







一、下载数据集
train文件夹中有62个文件夹,每个文件夹中是一类标志,每个文件夹的数量不一,有多又少,所以存在样本不均衡问题。
二、样本标签转换
打开train_label文件夹,发现有62类标签,对于62个类别,如果用标量表示会引入很大的数量等级差距,所以考虑采用独热编码对类别标签编码成向量形式。

1.数据预处理:利用python sklearn 将类别数据转换成one-hot数据
import pandas as pd
#类别数据转换成one-hot
# 1. 读取csv文件
train_labels = pd.read_csv('C:/Users/WJL/Desktop/开课吧人工智能核心/项目—交通标识识别/traffic-sign/train_label.csv')
#打印部分内容观察一下
print(train_labels.head())
解析:Pandas里面的head( )函数只能读取前五行数据,因为默认的参数size大小是5,所以会返回5个数据
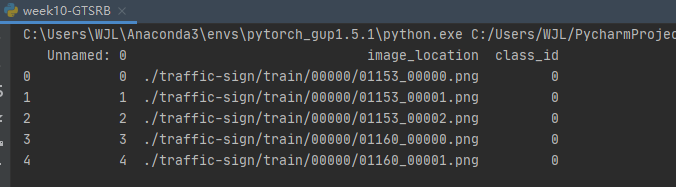
在最后一列class_id发现类别数据符合数值类,所以无需考虑转换成数值这一步操作。(补充需要数值化的接口from sklearn.preprocessing import LabelEncoder)
from sklearn.preprocessing import OneHotEncoder
# 2.one-hot
enc = OneHotEncoder()
class_onehot = enc.fit_transform(train_labels)
class_onehot = class_onehot.toarray()
print(class_onehot)
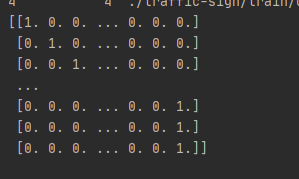
# 3.转换后的标签和CSV中其他数据组合在一起
train_labels = pd.concat([train_labels,pd.DataFrame(class_onehot)],axis=1)
train_labels = train_labels.drop(['class_id'],axis=1)
print(train_labels.head())
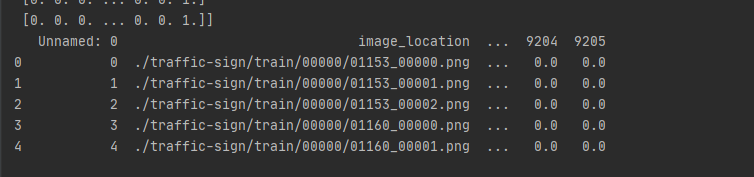
感觉不太对……所以第三步注释掉了没继续用
参考
2.读取数据预处理:利用torch.utils.data中的Dataloader
import torch
import torchvision # 提供常见的数据集
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms,models
from torch.utils.data import DataLoader,Dataset
from torchvision.datasets import ImageFolder
# 图像预处理
my_transform = torchvision.transforms.Compose([
transforms.Resize((64,64)), # 通常先resize到固定大小
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5]), #再做归一化,如果是三通道,就有三个mean和三个std,对应位置R-mean再除std,G,B位置像素同理
# transforms.RandomHorizontalFlip(p=0.8),#默认等概率翻转 不写参数p就是默认概率0.5
transforms.ToTensor() #转成pytorch支持的格式,一般都要加这一步
]) # compose方法用于集成 改数据集中的transform为自己定义的方法
ImageFolder用于读取数据,参数为数据集地址
train_datasets = ImageFolder('C:/Users/WJL/Desktop/开课吧人工智能核心/项目—交通标识识别/traffic-sign/train',transform=my_transform)
test_datasets = ImageFolder('C:/Users/WJL/Desktop/开课吧人工智能核心/项目—交通标识识别/traffic-sign/test',transform=my_transform)
BATCH_SIZE=128
#书写dataloader
train_dataloader = DataLoader(dataset=train_datasets,
batch_size=BATCH_SIZE,
shuffle=True, #乱序
)
test_dataloader = DataLoader(dataset=test_datasets,
batch_size = BATCH_SIZE,
)
3.搭建模型:使用torchvision提供好的预训练模型
my_model = torchvision.models.vgg16(pretrained=True) # 参数代表下载训练好的模型
print(my_model) # 看模型结构,一部分feature,一部分classif,前半部分是backbone最好不要修改,后部分可更改


# 由于模型是预训练好的,又希望不更改前半部分,更改后半部分进行训练,可以通过以下方式进行迁移训练
print(my_model.parameters()) # 查看权重,发现默认都有requires grad
for param in my_model.parameters(): # 将其更改为默认不进行梯度更新,再训练就会保存预训练模型部分的权重了
param.requires_grad = False
# 上面的方法冻结了所有的参数更新,我们希望冻结feature部分,更新class部分。需要更新的参数进行如下操作:
my_model.classifier[3].requires_grad = True #分类器的第三层恢复更新
my_model.classifier[6] = nn.Linear(in_features=4096,out_features=NUM_CLASSES,bias=True) #更改最后一层的分类类别
print(my_model) #看更改后的模型结构

4.训练模型
#训练模型
#训练器 (优化器)
optimizer = torch.optim.Adam(params=my_model.parameters(),lr=LEARNING_RATE,momentum = MOMENTUM)
my_model = my_model.to(DEVICE)
for epoch in range(NUM_EPOCHES):
my_model.train() #模型切换到train状态,用于识别dropout是否生效
for batch_index,data in enumerate(train_dataloader):#每批次训练的数据从dataloader加载
images,labels = data #50000张图片128batch大概390个index,data由图片和标签组成
images= images.to(DEVICE) #放入GPU
labels = labels.to(DEVICE)
##forward:图片作为输出传入模型,模型预测输出,交叉熵计算预测和标签的损失
logits = my_model(images)
loss = F.cross_entropy(logits,labels)
## backward
optimizer.zero_grad()#梯度清空:每个batch不同的样本得到一批梯度,这批梯度用于更新,下一批batch的样本重新计算一个新的梯度,不基于历史梯度,没有参考价值
loss.backward() #梯度回传(更新),该函数用于计算梯度
optimizer.step() #根据梯度更新网络参数
## Print sth.
if batch_index % 50 == 0:
print(f'Epoch: {epoch + 1}, Batch ID: {batch_index}/{len(train_dataloader)},loss:{loss}')
报错:TypeError: img should be PIL Image. Got <class ‘torch.Tensor‘>
解决方法
修改transform部分:
# 图像预处理
my_transform = torchvision.transforms.Compose([
transforms.Resize((64,64)), # 通常先resize到固定大小
transforms.RandomHorizontalFlip(p=0.8),#默认等概率翻转 不写参数p就是默认概率0.5
transforms.ToTensor(),#转成pytorch支持的格式,一般都要加这一步
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
# 再做归一化,如果是三通道,就有三个mean和三个std,对应位置R-mean再除std,G,B位置像素同理
]) # compose方法用于集成 改数据集中的transform为自己定义的方法
重新运行
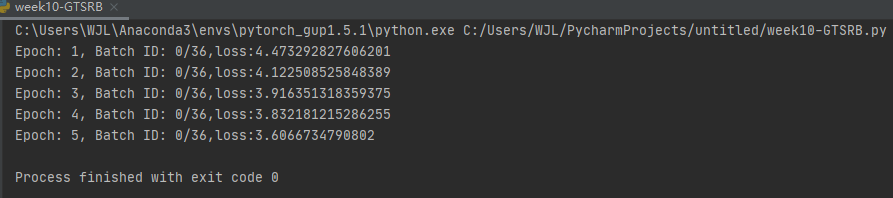
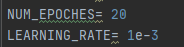
修改了一下epoch和lr
NUM_EPOCHES= 50
LEARNING_RATE= 1e-2
loss中间降了最后又升上去了然后反复升降。查询资料

继续调参

到了epoch16又上去了

只写到具体的搭建思路吧,苦兮兮的去调参了。















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









