







Leetcode部分散列表(哈希表)相关练习
一、散列表(哈希表)
1. 散列表(哈希表)的定义
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
2. 散列表和 LRU 缓存淘汰算法的实现
2.1 实现一个基于链表法解决冲突问题的散列表
class Dict:
def __init__(self, num):
self.__solts__ = []
self.num = num
for _ in range(num):
self.__solts__.append([])
def hash_fun(self,key,num):
hashval = 0
x = key
if x < 0:
print ("the key is low")
return
while x != 0:
hashval = (hashval << 3) + x%10
x /=10
return hashval % num
def put(self, key, value):
i = self.hash_fun(key,self.num) % self.num
for p, (k, v) in enumerate(self.__solts__[i]):
if k == key:
break
else:
self.__solts__[i].append((key, value))
return
self.__solts__[i][p] = (key, value)
def get(self, key):
i = self.hash_fun(key,self.num) % self.num
for k, v in self.__solts__[i]:
if k == key:
return v
raise KeyError(key)
# keys函数
def keys(self):
ret = []
for solt in self.__solts__:
for k, _ in solt:
ret.append(k)
return ret
def __getitem__(self,key):
return self.get(key)
def __setitem__(self,key,data):
self.put(key,data)
2.2 实现一个 LRU 缓存淘汰算法
2.2.1 LRU原理
LRU是一种缓存淘汰算法(在OS中也叫内存换页算法),由于缓存空间是有限的,所以要淘汰缓存中不常用的数据,留下常用的数据,达到缓存效率的最大化。LRU就是这样一种决定“淘汰谁留下谁”的算法,LRU是Least recently used的缩写,从字面意思“最近最少使用”,我们就可以理解LRU的淘汰规则。
2.2.2 LRU实现
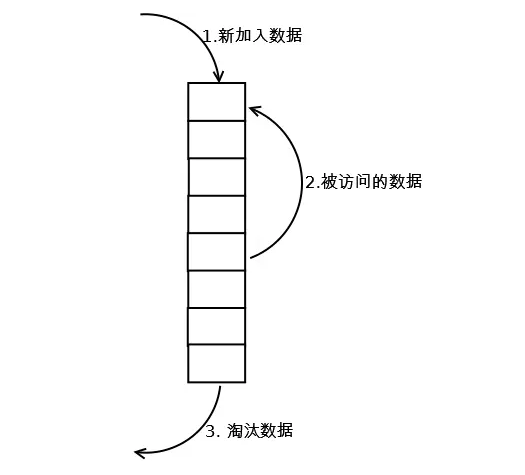
图中的缓存是一个列表结构,上面是头结点下面是尾节点,缓存容量为8(8个小格子):
- 有新数据(意味着数据之前没有被缓存过)时,加入到列表头
- 缓存到达最大容量时,需要淘汰数据多出来的数据,此时淘汰列表尾部的数据
- 当缓存中有数据被命中,则将数据移动到列表头部(相当于新加入缓存)
按上面的逻辑我们可以看到,一个数据如果经常被访问就会不断地被移动到列表头部,不会被淘汰出缓存,而越不经常访问的数据,越容易被挤出缓存。
8.2.3 用python实现LRU
按照前面的示意图,缓存内部我们只需要有一个列表(list)就可以实现LRU逻辑,不过用列表虽然能实现逻辑,但是在判断是否命中缓存时,速度可能非常慢(列表需要遍历才能知道数据有没有在里面)。在Python中,我们可以用基于hash的结构,比如字典(dict)或集合(set),来快速判断数据是否存在,解决列表实现的性能问题。但是字典和集合又是没有顺序的,如果能有一种既能排序,又是基于hash存储的数据结构,就好了。
在Python的collections包中,已经内置了这种实用的结构OrderedDict,OrderedDict是dict的子类,但是存储在内部的元素是有序的(列表的特点)。
class LRUcache:
def __init__(self, size=3):
self.cache = {}
self.keys = []
self.size = size
def get(self, key):
if key in self.cache:
self.keys.remove(key)
self.keys.insert(0, key)
return self.cache[key]
else:
return None
def set(self, key, value):
if key in self.cache:
self.keys.remove(key)
self.keys.insert(0, key)
self.cache[key] = value
elif len(self.keys) == self.size:
old = self.keys.pop()
self.cache.pop(old)
self.keys.insert(0, key)
self.cache[key] = value
else:
self.keys.insert(0, key)
self.cache[key] = value
if __name__ == '__main__':
test = LRUcache()
test.set('a',2)
test.set('b',2)
test.set('c',2)
test.set('d',2)
test.set('e',2)
test.set('f',2)
print(test.get('c')) # None
print(test.get('b')) # None
print(test.get('a')) # None
print(test.get('e')) # 2















 5408
5408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









