 82.1♢ | - | 69.1♢ | 55.0♢ | ||
| GPT-4o-mini | - | 77.7 | 76.9 | 72.3 | 60.0♢ | 46.1♢ | ||
| Open Source Models (Vision-Language) | ||||||||
| Qwen2-VL-7B | 7B | 81.7 | 81.9 | 76.5 | 52.7 | 50.6∗ | ||
| MiniCPM-Llama3-V 2.5 | 8B | 76.7 | 73.3 | 72.4 | 45.8∗ | 42.5 | ||
| Open Source Models (Omni-modal) | ||||||||
| VITA | 8x7B | 74.7 | 71.4 | 72.6 | 45.3 | 39.7∗ | ||
| VITA-1.5 | 7B | 80.8 | 80.2 | 74.2 | 53.1 | 44.1 | ||
| Baichuan-Omni | 7B | 76.2 | 74.9 | 74.1 | 47.3 | 47.8 | ||
| MiniCPM-o 2.6 | 7B | 83.6 | 81.8 | 75.4 | 51.1 | 50.1 | ||
| Baichuan-Omni-1.5 | 7B | 85.6 | 83.6 | 75.7 | 53.9 | 49.7 | ||
| Visual Question Answering | ||||||||
|---|---|---|---|---|---|---|---|---|
| Model | Size | RealWorldQA (Acc.) | MathVista-mini (Acc.) | TextVQA-val (Acc.) | ChartQA (Acc.) | OCRBench (Acc.) | ||
| Proprietary Models | ||||||||
| GPT-4o | - | 75.4♢ | 63.8♢ | - | 85.7♢ | 73.6♢ | ||
| GPT-4o-mini | - | 66.3 | 53.4 | 66.8 | - | 77.4 | ||
| Open Source Models (Vision-Language) | ||||||||
| Qwen2-VL-7B | 7B | 69.7 | 58.2∗ | 84.3∗ | 83.0∗ | 84.5∗ | ||
| MiniCPM-Llama3-V 2.5 | 8B | 63.5 | 54.3∗ | 76.6 | 72.0 | 72.5 | ||
| Open Source Models (Omni-modal) | ||||||||
| VITA | 8x7B | 59.0 | 44.9∗ | 71.8 | 76.6 | 68.5∗ | ||
| VITA-1.5 | 7B | 66.8 | 66.5 | 74.9 | 79.6 | 73.3 | ||
| Baichuan-Omni | 7B | 62.6 | 51.9 | 74.3 | 79.6 | 70.0 | ||
| MiniCPM-o 2.6 | 7B | 67.7 | 64.6 | 80.1 | 87.6 | 89.7∗ | ||
| Baichuan-Omni-1.5 | 7B | 68.8 | 63.6 | 83.2 | 84.9 | 84.0 | ||
视频理解能力
| General VQA | ||||||
|---|---|---|---|---|---|---|
| Model | Size | # Frames | MVBench (Acc.) | Egoschema (Acc.) | VideoMME (Acc.) | Perception-Test (Acc.) |
| Proprietary Models | ||||||
| Gemini 1.5 Pro | - | - | 81.3♢ | 63.2* | 75.0♢ | - |
| GPT 4o mini | - | - | 55.2 | 58.5 | 63.6 | 48.2 |
| GPT 4o | - | - | - | 77.2* | 71.9♢ | - |
| GPT 4V | - | - | 43.7♢ | 55.6* | 59.9♢ | - |
| Open-source Models (Vision-language) | ||||||
| Qwen2-VL-7B | 7B | 2 fps (max 768) | 67.0* | 64.4 | 66.7* | 66.6 | 63.3* | 59.0 | 62.3* | 60.3 |
| AnyGPT | 8B | 48 | 33.2 | 32.1 | 29.8 | 29.1 |
| VideoLLaMA 2 | 7B | 16 | 54.6* | 51.7* | 46.6* | 51.4* |
| VideoChat2 | 7B | 16 | 51.1* | 42.1♢ | 33.7♢ | 47.3♢ |
| LLaVA-NeXT-Video | 7B | 32 | 46.5♢ | 43.9♢ | 33.7♢ | 48.8♢ |
| Video-LLaVA | 7B | 8 | 41.0♢ | 38.4♢ | 39.9♢ | 44.3♢ |
| Open-source Models (Omni-modal) | ||||||
| VITA | 8x7B | 1 fps (max 32) | 53.4 | 53.9 | 56.1 | 56.2 |
| VITA-1.5 | 7B | 1 fps (max 32) | 55.5 | 54.7 | 57.3 | 57.6 |
| Baichuan-Omni | 7B | 1 fps (max 32) | 60.9 | 58.8 | 58.2 | 56.8 |
| MiniCPM-o 2.6 | 7B | 1 fps (max 64) | 58.6 | 50.7 | 63.4 | 66.6 |
| Baichuan-Omini-1.5 | 7B | 1 fps (max 32) | 63.7 | 62.4 | 60.1 | 68.9 |
| Open-ended VQA | ||||||
|---|---|---|---|---|---|---|
| Model | Size | # Frames | ActivityNet-QA | MSVD-QA | ||
| (Acc.) | (Score) | (Acc.) | (Score) | |||
| Proprietary Models | ||||||
| Gemini 1.5 Pro | - | - | 56.7* | - | - | - |
| GPT 4o mini | - | 1 fps (max 32) | 62.1 | 3.1 | 67.5 | 3.3 |
| GPT 4o | - | - | 61.9* | - | - | - |
| GPT 4V | - | - | 59.5* | - | - | - |
| Open-source Models (Vision-language) | ||||||
| Qwen2 VL | 7B | 2 fps (max 768) | 17.4 | 1.9 | 61.1 | 3.5 |
| VideoLLaMA 2 | 7B | 16 | 50.2* | 3.3* | 70.9* | 3.8* |
| VideoChat2 | 7B | 16 | 49.1* | 3.3* | 70.0* | 3.9* |
| LLaVA-NeXT-Video | 7B | 32 | 53.5* | 3.2* | 67.4 | 3.4 |
| Video-LLaVA | 7B | 8 | 45.3* | 3.3* | 70.7* | 3.9* |
| Open-source Models (Omni-modal) | ||||||
| VITA | 8x7B | 1 fps (max 32) | 55.0 | 3.5 | 63.9 | 3.7 |
| VITA-1.5 | 7B | 1 fps (max 32) | 59.6 | 3.0 | 67.6 | 3.3 |
| Baichuan-Omni | 7B | 1 fps (max 48) | 58.6 | 3.7 | 72.2 | 4.0 |
| MiniCPM-o 2.6 | 7B | 1 fps (max 64) | 63.0 | 3.1 | 73.7 | 3.6 |
| Baichuan-Omni-1.5 | 7B | 1 fps (max 48) | 62.0 | 3.1 | 74.2 | 3.6 |
语音理解与生成综合能力
| Audio Comprehensive Capacity | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Size | Reasoning QA | Llama Questions | Web Questions | TriviaQA | AlpacaEval | |||||
| s→t | s→s | s→t | s→s | s→t | s→s | s→t | s→s | s→t | s→s | ||
| Proprietary Models | |||||||||||
| GPT-4o-Audio | - | 55.6 | - | 88.4 | - | 8.10 | - | 9.06 | - | 8.01 | - |
| Open-source Models (Pure Audio) | |||||||||||
| GLM-4-Voice | 9B | - | 26.5 | - | 71.0 | - | 5.15 | - | 4.66 | - | 4.89 |
| Open-source Models (Omni-modal) | |||||||||||
| VITA-1.5 | 7B | 41.0 | - | 74.2 | - | 5.73 | - | 4.68 | - | 6.82 | - |
| MiniCPM-o 2.6 | 7B | 38.6 | - | 77.8 | - | 6.86 | - | 6.19 | - | 5.18 | - |
| Baichuan-Omni-1.5 | 7B | 50.0 | 40.9 | 78.5 | 75.3 | 5.91 | 5.52 | 5.72 | 5.31 | 7.79 | 6.94 |
全模态理解能力
| Omni-Undesratnding | ||||||
|---|---|---|---|---|---|---|
| Model | Size | Image & Audio (Acc.) | Image Caption & Audio (Acc.) | Image & Audio Transcript (Acc.) | Image Caption & Audio Transcript (Acc.) | |
| Proprietary Models | ||||||
| GPT4o-mini | - | - | - | 37.0 | 37.7 | |
| Open-source Models (Omni-modal) | ||||||
| VITA | 8x7B | 33.1 | 31.8 | 42.0 | 44.2 | |
| VITA-1.5 | 7B | 33.4 | 29.6 | 48.5 | 47.2 | |
| Baichuan-Omni | 7B | 32.2 | 26.5 | 42.6 | 44.2 | |
| MiniCPM-o 2.6 | 7B | 40.5 | 30.8 | 53.2 | 46.3 | |
| Baichuan-Omni-1.5 | 7B | 42.9 | 37.7 | 47.9 | 46.9 | |
医疗图像理解能力
| Medical Understanding | ||||||
|---|---|---|---|---|---|---|
| Model | Size | GMAI-MMB-VAL (Acc.) | OpenMM-Medical (Acc.) | |||
| Proprietary Models | ||||||
| GPT4o-mini | - | 46.4 | 74.3 | |||
| Open-source Models (Vision-Language) | ||||||
| Qwen2 VL | 7B | 46.3 | 76.9 | |||
| Qwen2 VL | 72B | 50.7 | 80.7 | |||
| Open-source Models (Omni-modal) | ||||||
| VITA-1.5 | 7B | 36.7 | 67.1 | |||
| MiniCPM-o 2.6 | 7B | 41.5 | 73.6 | |||
| Baichuan-Omni-1.5 | 7B | 49.9 | 83.8 | |||


















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









