







GAN对抗学习
-
单词
refiner 修正器
tractable 容易处理的
annotations 注释
plethora 过多
penalize 惩罚
holistically 整体论地
divergence 分歧
aggregate 聚集
self-regularization 正则化
-
参考博文
论文笔记(三) 【Learning from Simulated and Unsupervised Images through Adversarial Training】
对抗学习之Learning from Simulated and Unsupervised Images through Adversarial Training
-
传统的GAN
由两部分构成,生成器G和辨别器D。
生成器用来生成虚假数据,辨别器用来分辨真假。
流程:
G生成图片------D学习区分------G根据D改进自己,生成新图片(循环ing)
知道G,D无法提升自己。莫名想到博弈论的均衡。
训练(参考第4篇)
举个优化效果的例子,假设刚开始的真实样本分布、生成样本分布、判别模型分别对应左图的黑线、绿线、蓝线。

[1]当我们固定生成模型,而优化判别模型时,我们发现判别模型会变得有很好的对黑线和蓝线的区分效果。(偏向于在两者中间)
[2]当我们固定判别模型,改进生成模型时,我们发现生成模型生成的数据分布(绿线)会不断往真实数据分布(黑线)靠拢,也就如第三幅图,使得判别模型很难分离判断。
[3]进行1、2过程进行大量迭代后,我们会得到最后图的效果,生成样本数据分布和真实数据分布基本吻合,判别模型处于纳什均衡,做不了判断。
或者另外一种说法:
对于分辨器,m张真实样本 & m张生成样本 训练分辨器.
如果分辨器生成结果错误(生成器已经以假乱真了),直接反向传播优化分辨器的参数,生成器参数不变。
如果分辨器判断正确,说明生成器还不可以浑水摸鱼,固定分辨器的参数,优化生成器的参数。
重复这样的过程知道判断结果一半正确,一半错误,达到平衡。
-
大意
文章的目的是希望通过构建一个GAN,能够像模拟器生成的合成图片中添加逼真的效果,最终通过分辨器得到一个类似于真实世界中的图像,并且保留模拟器生成图像时的标签,最终得到一批带标签的,真实的图像数据集。
Refiner网络使用的是ResNet。
-
创新点
我觉得这篇真的讲的很好。https://blog.csdn.net/zuber123/article/details/79965988
1.输入为合成图像,在Refiner中学习真实图像的分布

合成图像送入Refiner中,Refiner通过学习到的真实图像的特征,对合成图像进行修正,添加一些逼真的细节。
2.正则化损失函数
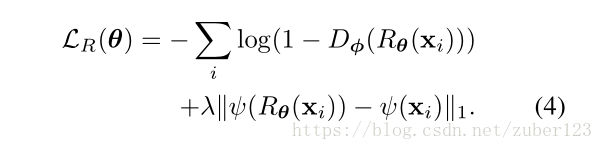
该公式为修正器的损失函数,相比于传统的GAN网络的损失函数,除了交叉熵项,作者多加了一个正则化项,这个正则化项的目的是惩罚修正后的图像和原始图像之间的巨大差别,避免Refiner在修正合成图片的时候用力过猛修改了图像的内容。
3.设计一个buffer,用历史图片去训练分辨器

论文作者指出,对于分辨器来说,无论一张图片是在生成器的任何时候生成的,它都应该将这张图片判别为假,而作者在训练的过程中,设置了一个缓冲区来存储分辨过的修正后图像,而每次向分辨器送入一个批次(mini-batch)的图像时都从buffer中选取一部分,从修正器中最近生成的图片中选取一部分,共同送入分辨器中,这样做的好处就是可以避免修正器重新引入了被分辨器遗忘的伪迹,并且避免训练发散。
4.采用局部分辨器来代替全局分辨器。
最后一点创新,就是作者定义的分辨器是局部分辨器并非一个全局分辨器。将输入分辨器的图像进行分割,将其分成w*h的小块,逐块的送入分辨器中,这样限制了接受域的大小,避免了修正器过分强调对某一部分的修正来欺骗分辨器,而且这样分块之后一幅图像对应着w*h个样本,丰富了样本的数量。
















 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









