







前言
上一篇博客把Faster-RCNN的关键技术说了一下,但是流程梳理那部分我觉得写得不妥当,所以单独写一篇梳理整个网络的工作流程再挖一下网络细节。
Faster-RCNN组成
以训练阶段为例,我把整个网络结构模块化为包括输入、数据预处理、backbone提取特征、RPN、Fast-RCNN、输出这五大部分。
1.输入样本并数据预处理
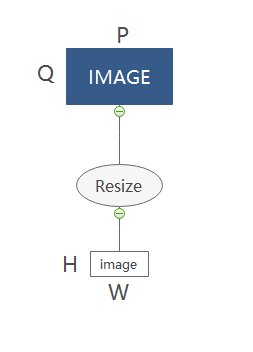
首先,假设样本图片IMAGE,尺寸大小Q×P,将其输入Faster-RCNN网络:

resize操作,处理图片的尺寸到H×W,适应模型要求:
2.backone提取特征
对图片做卷积操作提取特征,backbone以VGG16为例:

3.RPN生成候选框
分别经过两个1×1卷积组成的分类分支和回归分支,得到分类和回归特征图,通过特征映射得到region proposal后与真实标签计算LOSS学习参数。

得到初步的region proposa(黄色箭头),但是我们需要进行筛选,先通过与标签GT计算IOU阈值筛选掉得分低的(蓝色箭头),然后再进行NMS删除冗余的候选框(绿色箭头)

4.Fast-RCNN
对提取的候选框归一化尺寸,用ROI Pooling。然后送入模型训练

5.输出分类和回归pred

如果不想仅局限在2分类上,用[x,y,w,h,C]表示,C表示的是类别个数,具体问题就会有具体的值,比如如果是5分类,最后的向量形式为[x,y,w,h,class1,class2,class3,class4,class5]。
总结

补充:训练方式,分步训练
整个网络中一共有三个地方需要训练网络参数,一个是2backbone,一个是3RPN,一个是5Fast-RCNN中的backbo

用alternative traini的方式进行训练:
首先,2中的backbone直接使用imagenet上预训练的模型;
然后训练RPN的参数,其他两个网络不进行训练;
得到RPN的参数后训练fast-RCNN,其他两个网络同样不进行训练;
训练完fast-RCNN后可能效果不理想,基于这个参数再重训训练一次RPN;
再重新训练fast-RCNN。
大概就是这个训练步骤。














 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









