







FireRedASR 简介
FireRedASR 是 FireRed 团队提出的开源工业级自动语音识别(ASR)模型。它支持普通话、中国方言和英语,在公开的普通话自动语音识别基准测试中达到了新的最高水平(SOTA)。它还具有出色的歌词识别能力。
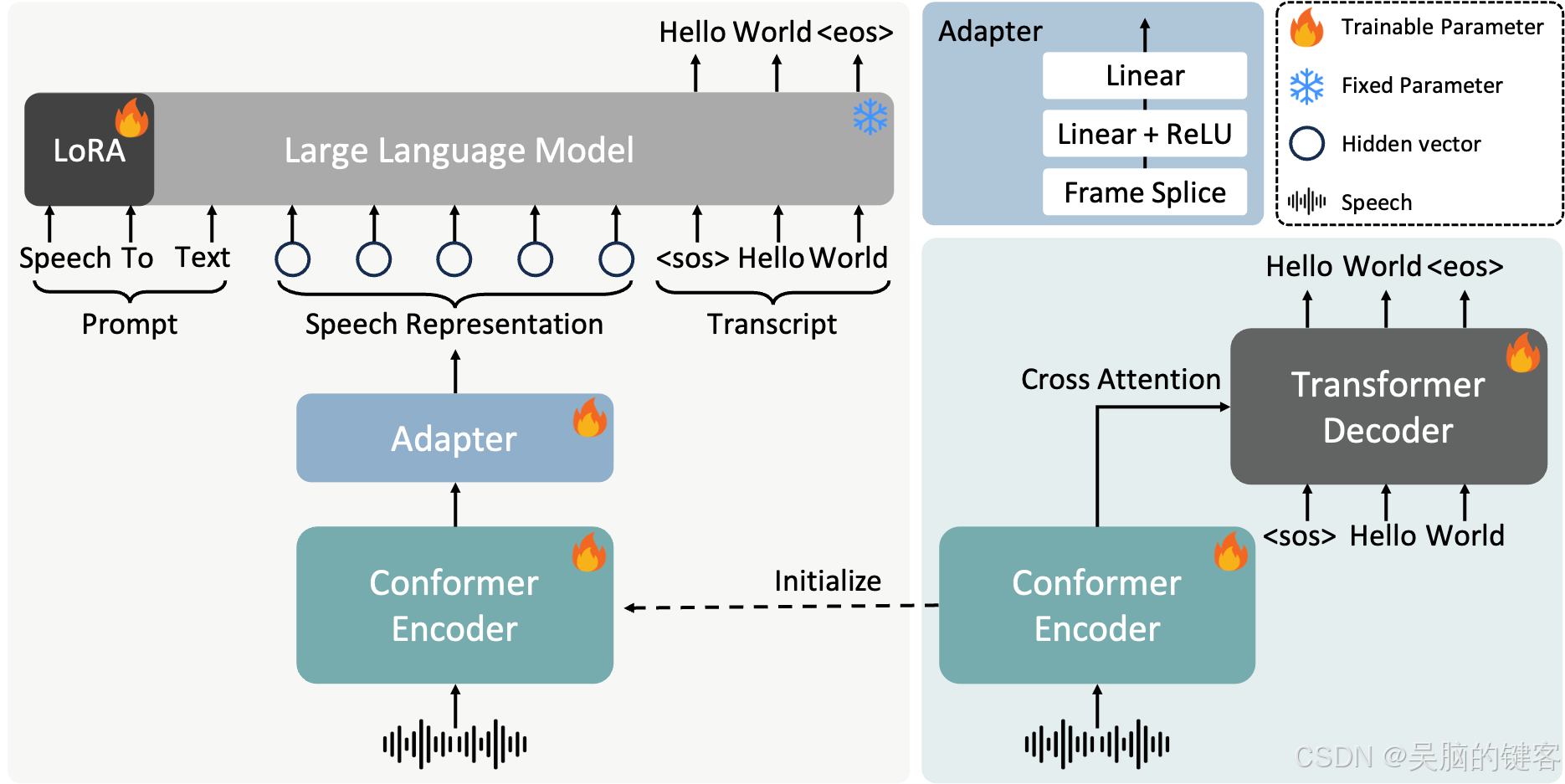
FireRedASR 的核心架构
FireRedASR包含两个变体:
- FireRedASR-LLM:专为实现 SOTA 性能和无缝端到端语音交互而设计。它采用编码器-适配器-LLM 框架,充分利用了大型语言模型 (LLM) 的功能。该模型特别适用于精度要求极高且计算资源不是主要限制因素的应用场景。
- FireRedASR-AED:旨在兼顾高性能和计算效率。它采用基于注意力的编码器-解码器(AED)架构,可作为基于 LLM 的语音模型中的有效语音表示模块。该模型更加紧凑,适用于资源有限的应用。
评估
结果以中文的字符错误率 (CER%) 和英文的单词错误率 (WER%) 为单位进行报告。
公共普通话 ASR 基准评估
| Model | #Params | aishell1 | aishell2 | ws_net | ws_meeting | Average-4 |
|---|---|---|---|---|---|---|
| FireRedASR-LLM | 8.3B | 0.76 | 2.15 | 4.60 | 4.67 | 3.05 |
| FireRedASR-AED | 1.1B | 0.55 | 2.52 | 4.88 | 4.76 | 3.18 |
| Seed-ASR | 12B+ | 0.68 | 2.27 | 4.66 | 5.69 | 3.33 |
| Qwen-Audio | 8.4B | 1.30 | 3.10 | 9.50 | 10.87 | 6.19 |
| SenseVoice-L | 1.6B | 2.09 | 3.04 | 6.01 | 6.73 | 4.47 |
| Whisper-Large-v3 | 1.6B | 5.14 | 4.96 | 10.48 | 18.87 | 9.86 |
| Paraformer-Large | 0.2B | 1.68 | 2.85 | 6.74 | 6.97 | 4.56 |
ws means WenetSpeech.
公共中文方言和英语 ASR 基准评估
| Test Set | KeSpeech | LibriSpeech test-clean | LibriSpeech test-other |
|---|---|---|---|
| FireRedASR-LLM | 3.56 | 1.73 | 3.67 |
| FireRedASR-AED | 4.48 | 1.93 | 4.44 |
| Previous SOTA Results | 6.70 | 1.82 | 3.50 |
FireRedASR 的用法
从 huggingface 下载模型文件,并将它们放到 pretrained_models 文件夹中。
如果您要使用 FireRedASR-LLM-L,您还需要下载 Qwen2-7B-Instruct 并将其放在 pretrained_models文件夹中。然后转到文件夹 FireRedASR-LLM-L并运行 $ ln -s ../Qwen2-7B-Instruct
设置
创建 Python 环境并安装依赖项
$ git clone https://github.com/FireRedTeam/FireRedASR.git
$ conda create --name fireredasr python=3.10
$ pip install -r requirements.txt
设置 Linux PATH和PYTHONPATH
$ export PATH=$PWD/fireredasr/:$PWD/fireredasr/utils/:$PATH
$ export PYTHONPATH=$PWD/:$PYTHONPATH
将音频转换为 16kHz 16 位 PCM 格式
ffmpeg -i input_audio -ar 16000 -ac 1 -acodec pcm_s16le -f wav output.wav
快速入门
$ cd examples
$ bash inference_fireredasr_aed.sh
$ bash inference_fireredasr_llm.sh
命令行用法
$ speech2text.py --help
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
Python
from fireredasr.models.fireredasr import FireRedAsr
batch_uttid = ["BAC009S0764W0121"]
batch_wav_path = ["examples/wav/BAC009S0764W0121.wav"]
# FireRedASR-AED
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"nbest": 1,
"decode_max_len": 0,
"softmax_smoothing": 1.25,
"aed_length_penalty": 0.6,
"eos_penalty": 1.0
}
)
print(results)
# FireRedASR-LLM
model = FireRedAsr.from_pretrained("llm", "pretrained_models/FireRedASR-LLM-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"decode_max_len": 0,
"decode_min_len": 0,
"repetition_penalty": 3.0,
"llm_length_penalty": 1.0,
"temperature": 1.0
}
)
print(results)
FireRedTTS 简介
FireRedTTS 是 FireRed 团队提出的一个开源基础文本到语音(TTS)框架。它旨在满足日益增长的个性化和多样化生成语音应用需求。该框架由三部分组成:数据处理、基础系统和下游应用。
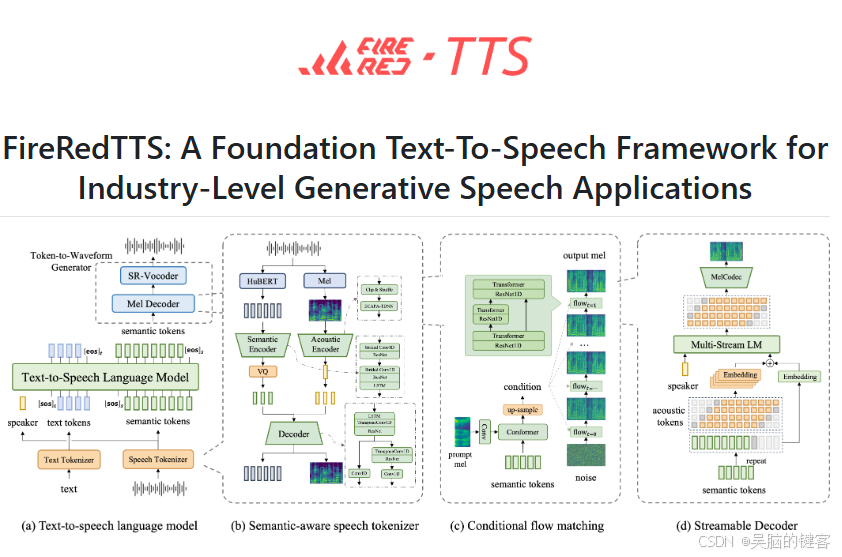
FireRedTTS 的核心架构
- 数据处理管道:FireRedTTS 拥有全面的数据处理管道,可将海量原始音频转换为大规模高质量 TTS 数据集。该管道包括语音增强、语音分割、说话者聚类、转录和数据过滤。
- Foundation TTS System:该系统采用基于语言模型的方法。语音信号通过语义感知语音标记器压缩成离散的语义标记,并可由提示文本和音频的语言模型生成。然后使用两级波形发生器将这些标记解码为高保真波形。
- 下游应用:FireRedTTS 有两个主要应用:用于配音的语音克隆和用于聊天机器人的类人语音生成。在配音方面,它可以实现用户生成内容(UGC)场景下的零次语音克隆,以及专业用户生成内容(PUGC)场景下的少量微调。对于聊天机器人,它可以通过指令调整生成具有副语言行为和情感的可控类人语音。
功能和优势
- 高质量语音合成:FireRedTTS 可以高保真地生成富有表现力和多样化的语音。与传统的 TTS 方法相比,它能以更少的训练数据实现录音棚级别的语音合成。
- 个性化和多样化:该框架支持个性化和多样化语音生成,因此适用于视频配音和聊天机器人等各种应用。
- 强大的上下文学习能力:FireRedTTS 展示了强大的上下文学习能力,使其能够稳定地合成与提示文本和音频一致的高质量语音。
FireRedTTS 的使用方法
安装你可以克隆 GitHub 上的 FireRedTTS 仓库,并创建一个 conda 环境来安装所需的依赖项。安装步骤如下:
git clone https://github.com/FireRedTeam/FireRedTTS.git
cd FireRedTTS
# step1.create env
conda create --name redtts python=3.10
# stpe2.install torch (pytorch should match the cuda-version on your machine)
# CUDA 11.8
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# step3.install fireredtts form source
pip install -e .
# step4.install other requirements
pip install -r requirements.txt
- 模型下载:从 Model_Lists 中下载所需的模型文件,并将它们放到 pretrained_models 文件夹中。
- 基本用法:下面举例说明如何使用 FireRedTTS 进行语音合成:
import os
import torchaudio
from fireredtts.fireredtts import FireRedTTS
tts = FireRedTTS(
config_path="configs/config_24k.json",
pretrained_path=<pretrained_models_dir>,
)
rec_wavs = tts.synthesize(
prompt_wav="examples/prompt_1.wav",
text="小红书,是中国大陆的网络购物和社交平台,成立于二零一三年六月。",
lang="zh",
)
rec_wavs = rec_wavs.detach().cpu()
out_wav_path = os.path.join("./example.wav")
torchaudio.save(out_wav_path, rec_wavs, 24000)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









