







RAG 概念
RAG(Retrieval - Augmented Generation)技术是一种将检索与生成相结合的人工智能技术,旨在利用外部知识源来增强语言模型的生成能力,提高生成内容的质量、准确性和相关性。
具体来说,RAG 技术在处理用户输入的问题或任务时,首先会根据问题的关键词、语义等信息,从预先构建的知识库(如文档库、知识图谱等)中检索出相关的知识片段或信息。然后,将这些检索到的信息与语言模型相结合,作为额外的上下文或提示,引导语言模型生成更准确、更有针对性的回答。通过这种方式,RAG 技术能够避免语言模型在生成内容时出现虚构事实、回答不准确等问题,同时也能够更好地应对一些需要特定领域知识或最新信息的问题。
为什么要使用RAG
LLM 的局限性
将大模型应用于实际场景时就会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
-
LLM的知识不是实时的,不具备知识更新
-
LLM 可能不知道你私有的领域、业务知识
-
LLM 有时会在回答中生成看似合理但实际上是错误的信息
RAG 的优势
-
提高准确性:通过检索相关的信息,RAG 可以提高生成文本的准确性
-
减少训练成本:与需要大量数据来训练的大型生成模型相比,RAG 可以通过检索机制来减少所需的训练数据量,从而降低训练成本。
-
适应性强:RAG 模型可以适应新的或不断变化的数据。由于它们能够检索最新的信息,因此在新数据和事件出现时,它们能够快速适应并生成相关的文本。
-
缓解幻觉问题:传统的生成模型有时会产生与事实不符的内容,即所谓的“幻觉”问题。RAG技术通过引入检索组件,能够限制模型生成不真实或错误的内容,因为模型在生成时会受到检索到的真实信息的约束。
-
增强可追溯性:由于RAG技术在生成文本时参考了外部信息,因此生成的内容具有更好的可追溯性。这意味着可以追踪到生成内容的来源和依据,增加了生成内容的可信度和可靠性。
RAG 技术的发展历程
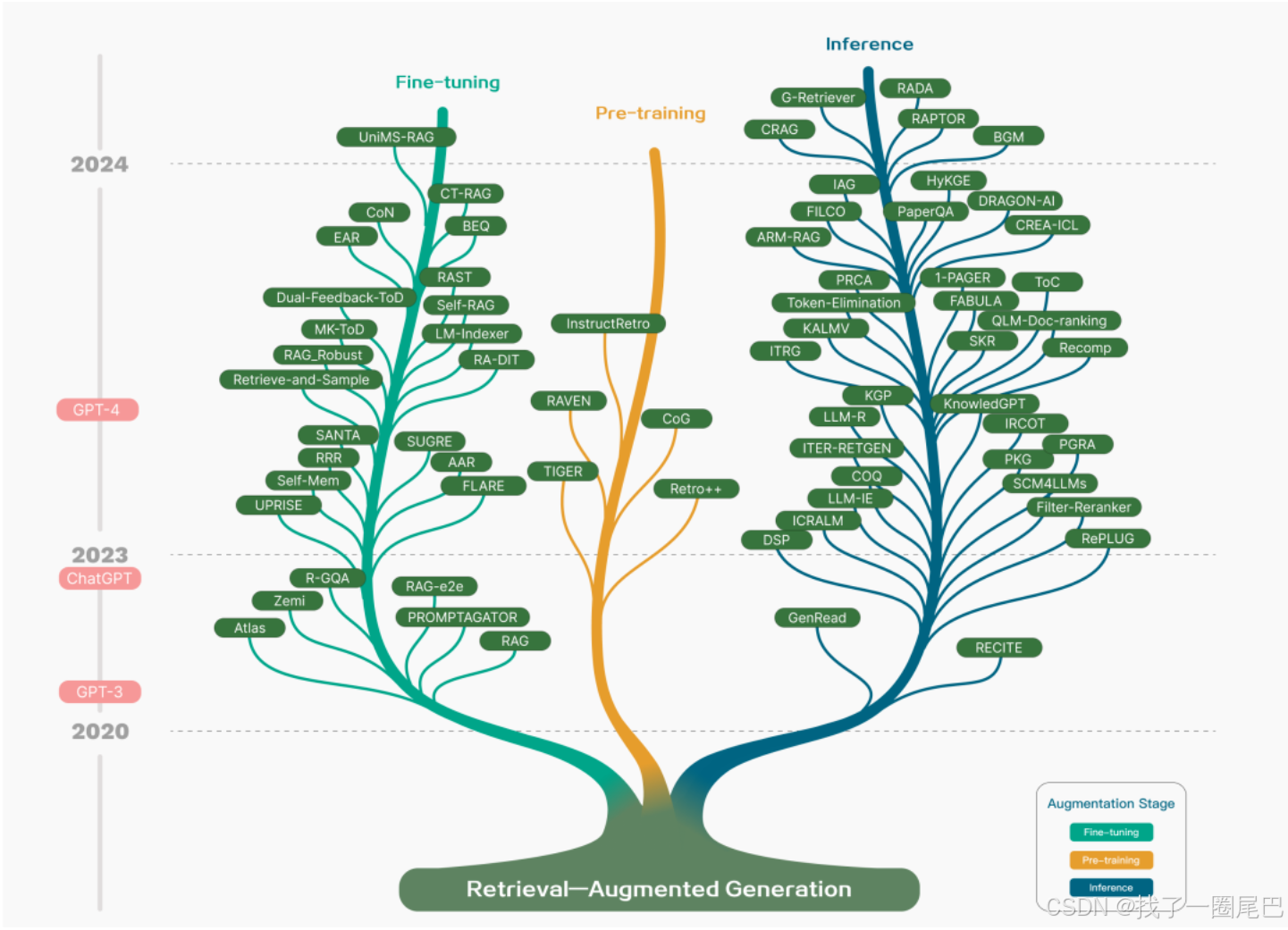
RAG 技术的发展历程大致如下:
-
概念提出:2020 年,RAG 概念被提出,旨在结合信息检索和文本生成,通过从大型文档集合中检索相关信息,并以此辅助生成模型产生更准确丰富的文本输出。
-
早期探索:在 RAG 成为明确概念前,一些早期的简单问答系统和基本文本生成工具,为其发展奠定了基础,它们尝试让机器在检索信息的同时,理解和重新组织信息以生成连贯文本。
-
Naive RAG 阶段:RAG 技术出现后首先被用于 LLMs 的预训练阶段来增强语言模型,随后被用于微调与推理任务中。这一阶段的 Naive RAG 主要包括索引、检索、生成三个基本步骤,即把文档库分割成较短的 Chunk 并构建向量索引,根据问题和 Chunks 的相似度检索相关文档片段,最后以检索到的上下文为条件生成问题的回答。
-
Advanced RAG 阶段:随着研究深入,人们发现 Naive RAG 在检索质量、响应生成质量以及增强过程中存在挑战。于是 Advanced RAG 范式被提出,它在数据索引、检索前和检索后都进行了额外处理,如通过更精细的数据清洗等方法提升文本的一致性、准确性和检索效率,在检索前对问题进行重写、路由和扩充等,检索后对文档库进行重排序、上下文筛选与压缩等。
-
Modular RAG 阶段:技术的进一步发展促使 Modular RAG 出现,它超越了传统的 Naive RAG 检索 - 生成框架,架构更加自由灵活,引入了更多具体功能模块,如查询搜索引擎、融合多个回答等,还将检索与微调、强化学习等技术融合,并且对 RAG 模块之间进行设计和编排,出现了多种 RAG 模式。
-
GraphRAG 阶段:2024 年微软开源的 GraphRAG 开启了 RAG 的第四种范式,它融合了知识图谱,利用图结构编码大量的异构和关系信息,为 RAG 在众多实际应用中提供了更丰富的知识来源。
-
Agentic RAG 阶段:2024 年下半年 Agentic RAG 出现,它是前四种范式的集大成者,融合了数据库、模型微调、逻辑推理、智能体等多种技术,具有自适应性,能够适应各种复杂灵活的任务场景。Agentic RAG是一种融合了Agent能力的RAG,而Agent的核心能力是自主推理与行动。所以Agentic RAG就是将AI智能体的自主规划(如路由、行动步骤、反思等)能力带入到传统的RAG,以适应更加复杂的RAG查询任务。
RAG 范式
-
Naive RAG(朴素 RAG):早期简单的 RAG 实现方式,通常采用基于关键词匹配的检索(如 TF-IDF、BM25 )从静态数据集中获取相关文档,然后将文档信息输入语言模型生成回复。结构和流程简单,检索精度和对复杂语义的理解能力有限。
-
Advanced RAG(高级 RAG):在 Naive RAG 基础上,引入语义理解和增强检索技术。利用密集检索模型(如 Dense Passage Retrieval )和神经排序算法,提升检索的准确性和对上下文语义的理解,能更好处理复杂查询和多跳推理任务。
-
Modular RAG(模块化 RAG):将 RAG 系统拆分为多个可独立配置和替换的模块,如索引模块、检索模块、生成模块等。通过灵活组合模块,实现高度的定制化和可扩展性,适应不同应用场景和任务需求,提高系统的灵活性和可维护性。
-
Graph RAG(图 RAG):结合知识图谱等图结构数据,利用图中节点和边表示实体及关系,增强对数据间复杂关系的理解和推理能力。在处理需要深度语义理解和关系推理的任务(如复杂知识问答、知识图谱补全 )时表现更优。
-
Agentic RAG(代理增强 RAG):在 RAG 系统中引入自主智能代理(Agent)。这些代理具备决策、规划、学习和执行任务的能力,能够根据任务需求和环境变化动态地调整检索和生成策略。代理可以调用不同的工具、管理记忆、进行多步推理和迭代优化,以提高回答的准确性和适应性。例如,在面对复杂问题时,代理可以先规划解决问题的步骤,然后调用合适的检索工具获取信息,再根据获取的信息进行推理和生成答案,并能通过反思和评估不断优化结果,有效应对传统 RAG 在灵活性和智能决策方面的不足。
RAG 架构
Naive RAG 架构
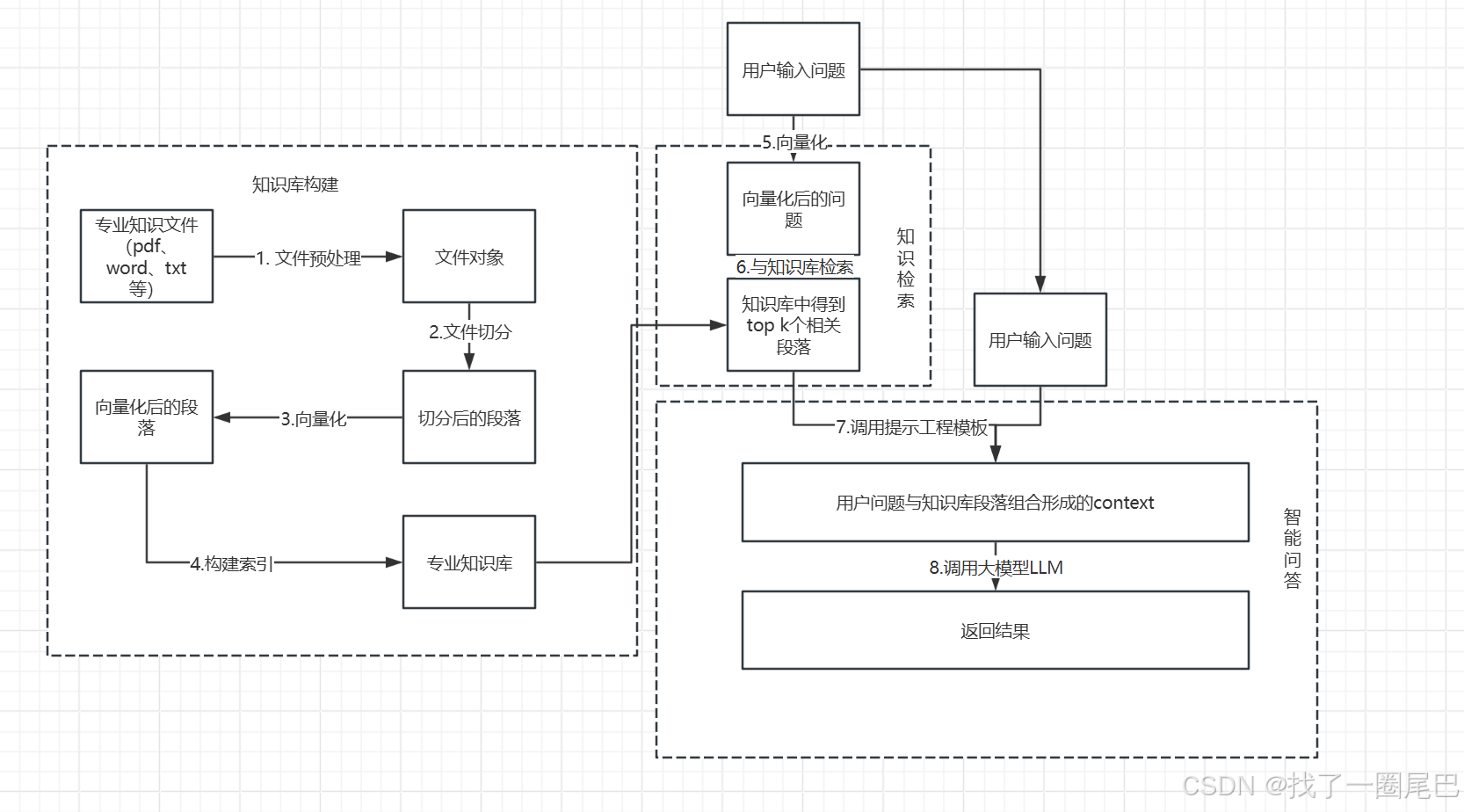
图1 传统的Naive RAG架构
传统的 Naive RAG 架构主要由知识库构建(对应Index)、知识检索、智能问答(对应生成)三部分构成,具体流程如下:
-
索引
-
文件预处理:将专业知识文件(如 pdf、word、txt 等)处理为文件对象。
-
文件切分(chunk):把文件对象切分成较小的段落。
-
向量化(embedding):将切分后的段落转化为向量形式。
-
构建索引(index):依据向量化后的段落构建专业知识库索引,方便后续检索。
-
-
检索
-
向量化问题:将用户输入问题转化为向量。
-
检索相关段落:根据向量表示,从知识库中找出 top - k 个相关段落。
-
-
生成
-
组合上下文:调用提示工程模板,把用户问题与检索到的知识库段落组合成 context。
-
调用大模型生成结果:将上述 context 输入大模型 LLM,由大模型生成并返回最终答案。
-
Advanced RAG 架构
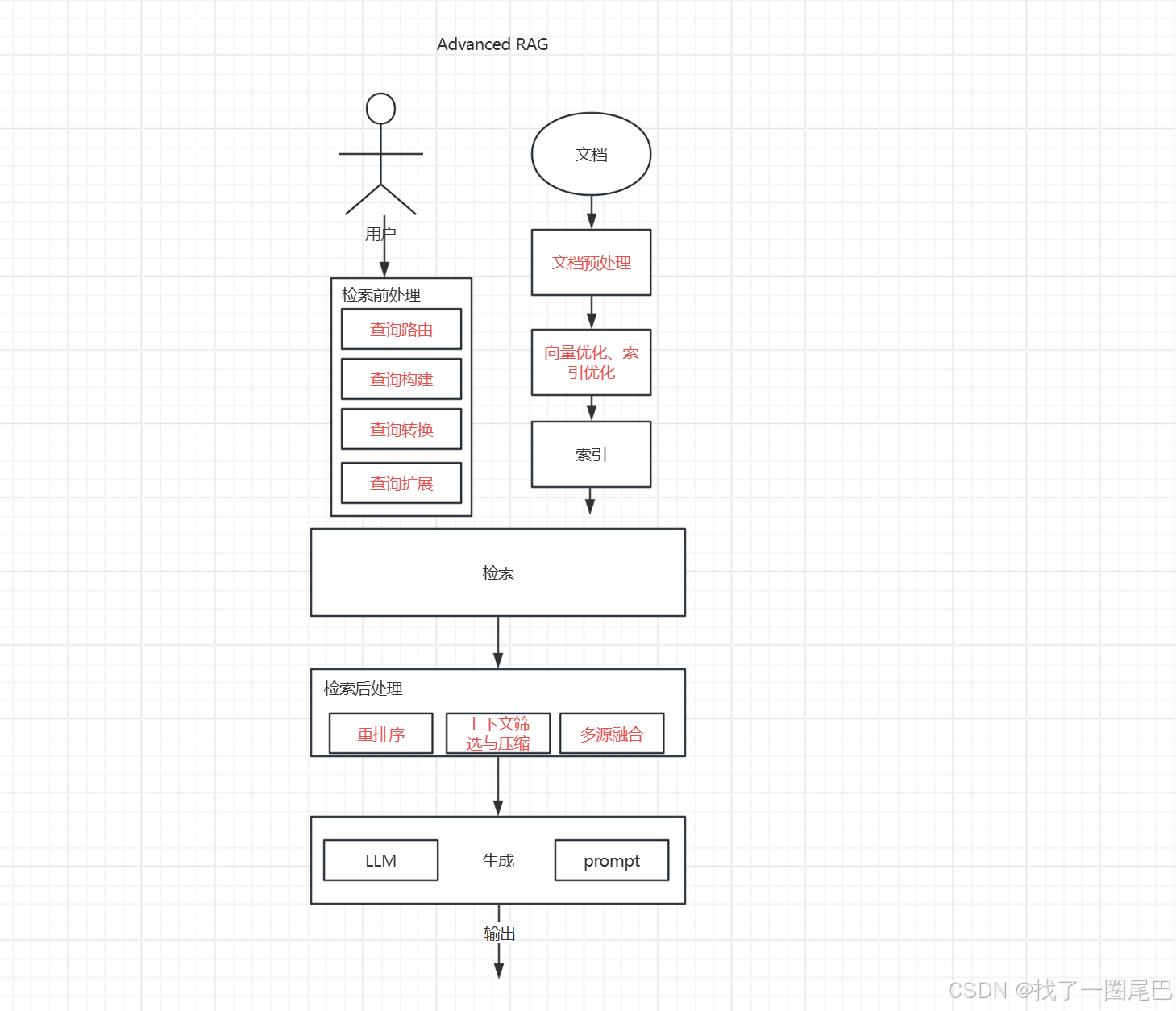
图2 Advanced RAG 架构
Advanced RAG 架构是在 Naive RAG 架构基础上进行优化拓展,主要围绕索引优化、检索前处理、检索后处理展开:
索引优化
-
在文件预处理、文件切分基础上,更关注数据质量,如进行更精细的数据清洗,提升文本一致性与准确性。
-
向量化时可选用更适配的向量表示方法。构建索引时,探索更高效索引结构,如分层索引等,平衡语义完整性与上下文长度。
检索前处理
-
查询路由:
-
Metadata Filter(元数据过滤器):通过对元数据进行筛选,排除不符合条件的数据,缩小查询范围,提升查询效率 。例如在数据库中,根据文件的创建时间、作者等元数据过滤出符合要求的文件记录。
-
Metadata Router/Filter(元数据路由器 / 过滤器):不仅能过滤元数据,还能根据元数据特征将查询请求路由到合适的数据存储或处理组件。像在分布式存储系统中,依据数据的类别标签将查询导向对应的存储节点。
-
-
查询创建:
-
Text - to - cypher:将自然语言文本转换为 Cypher 查询语句。Cypher 是图数据库 Neo4j 的查询语言,该技术可让用户以自然语言描述需求,自动构建图数据库查询 。
-
Text - to - SQL:把自然语言文本转换为 SQL(结构化查询语言)语句。方便不熟悉 SQL 语法的用户通过自然语言实现对数据库的查询操作。
-
-
查询转换:
-
Rewrite(重写):对原始查询进行重新表述,使其更符合目标系统的查询规范或能更好地匹配数据结构。例如将自然语言查询转换为数据库可执行的标准查询语句 。
-
Step - back Prompting(回溯提示):可能是在生成查询时,回顾之前的步骤或信息,给予提示以优化查询。比如在对话式搜索中,根据之前的对话历史调整当前查询 。
-
(Reverse) HyDE:可能涉及到对查询进行编码转换等操作。在文本检索场景下,可能用于将文本查询转换为向量表示,以便于计算相似度进行检索。
-
-
查询扩展:
-
CoVe:可能是基于某种语义理解或上下文感知技术,对原始查询进行扩展。比如在搜索引擎中,根据用户输入的简单词汇,结合知识图谱等技术补充相关语义词汇,丰富查询内容 。
-
Multi Query(多查询):生成多个相关查询,从不同角度获取信息。例如在信息检索场景下,针对一个主题生成多个变体查询,以获取更全面的结果。
-
SubQuery(子查询):将复杂查询拆解为多个子查询,分步执行。在数据库操作中,先通过子查询获取部分数据结果,再基于此进行后续的查询处理。
-
检索后处理
-
Rerank(重排序):对检索到的 top - k 个相关段落,利用更复杂模型或算法重新排序,让相关性高的排在前列。
-
Rule - Based(基于规则的重排):依据预先设定的规则对检索结果进行重新排序。例如在搜索引擎中,可根据网页的更新时间、链接流行度等规则,调整搜索结果的顺序,让更符合规则要求的结果排在前列。
-
Model - Based(基于模型的重排):利用机器学习或深度学习模型来评估检索结果的相关性并重新排序。比如通过训练一个排序模型,学习不同特征(如文本相似度、语义匹配度等)与相关性的关系,进而对检索结果进行更精准的排序。
-
LLM - Based(基于大语言模型的重排):借助大语言模型的理解和推理能力对检索结果排序。大语言模型可以理解查询和文档的语义内容,从语义层面判断文档与查询的相关性,对检索结果重新排序,提升排序的准确性和合理性。
-
-
上下文筛选与压缩:筛选检索段落中关键信息,压缩精简文本,去除冗余,避免 prompt 过长,同时突出关键内容辅助大模型生成。
-
LLMLingua:针对长文本,利用大语言模型相关技术进行处理,实现对检索到的长文本内容的压缩或关键信息提取。比如将长篇文档中的冗余表述去除,保留核心要点。
-
Recomp:重新组合、重新压缩检索到的内容,将多个相关的文本片段进行整合处理,去除重复部分,使信息更加精炼。
-
Tagging - Filter(标记 - 过滤):先对检索结果进行标记,如标记出不同的主题、类别等,然后依据这些标记过滤掉不相关或低价值的内容,只保留符合要求的信息。
-
Selective Context(选择性上下文):从检索结果中挑选出与查询最相关的上下文信息,过滤掉无关的背景内容,聚焦关键信息,为后续处理或回答生成提供精准的信息基础。
-
LLM - Critique(基于大语言模型的评判):使用大语言模型对检索结果进行评估和评判,判断内容的相关性、准确性等,筛选出质量较高的内容用于后续流程,剔除存在错误或不相关的部分。
-
-
多源融合:若存在多个知识源,融合不同来源检索结果,整合信息。
-
Possibility Ensemble(可能性集成):将多个来源或多种方式得到的结果,依据它们各自的可能性或置信度进行整合。例如在多模型协同的 RAG 系统中,不同模型对答案的预测存在差异,通过计算每个模型预测结果的可能性,将它们融合在一起,得到一个综合的、更可靠的结果。
-
RRF(Reciprocal Rank Fusion,倒数秩融合):一种融合多个检索结果列表的方法。它根据每个结果在不同检索列表中的排名,计算倒数秩并进行加权融合,排名越靠前的结果在融合中权重越高,以此来综合多个检索源的结果,提升最终结果的质量 。
-
Modular RAG架构
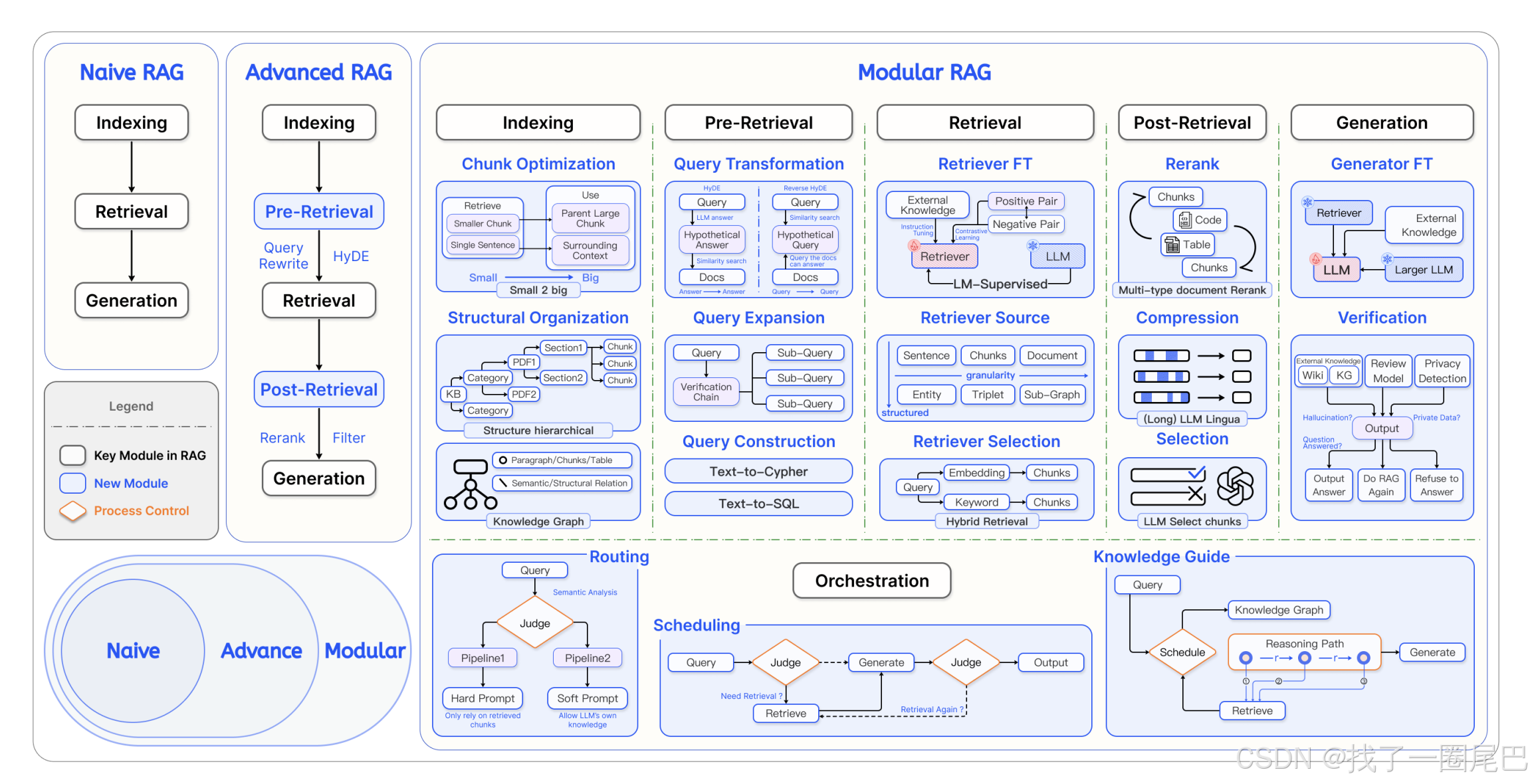
图3 Modular RAG 架构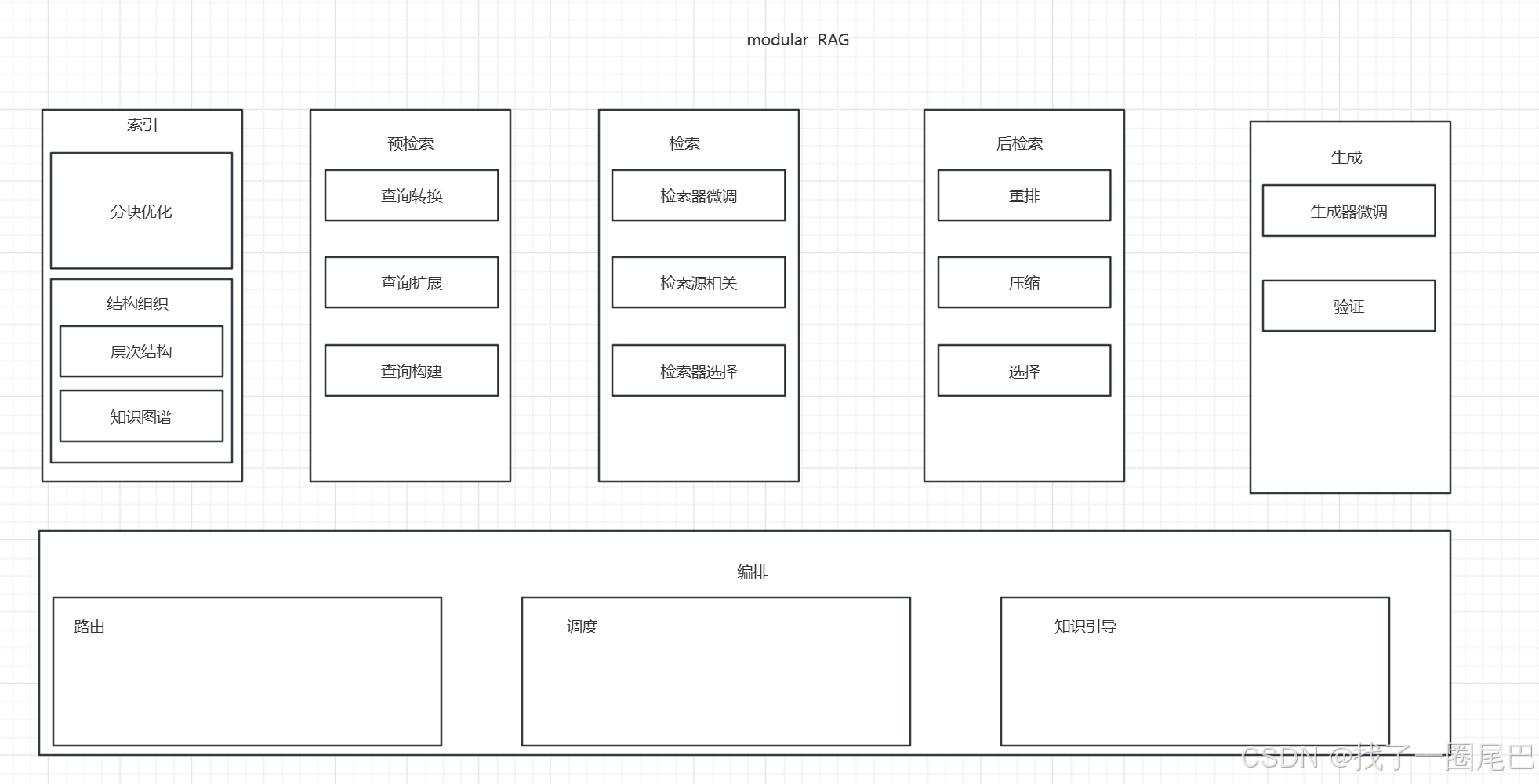
图4 Modular RAG 简化架构
AdvancedRAG 阶段主要解决的问题是「检索什么内容」,ModularRAG 则是解决「什么时候检索」的问题。
Modular RAG 的核心是采用模块化架构,以实现更高的灵活性、可扩展性与可定制性 ,将复杂的RAG系统分解为独立的模块和专门的操作符,形成一个高度可重配置的框架。具体的解决策略包括:
三层架构设计
Modular RAG 总体上可以分为三层架构设计,分别是:
-
Module:关注RAG系统的核心过程,每个阶段被视为一个独立模块。
-
Sub-module:在每个模块内部进一步细化和优化功能。
-
Operator:模块或子模块中具体的功能实现。
六大核心模块
Modular RAG 总体上可以分为六大核心模块,分别是:
Indexing(索引)模块
-
chunk Optimization(分块优化):调整文档分块大小和重叠程度,平衡上下文捕捉与噪声控制。大分块能涵盖更多上下文,但噪声多、处理成本高;小分块噪声少,但上下文可能不足。滑动窗口结合重叠块可增强语义转换,还可通过添加页码、作者等元数据丰富分块,实现筛选检索 。
-
“small 2 big” :区分检索用小分块和合成用大分块,兼顾检索准确性与上下文完整性 。
-
-
Structural Organization(结构组织) :
-
structure hierarchical(层次结构):为文档构建分层结构,节点按父子关系排列并连接分块,每个节点存储数据摘要,加快数据检索与处理,减轻分块提取错觉 。可基于文档段落句子、PDF 等固有结构或文本语义识别来构建 。
-
knowledge Graph(知识图谱) :利用知识图谱构建文档索引,明确概念和实体联系,降低不匹配错误风险,将信息检索转化为语言模型可理解指令,提升检索准确性与响应连贯性 。
-
Pre - Retrieval(预检索)模块
-
query Transformation(查询转换):对原始查询进行重新表述,如将自然语言查询转换为更符合目标检索系统要求的形式,或通过重写、回溯提示等技术优化查询表达 ,提升查询与数据的匹配度 。
-
query Expansion(查询扩展) :基于语义理解或上下文感知,为原始查询添加相关词汇或信息,拓宽查询范围。如利用 CoVe 技术结合知识图谱等,使查询能获取更全面信息 。
-
query Construction(查询构建) :将自然语言转换为特定的结构化查询语言,如 Text - to - cypher(转为图数据库查询语句 )、Text - to - SQL(转为 SQL 语句 ) ,便于在不同类型数据库中精准检索 。
Retrieval(检索)模块
-
Retriever FT(检索器微调):通过微调技术优化检索器性能,使其更好地适应特定任务和数据特点。如利用监督学习方法,基于标注数据调整检索器参数,提升检索准确性 。
-
Retriever Source(检索源相关):涉及对不同检索源的管理和操作,包括连接、选择合适的数据源,如数据库、文档库、知识图谱等 ,确保能从多样来源获取信息 。
-
Retriever selection(检索器选择) :根据任务需求、数据特征等因素,在多种检索器(如稀疏检索器 TF - IDF、BM25 ,密集检索器基于神经网络嵌入 )中挑选最适配的检索器,以实现高效检索 。
Post - Retrieval(后检索)模块
-
rerank(重排):依据一定规则或模型,对检索到的结果重新排序。基于规则的重排根据预设规则调整顺序;基于模型(如机器学习、深度学习模型 )或大语言模型的重排,从语义等层面评估相关性,使最相关结果排在前列 。
-
compression(压缩) :去除检索结果中的冗余信息,精简文本内容。比如剔除重复表述、无关细节,保留核心要点,提高信息密度 。
-
selection(选择) :从检索结果中挑选出与查询最相关、最有用的部分,过滤掉不相关或低价值信息,为后续生成环节提供精准信息 。
Generation(生成)模块
-
generator FT(生成器微调):对用于生成文本的模型(通常是大语言模型 )进行微调,使其生成更符合任务需求的内容。可采用直接微调、知识蒸馏(如 GPT - 4 蒸馏 )、基于反馈的强化学习(RLHF)等方式 。
-
Verification(验证) :对生成的文本进行检查和验证,判断其准确性、一致性和合理性,降低生成内容出现错误或幻觉的风险 。
Orchestration(编排)模块
-
routing(路由):根据查询内容、数据特征和系统状态等,为查询选择合适的处理路径。比如依据问题类型、关键词或语义,将查询导向不同的检索源、检索流程或模型 。
-
scheduling(调度) :确定各模块的执行顺序和时机,合理分配资源,保障系统高效运行。如决定预检索、检索、后检索和生成模块的先后顺序,以及并行或串行执行方式 。
-
knowledge guide(知识引导) :利用知识图谱或其他知识资源,为整个 RAG 流程提供引导和支持,辅助决策,使系统运行更符合知识逻辑 。
GraphRAG架构
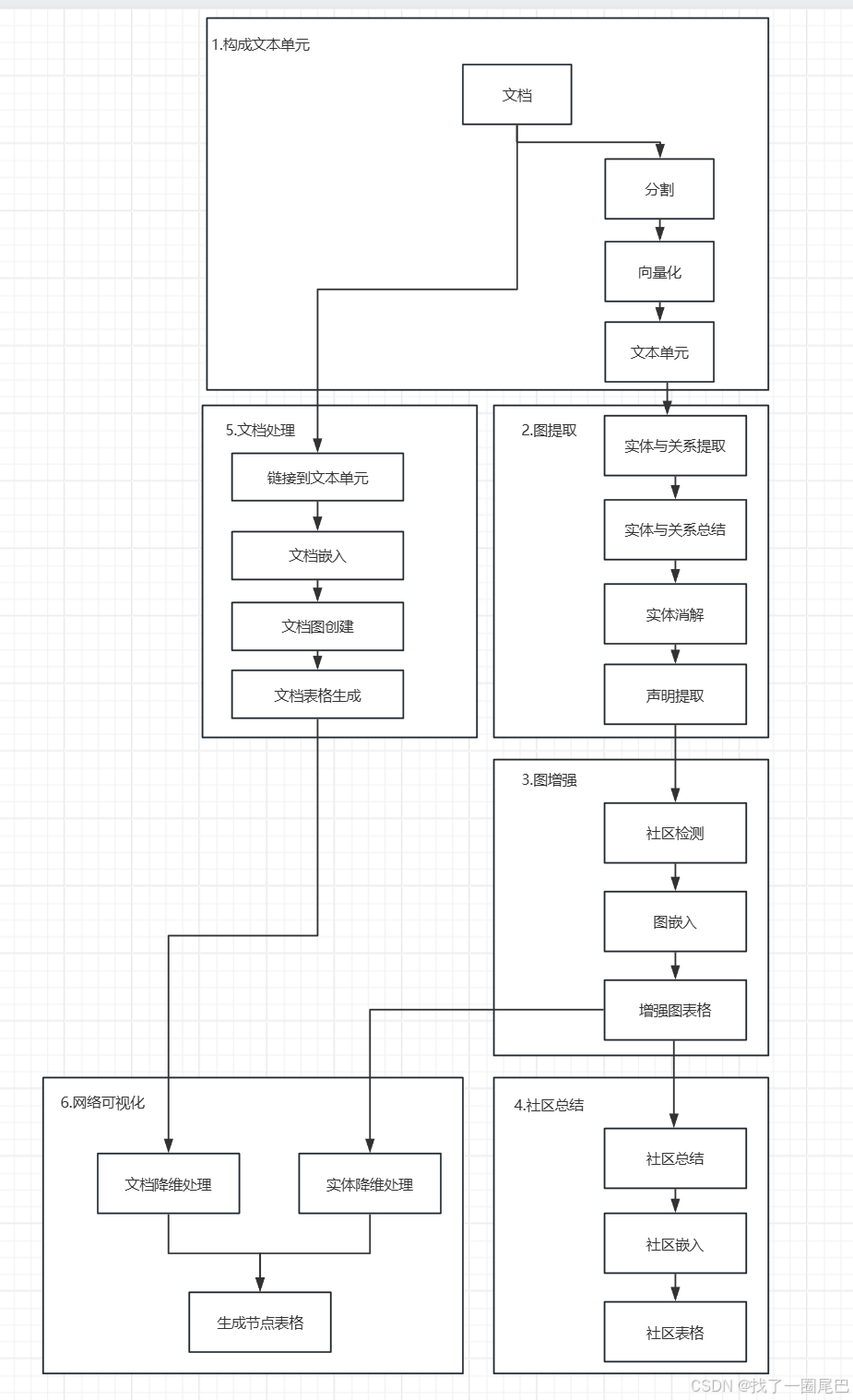
图5 Graph RAG 流程图
Graph RAG 是一种利用知识图谱增强检索增强生成(RAG)的技术,通过识别文本中的实体、关系等信息,提高检索精准度,解决传统 RAG 在复杂推理和检索方面的不足。以下结合流程图介绍其工作流程:
构成文本单元(Compose TextUnits)
将输入的文档(Documents)进行切分(Chunk),划分成固定大小的文本单元,这一步需平衡文本块大小,兼顾召回率与精准度。之后对切分后的文本块进行嵌入(Embed)操作,转化为向量表示,形成文本单元(Text Units) 。
图提取(Graph Extraction)
-
实体与关系提取(Entity & Relationship Extraction):利用大语言模型(LLM)从文本单元中提取实体(如人物、事物等)、实体之间的关系 。
-
实体与关系总结(Entity & Relationship Summarization) :对提取出的实体和关系进行总结归纳 。
-
实体消解(Entity Resolution) :处理可能存在的重复实体元素和节点问题,借助 “社区” 概念,只要相关实体间连接性足够,可避免重复 。
-
声明提取(Claim Extraction) :提取文本中的声明描述等信息 。最终形成图表格(Graph Tables) 。
图增强(Graph Augmentation)
-
社区检测(Community Detection) :使用 Leiden 聚类算法等进行社区检测,将图划分为节点社区,这些节点间连接性更强 。
-
图嵌入(Graph Embedding) :对图结构进行嵌入操作,得到增强后的图表格(Augmented Graph Tables) ,使图结构更适合后续处理 。
-
增强图表格(Augmented Graph Tables):经过社区检测和图嵌入操作后,经处理后得到增强图表格。
社区总结(Community Summarization)
-
社区总结(Community Summarization) :采用从下至上的方式为每个社区及其重要部分生成摘要,涵盖实体、实体关系和声明等 。
-
社区嵌入(Community Embedding) :对社区进行嵌入处理,形成社区表格(Community Tables) 。
-
社区表格(Community Tables):经过社区总结和社区嵌入处理操作,最终得到社区表格。
文档处理(Document Processing)
-
链接到文本单元(Link to TextUnits) :建立与文本单元的链接 。
-
文档嵌入(Document Embedding) :对文档进行嵌入操作 。
-
文档图创建(Document Graph Creation) :创建文档图结构 。
-
文档表格生成(Document Tables) :最终生成文档表格 。
网络可视化(Network Visualization)
通过 Umap 算法对文档(Umap Documents)和实体(Umap Entities)进行降维处理,生成节点表格(Nodes Table) ,用于网络可视化展示,辅助理解数据关系 。
Graph RAG 作为 RAG 发展的第四范式,以知识图谱为核心,深化了对数据关系的理解与利用,尽管存在局限,但为复杂关系场景下的检索增强生成提供了创新性解决方案,引领 RAG 技术向更智能、更贴合实际知识网络的方向演进,也为后续 Agentic RAG 等范式的发展奠定了基础。
Agentic RAG架构
Agentic RAG(代理增强检索生成)是为应对传统 RAG 局限性而演进的先进范式,通过在 RAG 流程中嵌入自主 AI 代理,利用代理特性优化检索与生成过程,提升系统对复杂任务的处理能力。
Agentic RAG 将 ReACT 的推理能力与 Agent 的任务执行能力相结合,创建一个动态和自适应的系统。与遵循固定管道的传统 RAG 不同,Agentic RAG 通过使用 ReACT 根据用户查询的上下文动态协调 Agent,引入了灵活性。这使得系统不仅能够检索和生成信息,还能够根据上下文、不断变化的目标和与之互动的数据采取明智的行动。这些进步使 Agentic RAG 成为一个更强大和灵活的框架。模型不再仅限于被动响应用户查询;相反,它可以主动规划、执行并调整其方法以独立解决问题。这使得系统能够处理更复杂的任务,动态适应新挑战,并提供更具上下文相关性的响应。
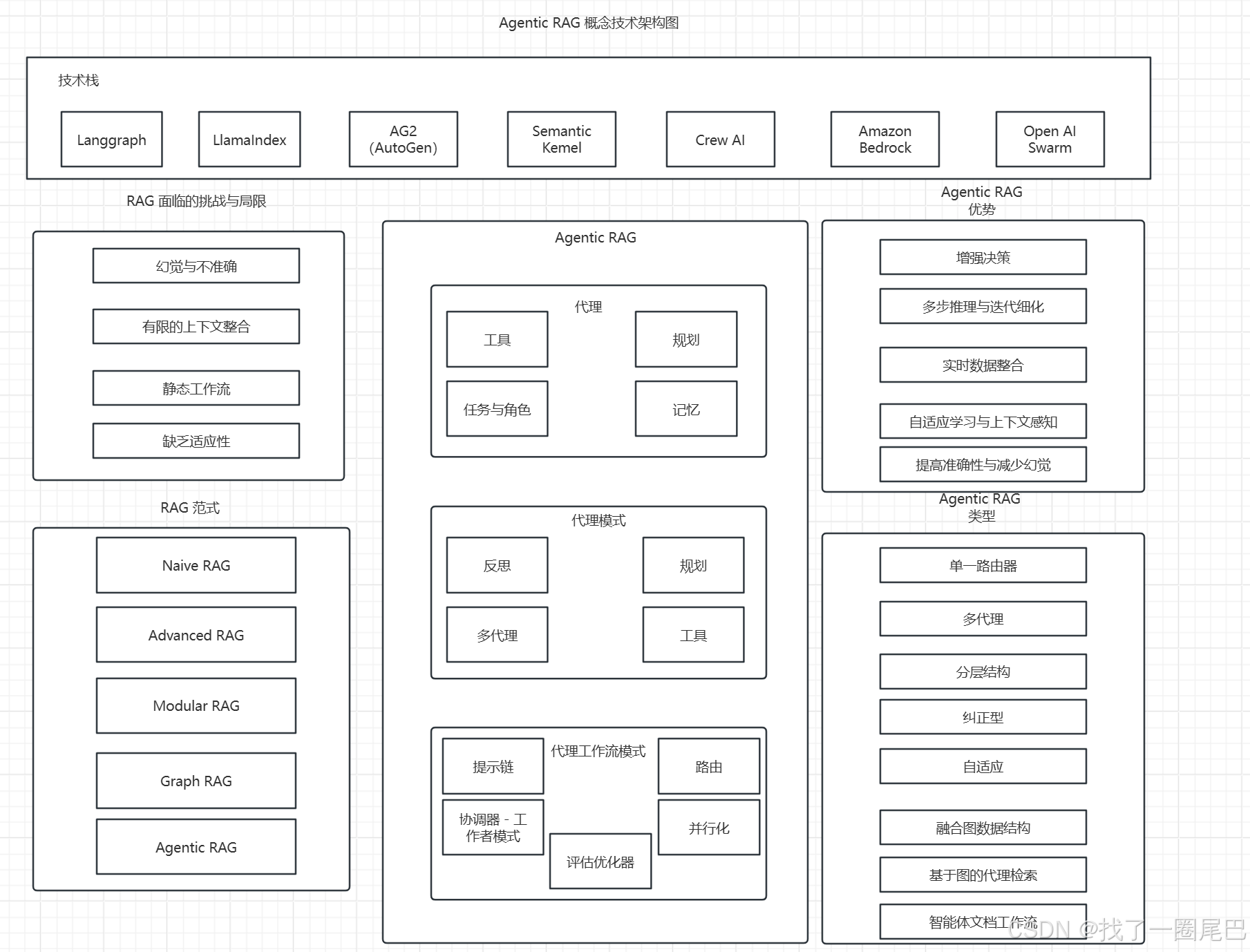
图6 Agentic RAG 概念架构
RAG 面临的挑战与局限
-
Hallucinations & Inaccuracies(幻觉与不准确):RAG 系统可能生成与事实不符或无依据的内容。这是因为语言模型在生成文本时,可能会基于训练数据中的模式生成看似合理但实际错误的信息。例如在知识问答中,给出错误的历史事件时间、科学知识解释等。
-
Limited Contextual Integration(有限的上下文整合):RAG 在处理长文本或复杂语境时,难以全面整合上下文信息。可能出现对前文信息遗忘、无法关联多段相关内容等情况,导致生成的回答不连贯或偏离主题。
-
Static Workflow(静态工作流):传统 RAG 系统的工作流程相对固定,缺乏灵活性。面对不同类型任务或数据变化时,难以动态调整流程和策略,无法高效适应新情况。
-
Lack Adaptibility(缺乏适应性):RAG 系统对新任务、新领域或数据分布变化的适应能力不足。当应用场景或用户需求发生改变,不能快速调整自身以提供准确有效的服务。
AgentRAG 核心组成
-
Agent(代理)
-
Tools(工具):代理可调用外部工具(如搜索引擎、数据库 API 等),扩展信息获取与处理能力。例如,在金融分析中调用实时行情 API 获取数据。
-
Planning(规划):代理能制定任务步骤,如在多文档对比任务中,规划先检索、再对比、最后总结的流程。
-
Task + Role(任务与角色):明确代理职责,如在多代理协作中,有的代理负责专业数据检索,有的负责结果整合。
-
Memory(记忆):保存上下文与历史信息,支持持续交互。如客服场景中记录对话历史,确保回答连贯。
-
-
Agentic Pattern(代理模式)
-
Reflection(反思):评估任务执行过程,调整策略。如发现检索结果不准确时,反思并优化查询方式。
-
Planning(规划):宏观规划任务流程,协调多步骤操作。
-
Multi - Agents(多代理):多个代理协作处理复杂任务。如学术研究中,不同代理分别负责文献检索、数据验证、结果分析。
-
Tools(工具利用):结合工具增强代理能力,提升信息处理效率。
-
-
Agentic Workflow Pattern(代理工作流模式)
-
Prompt Chaining(提示链):串联多个提示,逐步引导模型处理复杂查询。如先让模型理解问题背景,再深入分析。
-
Routing(路由):根据任务需求选择合适数据源或工具。如法律查询中,路由到法规数据库或案例库。
-
-
Orchestrator - workers(协调器 - 工作者模式):协调器分配任务给工作者代理,如主代理分配子任务给多个检索代理。
-
Parallelization(并行化):同时执行多个任务,缩短处理时间。如同时检索多个数据源信息。
-
Evaluator - Optimizer(评估优化器):评估结果并优化,提升回答质量。
-
Agentic RAG 的优势
-
Enhanced Decision - Making(增强决策):代理基于分析与规划做出更合理决策,如在投资场景中综合多因素决策。
-
Multi - Step Reasoning & Iterative Refinement(多步推理与迭代细化):支持复杂推理,如科研中的多跳逻辑推导,并通过迭代优化结果。
-
Real - Time Data Integration(实时数据整合):实时获取外部数据(如新闻、市场数据),确保回答时效性。
-
Adaptive Learning & Context Awareness(自适应学习与上下文感知):根据上下文调整策略,如客服中根据用户情绪与历史对话调整回复。
-
Improved Accuracy & Reduced Hallucinations(提高准确性与减少幻觉):代理验证信息,减少模型编造内容,如医疗咨询中基于权威数据回答。
Agentic RAG 的类型
-
Single Router(单一路由器):
-
原理:基于简单规则或预设条件,从有限的数据源或工具集合中进行选择,将输入请求导向对应的资源。例如,在一个只接入了某特定新闻数据库的问答系统中,单一路由器直接将用户的新闻相关查询指向该数据库进行检索。
-
应用场景:适用于业务场景相对单一、数据类型固定且对处理速度要求较高的情况。如特定行业的简单信息查询系统,像小型电商平台查询商品基本信息,数据源只有商品数据库,单一路由器可快速定位并返回结果。
-
-
Multi - Agent(多代理):
-
原理:由多个功能各异的代理协同工作,每个代理承担特定任务,如信息检索、数据处理、结果验证等。代理之间通过通信和协作,共同完成复杂任务。比如在大型科研项目管理中,文献检索代理负责收集相关研究资料,数据分析代理对实验数据进行处理,结果整合代理将各部分成果汇总。
-
应用场景:适用于复杂、涉及多领域知识或多步骤处理的任务,如大型企业的战略规划、跨学科科研项目研究、智慧城市的综合管理等。
-
-
Hierarchical(分层结构):
-
原理:按照层级关系组织代理,高层代理负责整体规划、决策制定和任务分配,底层代理执行具体操作。类似于企业的组织架构,高层管理者确定战略方向,基层员工负责具体业务执行。如在城市交通管理中,高层代理制定交通流量调控策略,底层代理控制各个路口信号灯等设备。
-
应用场景:广泛应用于具有明显层级关系、需要集中管控和分步执行的场景,如大型企业运营管理、政府部门行政事务处理、军事指挥系统等。
-
-
Corrective(纠正型):
-
原理:持续监控输出结果,通过预设的评估标准或模型判断结果是否存在偏差。一旦发现回答不准确、偏离主题或存在错误时,触发重新检索、重新生成等机制进行修正。例如在智能客服系统中,若用户反馈回答错误,纠正型代理会重新检索知识库并生成新的回复。
-
应用场景:对回答准确性要求极高的场景,如医疗诊断辅助系统、法律条文咨询系统、金融投资建议系统等,这些领域错误信息可能导致严重后果。
-
-
Adaptive(自适应):
-
原理:通过实时感知环境变化(如用户行为、数据特征、外部条件改变等),自动调整内部策略和处理流程。例如电商推荐系统中,根据用户浏览、购买记录的变化,自适应调整推荐算法和推荐内容。
-
应用场景:应用于动态性强、用户需求多变的场景,如互联网广告投放、个性化学习系统、金融市场风险预警系统等。
-
-
Agent - G
-
原理:融合图结构数据(知识图谱等)与传统文本数据检索,利用图结构挖掘实体间复杂关系和语义信息,同时结合文本检索获取详细上下文。例如在智能问答中,先通过知识图谱确定概念关系,再检索相关文档补充具体内容。
-
应用场景:适用于需要深度语义理解和复杂关系推理的任务,如学术研究知识问答、历史文化知识溯源、生物医药知识推理等领域。
-
-
GeAR(Graph - based Agentic Retrieval,基于图的代理检索 )
-
原理:以图数据结构为基础,构建代理检索模型。通过对图中节点(实体)和边(关系)的分析处理,实现高效的信息检索和知识推理。例如在社交网络分析中,基于用户关系图检索特定用户群体或信息传播路径。
-
应用场景:适用于具有图结构数据特点的领域,如社交网络分析、生物基因关系研究、物流网络优化等场景。
-
-
Agentic Document Workflow(智能体文档工作流)
-
原理:围绕文档处理构建工作流,代理在文档的解析、检索、内容处理、格式转换、审批等环节发挥作用,实现文档处理的自动化和智能化。比如企业中合同文档从起草、审核到签署的流程,代理自动完成各项任务的衔接和处理。
-
应用场景:广泛应用于各类涉及大量文档处理的场景,如企业办公自动化、政府公文处理、法律文档管理等领域。
-
RAG 与 Fine-tuning的关系
RAG 与Fine-tuning 作为企业大模型落地的常用技术方案,各自具备独特优势,且相互补充,
-
互补关系:RAG 侧重外部知识动态检索,Fine-tuning 聚焦模型参数调整优化,二者结合可提升模型性能和实用性。在企业智能客服中,用 Fine-tuning 让模型熟悉企业业务术语和回复风格,用 RAG 检索最新产品知识和解决方案,为用户提供优质服务。
-
协同应用:先通过 Fine-tuning 让模型具备基础的特定领域能力,再借助 RAG 引入实时、动态知识,进一步增强模型表现。在医疗辅助诊断系统中,Fine-tuning 使模型掌握医学基础知识,RAG 检索最新医学研究成果和临床案例,辅助医生做出更准确诊断。
参考文献
[1] ZHAO P, ZHANG H, YU Q, 等. Retrieval-Augmented Generation for AI-Generated Content: A Survey[A/OL]. arXiv, 2024[2024-06-21]. http://arxiv.org/abs/2402.19473.
[2] GAO Y, XIONG Y, GAO X, 等. Retrieval-Augmented Generation for Large Language Models: A Survey[A/OL]. arXiv, 2024[2024-03-27]. http://arxiv.org/abs/2312.10997.(best)
[3] FAN W, DING Y, NING L, 等. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models[A/OL]. arXiv, 2024[2024-06-17]. http://arxiv.org/abs/2405.06211.
[4]LEWIS P, PEREZ E, PIKTUS A, 等. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks[A/OL]. arXiv, 2021[2025-01-27]. http://arxiv.org/abs/2005.11401. DOI:10.48550/arXiv.2005.11401.
[5] JIN J, ZHU Y, YANG X, 等. FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research[A/OL]. arXiv, 2024[2024-11-03]. http://arxiv.org/abs/2405.13576. DOI:10.48550/arXiv.2405.13576.
[6] SARMAH B, HALL B, RAO R, 等. HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction[A/OL]. arXiv, 2024[2024-08-24]. http://arxiv.org/abs/2408.04948. DOI:10.48550/arXiv.2408.04948.
[7] GAO Y, XIONG Y, WANG M, 等. Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks[A/OL]. arXiv, 2024[2024-08-24]. http://arxiv.org/abs/2407.21059. DOI:10.48550/arXiv.2407.21059.
[8] PENG B, ZHU Y, LIU Y, 等. Graph Retrieval-Augmented Generation: A Survey[A/OL]. arXiv, 2024[2024-08-21]. http://arxiv.org/abs/2408.08921.
[9] SINGH A, EHTESHAM A, KUMAR S, 等. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG[A/OL]. arXiv, 2025[2025-01-26]. http://arxiv.org/abs/2501.09136. DOI:10.48550/arXiv.2501.09136.
[10] SINGH A, EHTESHAM A, KUMAR S, 等. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG[A/OL]. arXiv, 2025[2025-01-26]. http://arxiv.org/abs/2501.09136. DOI:10.48550/arXiv.2501.09136.


















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











