







什么是激活函数?
首先了解一下神经网络的基本模型

如上图所示,神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
简单来说,激活函数,并不是去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来,即负责将神经元的输入映射到输出端。
为什么需要激活函数?
首先明确一点,激活函数是用来加入非线性因素的,因为线性模型的表达力不够。
假设如果没有激活函数的出现,你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,也就是说没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激活函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可逼近任意函数)
举个例子:二分类问题,如果不使用激活函数,例如使用简单的逻辑回归,只能作简单的线性划分,如下图所示


可见,激活函数能帮助我们引入非线性因素,使得神经网络能够更好地解决更加复杂的问题。
为什么激活函数一般都是非线性的,而不能是线性的呢?
从反面来说,如果所有的激活函数都是线性的,则激活函数 g(z)=z,即 a=z。那么,以两层神经网络为例,最终的输出为:
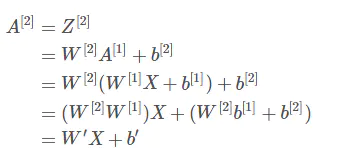
经过推导我们发现网络输出仍是 X 的线性组合。这表明,使用神经网络与直接使用线性模型的效果并没有什么两样。即便是包含多层隐藏层的神经网络,如果使用线性函数作为激活函数,最终的输出仍然是线性模型。这样的话神经网络就没有任何作用了。因此,隐藏层的激活函数必须要是非线性的。
补充一点:因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,运算特征是不断进行循环计算,所以在每代循环过程中,每个神经元的值也是在不断变化的。
三种常用激活函数
一:Sigmoid函数:
先看百科定义:
Sigmoid函数是一个在生物学中常见的S型函数,也称为S型生长曲线。 [1] 在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的激活函数,将变量映射到0,1之间。
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
图形和推导:

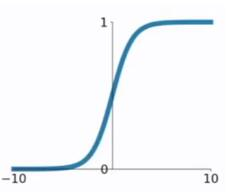
- 在使用逻辑回归做二分类问题时,sigmoid函数常用作逻辑回顾的假设函数,从直觉上理解很好理解,就是在线性回归的基础上套一个sigmoid函数,将线性回归的结果(+∞,-∞),映射到(0,1)范围内,使他变为一个二分类问题。
- sigmoid函数用在神经网络算法时作为激活函数,用于将池化后的特征图代入Sigmoid函数,将特征值映射到0-1的区间,当特征值比较大的时候,获得的激活值比较大;特征值比较小时,激活值也小。(0-1)才可以表示特征值的概率
优点:
1.使用该函数做分类问题时,不仅可以预测出类别,还能够得到近似概率预测。这点对很多需要利用概率辅助决策的任务很有用。
2.对数几率函数是任意阶可导的凸函数,它有着很好的数学性质,很多数值优化算法都可以直接用于求取最优解。
二:tanh函数
百科定义:
tanh是双曲函数中的一个,tanh为双曲正切。在数学中,双曲正切“tanh”是由双曲正弦和双曲余弦这两种基本双曲函数推导而来。
函数:y=tanh x;定义域:R,值域:(-1,1)。y=tanh x是一个奇函数,其函数图像为过原点并且穿越Ⅰ、Ⅲ象限的严格单调递增曲线,其图像被限制在两水平渐近线y=1和y=-1之间。
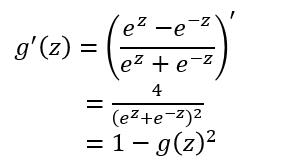
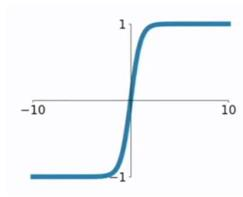
可见该函数是将取值为 (−∞,+∞) 的数映射到 (−1,1) 之间, tanh函数在 0 附近很短一段区域内可看做线性的。由于tanh函数均值为 0 ,因此弥补了sigmoid函数均值为 0.5 的缺点。
三:ReLU函数
百科定义:
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
Relu函数是什么?
首先,relu函数是常见的激活函数中的一种,表达形式如下。
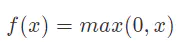
Relu函数的图像和求导后的图像如下:

从表达式和图像可以明显地看出:Relu其实就是个取最大值的函数。
ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。(也就是说:在输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,进而对计算来说是非常有效率的。)正因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。尤其体现在深度神经网络模型(如CNN)中,当模型增加N层之后,理论上ReLU神经元的激活率将降低2的N次方倍。
使用Relu函数有什么优势?
1. 没有饱和区,不存在梯度消失问题。
2.没有复杂的指数运算,计算简单、效率提高。
3.实际收敛速度较快,(ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多,sigmod和tanh要计算指数,计算速度会比较慢)
当然relu也存在不足:就是训练的时候很”脆弱”,很容易就”die”了. 举个例子:一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这个情况发生了,那么这个神经元的梯度就永远都会是0.实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
代码:
#!/usr/bin/python2
# -*- coding:utf-8 -*-
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
plt.figure(figsize=(12,3))
# 数据
x = torch.arange(-5., 5., 0.1)
# Sigmoid 函数(将值限定在0到1之间.)
plt.subplot(1, 3, 1)
plt.title("Sigmoid activation")
y = torch.sigmoid(x)
plt.plot(x.numpy(), y.numpy())
# Tanh 函数(将值限定在-1 到 1 之间)
plt.subplot(1, 3, 2)
y = torch.tanh(x)
plt.title("Tanh activation")
plt.plot(x.numpy(), y.numpy())
# Relu 函数(将负值归零处理)
plt.subplot(1, 3, 3)
y = F.relu(x)
plt.title("ReLU activation")
plt.plot(x.numpy(), y.numpy())
# Show plots
plt.show()
/
/
绘图效果:

后面全连接层还有softmax函数和loss函数,每天学习一点,一起进步
参考:
作者:李_颖Biscuit
链接:https://www.jianshu.com/p/338afb1389c9
作者:LLLiuye
链接:https://www.cnblogs.com/lliuye/p/9486500.html
感谢分享!















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









