







在人工智能领域,视觉语言模型的发展一直是研究的热点。如今,加州大学伯克利分校的研究团队带来了令人振奋的消息,他们发布了全新的TULIP(Towards Unified Language-Image Pretraining)模型,这一模型在视觉语言预训练方面取得了重大突破,尤其在以视觉为中心的任务中表现出色,克服了现有对比学习模型(如CLIP)的诸多局限。
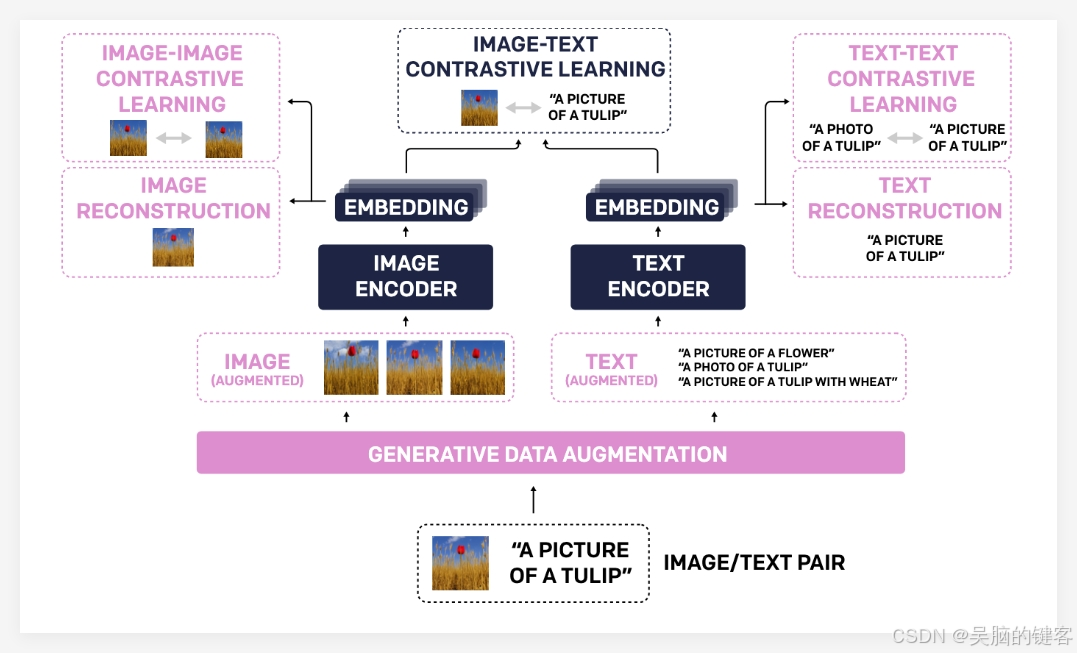
核心技术剖析:三大创新引领性能飞跃
TULIP模型的卓越性能主要归功于其独特的技术组合,这三大创新共同推动了模型性能的飞跃:
-
生成式数据增强:TULIP利用生成模型扩展训练数据,从而提升模型的鲁棒性和泛化能力。通过合成更多样化的图像-文本对,模型能够学习到更全面的视觉和语言知识。
-
增强对比学习:与传统对比学习方法不同,TULIP不仅关注图像-文本匹配,还引入了图像-图像和文本-文本对比学习目标。这种增强方法帮助模型更好地理解不同图像之间的视觉相似性以及不同文本描述之间的语义关系,从而提高对细微信息的理解能力。
-
重建正则化:为了进一步强化视觉和语言特征的对齐,TULIP采用重建正则化策略。这种方法促使模型从图像特征中重建对应的文本描述,或反之,从而迫使模型学习更深层次的跨模态关联。
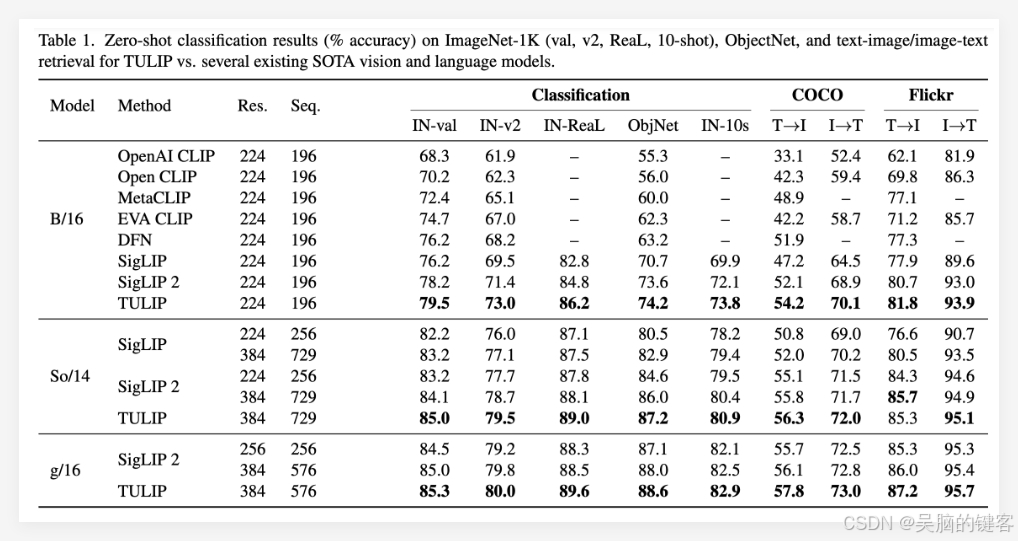
卓越实验成果:多项基准测试中的破纪录表现
实验结果充分证明了TULIP模型的优越性。报告指出,TULIP在多个关键视觉和视觉语言基准测试中取得了最先进的性能。具体成就包括:
-
ImageNet-1K零样本分类显著提升:TULIP能够在未对特定类别进行训练的情况下准确分类图像,展现出强大的零样本学习能力。
-
细粒度物体识别能力增强:TULIP能够更精确地识别图像中具有细微差异的物体,这对于需要精准识别的应用至关重要。
-
多模态推理评分提高:在需要结合图像和文本信息进行推理的任务中,TULIP表现出更高的准确率和更强的理解力。
尤为值得注意的是,TULIP在MMVP基准测试上相较于现有方法实现了3倍性能提升,在微调视觉任务上实现了2倍性能提升。
未来展望:TULIP模型的广泛应用与深远影响
TULIP模型的发布不仅为学术研究提供了新的方向,也为实际应用带来了巨大的潜力。其在零样本和少样本分类任务中的出色表现,使其成为动态环境中处理新类别问题的宝贵工具。此外,TULIP在复杂视觉语言任务中的卓越能力,如多视图推理、实例分割、计数、深度估计和物体定位等,预示着其在自动驾驶、医疗影像分析、增强现实等多个领域的广泛应用前景。
随着TULIP模型的不断优化和应用拓展,我们有理由相信,它将在未来的人工智能技术发展中扮演重要角色,为构建更加智能、高效的AI系统奠定坚实基础。
Project:https://tulip-berkeley.github.io/
Code:https://github.com/tulip-berkeley/open_clip


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









