







Lasso回归(也称套索回归),是一种正则化的线性回归。与岭回归相同,使用Lasso也是约束系数,使其接近于0,但使用的是L1正则化。lasso惩罚系数是向量的L1范数,换句话说,系数的绝对值之和。L1正则化的结果是,使用lasso时,某些系数刚好为0。这说明某些特征被模型完全忽略。这可以看做是一种自动化的特征选择。
代码实现
同样,将lasso应用在波士顿房价预测上面。完整代码如下:
from sklearn.linear_model import Lasso,Ridge
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import mglearn
# 读取数据,并划分训练集和测试集
X,y = mglearn.datasets.load_extended_boston()
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
# 通过设置不同的alpha值建立三个lasso实例
lasso = Lasso().fit(X_train,y_train)
lasso001 =Lasso(alpha=0.01).fit(X_train,y_train)
lasso00001 = Lasso(alpha=0.0001).fit(X_train,y_train)
# 输出三个lasso实例的信息
print('**********************************')
print("Lasso alpha=1")
print ("training set score:{:.2f}".format(lasso.score(X_train,y_train)))
print ("test set score:{:.2f}".format(lasso.score(X_test,y_test)))
print ("Number of features used:{}".format(np.sum(lasso.coef_!=0)))
print('**********************************')
print("Lasso alpha=0.01")
print ("training set score:{:.2f}".format(lasso001.score(X_train,y_train)))
print ("test set score:{:.2f}".format(lasso001.score(X_test,y_test)))
print ("Number of features used:{}".format(np.sum(lasso001.coef_!=0)))
print('**********************************')
print("Lasso alpha=0.0001")
print ("training set score:{:.2f}".format(lasso00001.score(X_train,y_train)))
print ("test set score:{:.2f}".format(lasso00001.score(X_test,y_test)))
print ("Number of features used:{}".format(np.sum(lasso00001.coef_!=0)))
# 建立岭回归实例
ridge01 = Ridge(alpha=0.1).fit(X_train,y_train)
# 绘制三个lasso和一个岭回归的系数分布结果
plt.figure(figsize = (7,7))
plt.plot(lasso.coef_,'s',label = "Lasso alpha=1")
plt.plot(lasso001.coef_,'^',label = "Lasso alpha=0.01")
plt.plot(lasso00001.coef_,'v',label = "Lasso alpha=0.0001")
plt.plot(ridge01.coef_,'o',label = 'ridge alpha=0.1')
plt.xlabel('Coefficient index')
plt.ylabel('Coefficient magnitude')
plt.ylim(-25,25)
plt.legend(ncol=2,loc=(0,1.05))
plt.show()输出结果为:
**********************************
Lasso alpha=1
training set score:0.27
test set score:0.26
Number of features used:3
**********************************
Lasso alpha=0.01
training set score:0.89
test set score:0.80
Number of features used:34
**********************************
Lasso alpha=0.0001
training set score:0.94
test set score:0.78
Number of features used:101 输出的图像为:
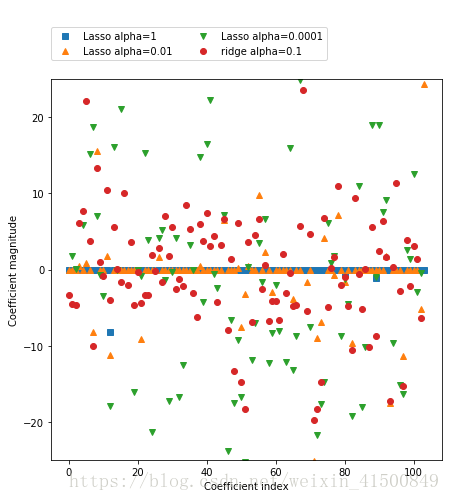
结果整理与分析
结果整理如下:
| 模型 | alpha | 训练集分数 | 测试集分数 | 选择的特征数量 |
|---|---|---|---|---|
| lasso1 | 1.0 | 0.27 | 0.26 | 3 |
| lasso001 | 0.01 | 0.89 | 0.80 | 34 |
| lasso0001 | 0.0001 | 0.94 | 0.78 | 101 |
通过对上表和对图的分析,可以发现:
- alpha=1时,lasso在训练集和测试集上表现的都很差,这表示存在欠拟合。只用到了105个特征的3个。尝试减少alpha,与此同时增加训练次数到100000。
- 当alpha降到0.01时,会拟合一个更复杂的模型,在训练集和测试集上的表现也更好,用到了105个特征中的33个。
- 当alpha降到0.0001时,测试集分数远小于训练集,表明出现过拟合。
在实践中,两个模型一般首选岭回归。但是如果特征很多,并且认为只有其中几个是重要的,那么选择lasso较好。同样,想要一个容易解释的模型,lasso可以给出更容易理解的模型,因为它只选择一部分输入特征。与此同时,scikit-learn还提供了ElasticNet类,结合了lasso个ridge的惩罚项。在实践中,这种结合的效果更好。不过代价是要调节两个参数:一个用于L1正则化,一个用于L2正则化。

















 2435
2435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









