






背景
常规的 encoder-decoder 模型中,decoder 部分采用的是双线性插值的方法,进行分辨率的提升。但是,这种粗暴的方式,对分割问题不能完全适应,作者提出一种新颖的模型来替换掉双线性插值的方式,即依赖于数据的上采样模型(data-dependent upsampling (DUpsampling) to replace bilinear)。这么做的好处是:充分利用了语义分割问题 label space 的冗余性,并且可以恢复出 pixel-wise prediction。
实验
1在以原始输入的1/16or1/32大小的特征图作为输入,得到更加精确的分割结果。
2可以灵活的与encoder组合
实验数据
3.PASCAL VOC:88.1%,30% computation·
4.PASCAL Context: 52.5%
方法:
1 将下采样的底层特征和上采样的高层特征先融合在合并
2 使用双线性上采样恢复全分辨率的预测
本文将Upsample改为下采样;将双线性改为DUpsampling;
在语义分割中,计算损失通常是计算bilinear 上采样得到的结果,如下:
L(F,Y)=Loss( softmax (bilinear (F)),Y))
其中,F是编码器处理的得到的特征图,Y是ground truth
但是bilinear过于简单,影响重建质量。
作者的做法是:计算Y˜与F之间的差异,Y˜ 是Y降低分辨率得到的结果。
为了将Y压缩到Y,需要找到某一种尺度使得这种转化误差最小。
将Y 切成很多个rr大小的窗口,每一个窗口S形为rrC,每个像素点值取值为[0,1],将每个S SS拉伸为一个向量V,其形为N=rr*c.然后转化为低维向量x,然后横向纵向的将之合并为Y˜ 。转化方法为:
x = Pv; v˜ = Wx,
v˜是真实标签v 经压缩后得到的结果.
最小化重建误差:P∗, W∗

这个方程可以用SGD迭代优化,在正交性约束下,可以使用PCA求解。
将Y˜ 作为目标,利用回归损失计算压缩标签Y˜ 和真实值之间的误差:
L(F, Y) = ||F − Y|| .
利用学习到的重建矩阵W对F进行上采样,然后计算像素级的分类损失:
L(F, Y) = Loss(softmax(DUpsample(F)), Y).
其实上述公式很抽象,用图描述更具体。
输出的特征图每个点,与CxN的矩阵W进行矩阵相乘,得到1xN这个向量,再将这1xN的向量reshape为2x2xN/4,就相当于把图上采样为原来的两倍。那么关键就在于这个矩阵W,是怎么得到的呢?
作者认为分割的label图像并不是独立同分布的,其存在结构信息,所以label Y可以几乎没有损失地进行压缩,或者说降维。于是作者就想一般的网络都是将特征图上采样到label大小再做loss,我们可不可以将labelY进行压缩,然后用原本特征图直接与其计算loss,首先作者将Y以rxr为size等分成这些块,对于这些rxr大小的块,把他们拉成一个向量v,在这个向量上做一个压缩,再reshape成原本形状,形成压缩后的label图 Y·。对于压缩的方法,作者使用线性预测的方式,将向量乘以一个矩阵P,那么压缩变为的x如果想再恢复的话就需要乘以P的逆映射矩阵W。这个P及W我们可以通过在训练集中最小化v与重构出的v·来得到,。Loss由特征图上采样与label算loss变为了用DUpsampling为上采样方法的特征图与label算loss.

利用真实标签与压缩值过程学习到的W 处理,如上图,将F上的每个通道值拉伸成1C的向量,然后与W CN进行矩阵乘法,再将得到的结果1N划分为22N/4,整个过程结束就得到通道数减少4倍,分辨率也扩大4倍的上采样结果。
举个例子F=161632;一般的双线性插值法上采样–>R = 323216,本文得到的R =3232*8
Adaptive softmax
用DUpsampling直接结合到encoder-decoder框架中会遇到优化问题,作者再原始的softmax中添加一个参数T,用以锐化/平滑化softmax:

Flexible Aggregation of Convolutional Features
早先的encoder-decoder中,为了预测高分辨率,通常是在decoder中结合通常是1/4初始分辨率特征和高分辨率的低级特征。

而如果在上采样过程中使用DUpsampling,则可以一直下采样直至得到最后的Flast 并且在结合时,可以对下采样中的任意特征进行整合。

实验数据集使用VOC2012
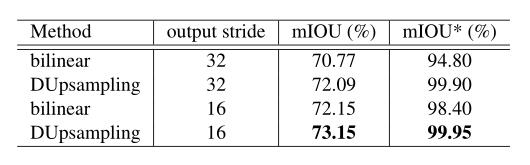
双线性上采样与DUpsampling上采样对比实验;

不同低层的实验结果,测试得出最优的结果;

不同的网络结构的测试结果;

PASCAL VOC 测试集上,用不同的网络进行测试,得出测试结果;
 不同的网络结构在PASCAL Context 进行验证,得出本文的结构是最好的。
不同的网络结构在PASCAL Context 进行验证,得出本文的结构是最好的。
结论:
该文章的提出的下采样的降低计算量,并且提出DUpsampling,对后续的研究提供比较新的方向,值得借鉴。















 9342
9342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









