







我们介绍的 Kimi-VL,是一种高效的开源专家混合物(MoE)视觉语言模型(VLM),它具有先进的多模态推理能力、长语境理解能力和强大的代理能力,而在其语言解码器(Kimi-VL-A3B)中只需激活 2.8B 个参数。
Kimi-VL 在各个具有挑战性的领域都表现出了强劲的性能:作为一种通用的视觉语言模型,Kimi-VL 在多轮代理交互任务(例如 OSWorld)中表现出色,取得了与旗舰模型相当的先进成果。此外,它还在各种具有挑战性的视觉语言任务中表现出卓越的能力,包括大学水平的图像和视频理解、光学字符识别(OCR)、数学推理、多图像理解等。
在比较评估中,它能有效地与 GPT-4o-mini、Qwen2.5-VL-7B 和 Gemma-3-12B-IT 等尖端高效 VLM 竞争,同时在多个专业领域超越 GPT-4o。
Kimi-VL 还在处理长语境和清晰感知方面推进了多模态模型的帕累托前沿:由于配备了 128K 扩展上下文窗口,Kimi-VL 可以处理各种长输入内容,在 LongVideoBench 和 MMLongBench-Doc 上分别取得了 64.5 和 35.1 的优异成绩;其原生分辨率视觉编码器 MoonViT 进一步使其能够看到并理解超高分辨率的视觉输入内容,在 InfoVQA 和 ScreenSpot-Pro 上分别取得了 83.2 和 34.5 的优异成绩,同时在处理普通视觉输入内容和一般任务时保持了较低的计算成本。
在此基础上,我们推出了一种先进的长期思维变体:Kimi-VL-Thinking。该模型通过长思维链(CoT)监督微调(SFT)和强化学习(RL)开发而成,具有强大的长视距推理能力。它在 MMMU、MathVision 和 MathVista 上的得分分别为 61.7、36.8 和 71.3,同时保持了 2.8B 的紧凑型激活 LLM 参数占用空间,为高效且功能强大的多模态思维模型设定了新标准。
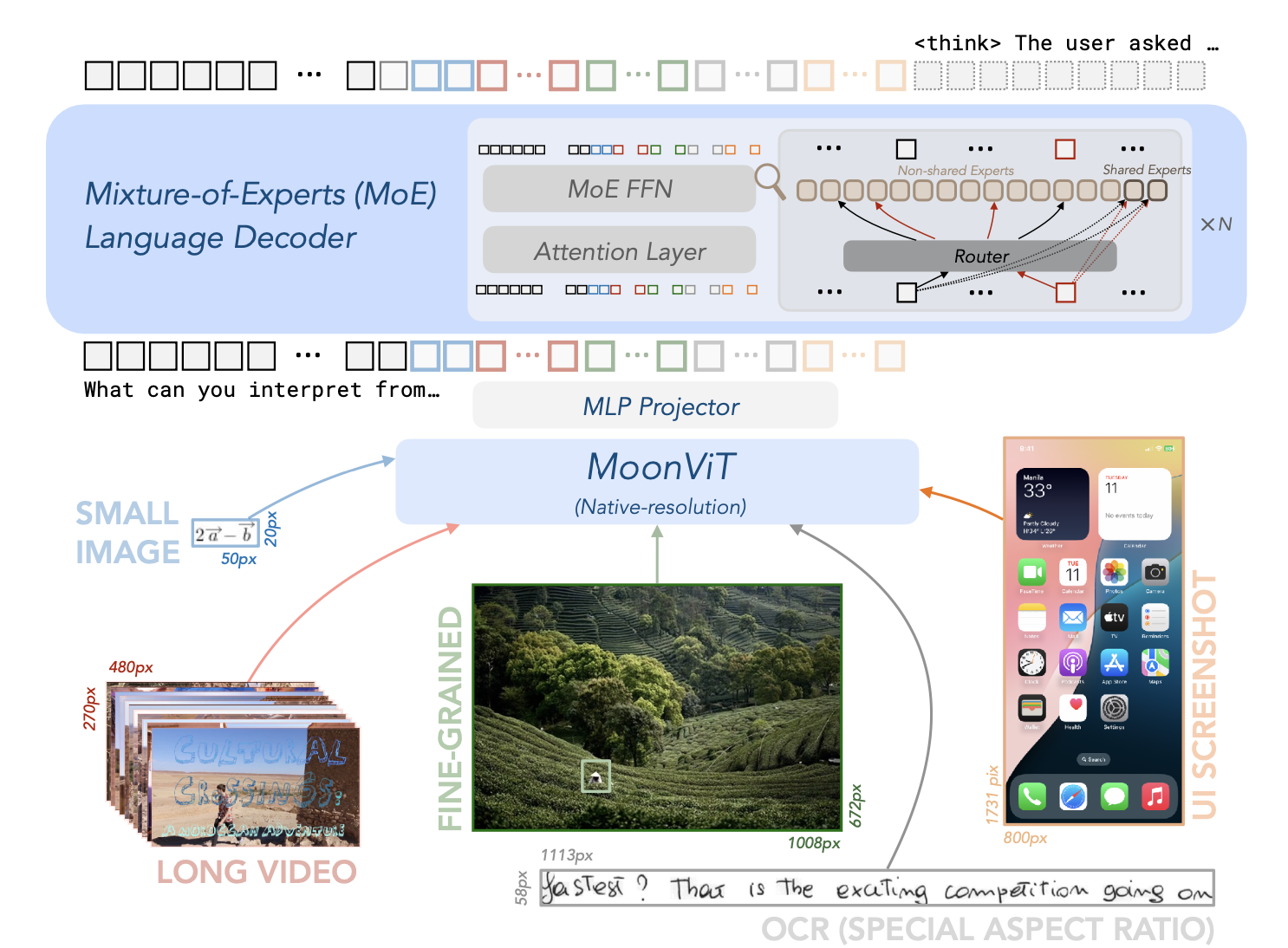
架构
如下图所示,该模型采用了 MoE 语言模型、原生分辨率视觉编码器(MoonViT)和 MLP 投影仪。
性能
Kimi-VL-A3B-Instruct
作为一种高效的模型,Kimi-VL 可以在广泛的输入形式(单图像、多图像、视频、长文档等)中稳健地处理各种任务(细粒度感知、数学、大学问题、OCR、代理等)。
与现有的 10B 级密集 VLM 和 DeepSeek-VL2 (A4.5B) 进行简要比较:
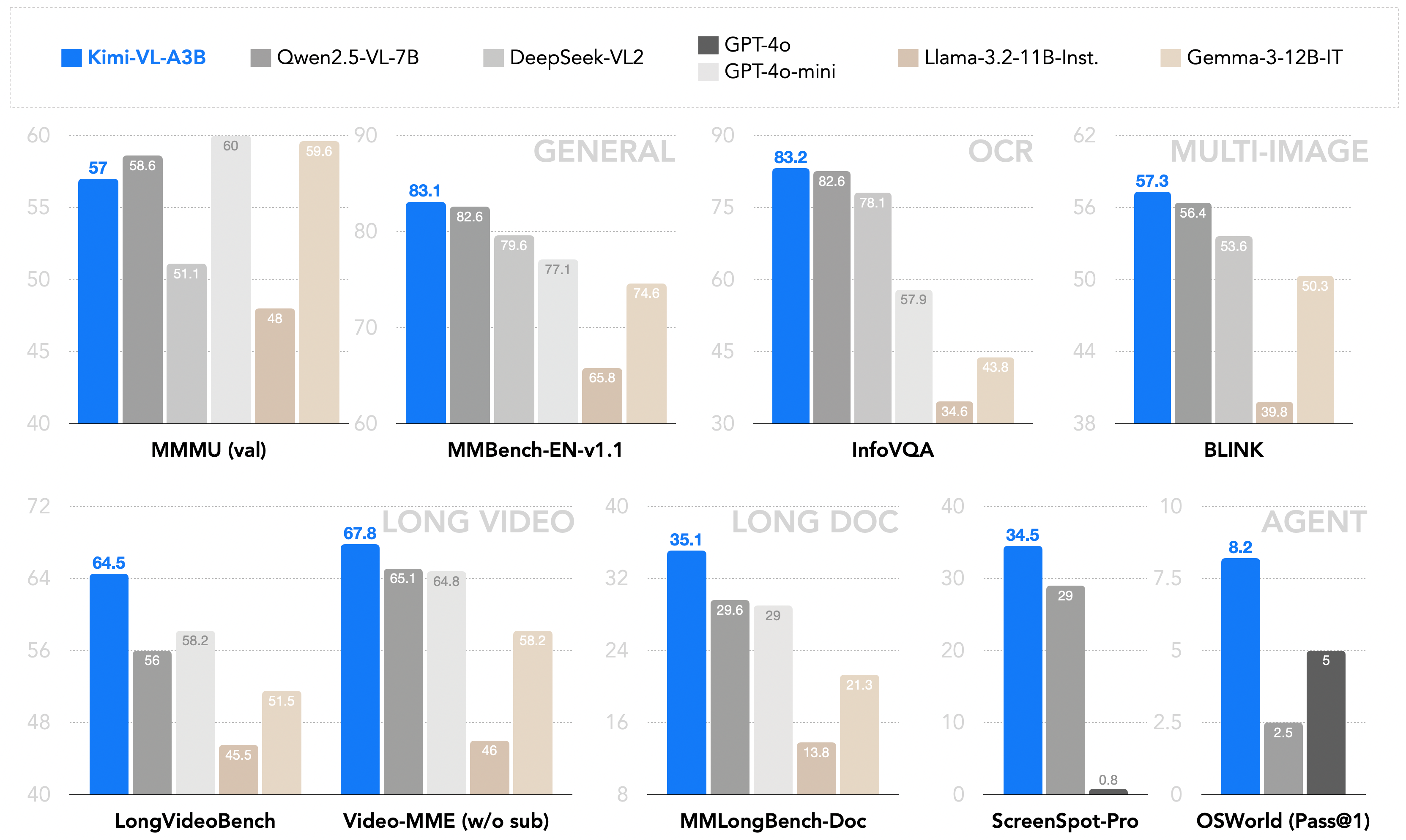
全面对比(包括 GPT-4o 供参考):
| Benchmark (Metric) | GPT-4o | GPT-4o-Mini | Qwen2.5-VL-7B | Llama3.2-11B-Inst. | Gemma3-12B-IT | DeepSeek-VL2 | Kimi-VL-A3B-Instruct |
|---|---|---|---|---|---|---|---|
| Architecture | - | - | Dense | Dense | Dense | MoE | MoE |
| # Act. Params (LLM+VT) | - | - | 7.6B+0.7B | 8B+2.6B | 12B+0.4B | 4.1B+0.4B | 2.8B+0.4B |
| # Total Params | - | - | 8B | 11B | 12B | 28B | 16B |
| College-level | |||||||
| MMMU-Val (Pass@1) | 69.1 | 60.0 | 58.6 | 48 | 59.6 | 51.1 | 57.0 |
| VideoMMMU (Pass@1) | 61.2 | - | 47.4 | 41.8 | 57.2 | 44.4 | 52.6 |
| MMVU-Val (Pass@1) | 67.4 | 61.6 | 50.1 | 44.4 | 57.0 | 52.1 | 52.2 |
| General | |||||||
| MMBench-EN-v1.1 (Acc) | 83.1 | 77.1 | 82.6 | 65.8 | 74.6 | 79.6 | 83.1 |
| MMStar (Acc) | 64.7 | 54.8 | 63.9 | 49.8 | 56.1 | 55.5 | 61.3 |
| MMVet (Pass@1) | 69.1 | 66.9 | 67.1 | 57.6 | 64.9 | 60.0 | 66.7 |
| RealWorldQA (Acc) | 75.4 | 67.1 | 68.5 | 63.3 | 59.1 | 68.4 | 68.1 |
| AI2D (Acc) | 84.6 | 77.8 | 83.9 | 77.3 | 78.1 | 81.4 | 84.9 |
| Multi-image | |||||||
| BLINK (Acc) | 68.0 | 53.6 | 56.4 | 39.8 | 50.3 | - | 57.3 |
| Math | |||||||
| MathVista (Pass@1) | 63.8 | 52.5 | 68.2 | 47.7 | 56.1 | 62.8 | 68.7 |
| MathVision (Pass@1) | 30.4 | - | 25.1 | 13.6 | 32.1 | 17.3 | 21.4 |
| OCR | |||||||
| InfoVQA (Acc) | 80.7 | 57.9 | 82.6 | 34.6 | 43.8 | 78.1 | 83.2 |
| OCRBench (Acc) | 815 | 785 | 864 | 753 | 702 | 811 | 867 |
| OS Agent | |||||||
| ScreenSpot-V2 (Acc) | 18.1 | 6.9 | 84.2 | - | - | - | 92.8 |
| ScreenSpot-Pro (Acc) | 0.8 | - | 29.0 | - | - | - | 34.5 |
| OSWorld (Pass@1) | 5.03 | - | 2.5 | - | - | - | 8.22 |
| WindowsAgentArena (Pass@1) | 9.4 | 2.7 | 3.4 | - | - | - | 10.4 |
| Long Document | |||||||
| MMLongBench-Doc (Acc) | 42.8 | 29.0 | 29.6 | 13.8 | 21.3 | - | 35.1 |
| Long Video | |||||||
| Video-MME (w/o sub.) | 71.9 | 64.8 | 65.1 | 46.0 | 58.2 | - | 67.8 |
| Video-MME (w sub.) | 77.2 | 68.9 | 71.6 | 49.5 | 62.1 | - | 72.6 |
| MLVU-MCQ (Acc) | 64.6 | 48.1 | 70.2 | 44.4 | 52.3 | - | 74.2 |
| LongVideoBench (val) | 66.7 | 58.2 | 56.0 | 45.5 | 51.5 | - | 64.5 |
| Video Perception | |||||||
| EgoSchema (full) | 72.2 | - | 65.0 | 54.3 | 56.9 | 38.5 | 78.5 |
| VSI-Bench | 34.0 | - | 34.2 | 20.6 | 32.4 | 21.7 | 37.4 |
| TOMATO | 37.7 | 28.8 | 27.6 | 21.5 | 28.6 | 27.2 | 31.7 |
我们将介绍如何使用 transformers 库在推理阶段使用我们的模型。建议使用 python=3.10, torch>=2.1.0 和 transformers=4.48.2 作为开发环境。
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = "./figures/demo.png"
image = Image.open(image_path)
messages = [
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "What is the dome building in the picture? Think step by step."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=image, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=512)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(response)
Kimi-VL-A3B-Thinking
凭借有效的长思考能力,Kimi-VL-A3B-Thinking 在 MathVision 基准测试中的性能可媲美 30B/70B 前沿开源 VLM:
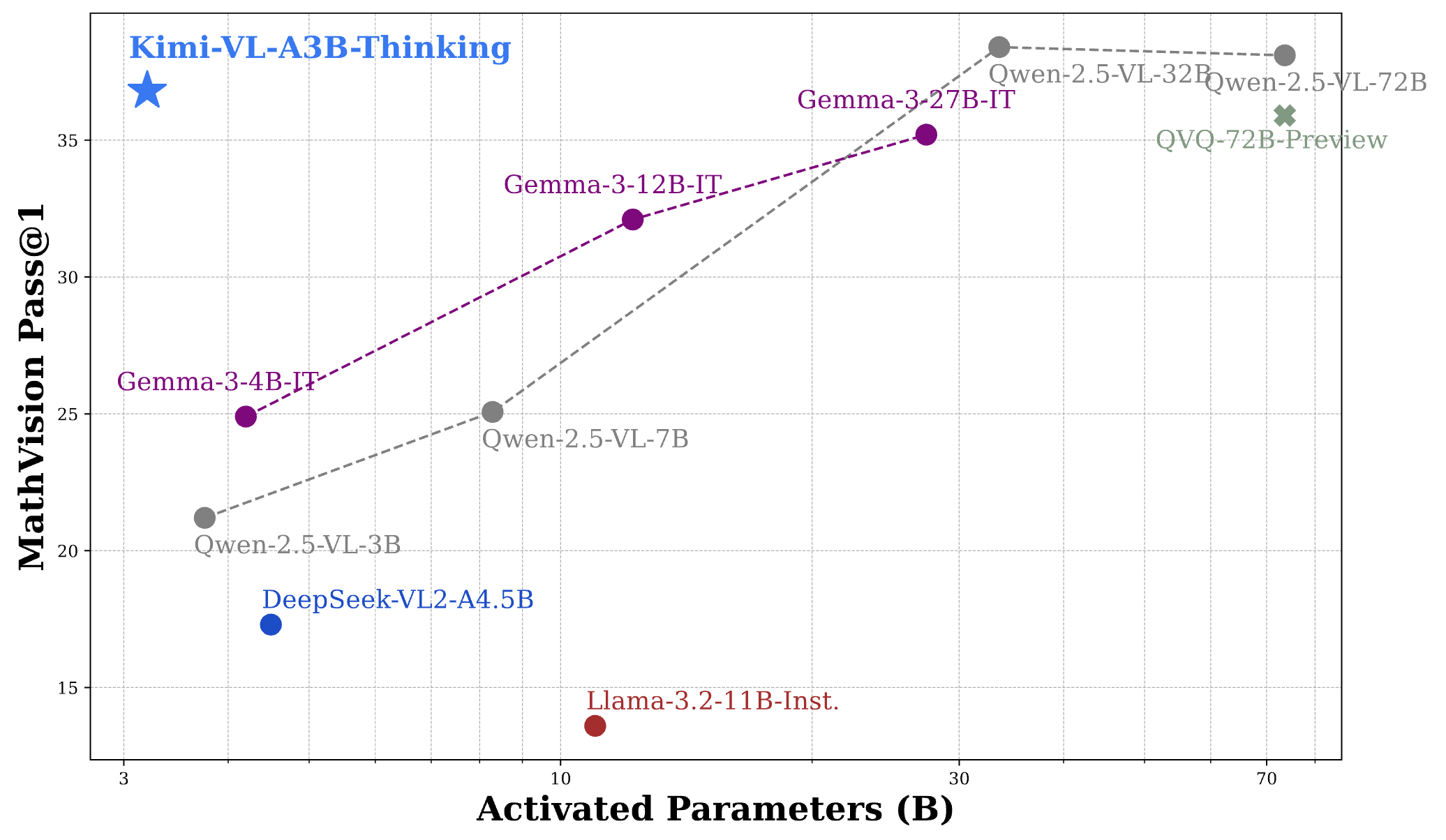
| Benchmark (Metric) | GPT-4o | GPT-4o-mini | Qwen2.5-VL-72B | Qwen2.5-VL-7B | Gemma-3-27B | Gemma-3-12B | o1-1217 | QVQ-72B | Kimi-k1.5 | Kimi-VL-Thinking-A3B |
|---|---|---|---|---|---|---|---|---|---|---|
| Thinking Model? | ✅ | ✅ | ✅ | ✅ | ||||||
| MathVision (full) (Pass@1) | 30.4 | - | 38.1 | 25.1 | 35.5 | 32.1 | - | 35.9 | 38.6 | 36.8 |
| MathVista (mini) (Pass@1) | 63.8 | 56.7 | 74.8 | 68.2 | 62.3 | 56.4 | 71.0 | 71.4 | 74.9 | 71.3 |
| MMMU (val) (Pass@1) | 69.1 | 60.0 | 74.8 | 58.6 | 64.8 | 59.6 | 77.3 | 70.3 | 70.0 | 61.7 |
| 我们将介绍如何使用 transformers 库在推理阶段使用我们的模型。建议使用 python=3.10, torch>=2.1.0 和 transformers=4.48.2 作为开发环境。 |
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Thinking"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_paths = ["./figures/arch.png", "./figures/thinking_perf.png"] # 官方Demo图片错误,我直接换了其他的用于测试多图理解
images = [Image.open(path) for path in image_paths]
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path} for image_path in image_paths
] + [{"type": "text", "text": "Please infer step by step who this manuscript belongs to and what it records"}],
},
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=images, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=2048)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(response)


















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









