







参考地址:https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.multivariate_normal.html
scipy.stats.multivariate_normal
| Parameters: | x : array_like
mean : array_like, optional
cov : array_like, optional
Alternatively, the object may be called (as a function) to fix the mean and covariance parameters, returning a “frozen” multivariate normal random variable: rv = multivariate_normal(mean=None, scale=1)
|
|---|
The probability density function for multivariate_normal is
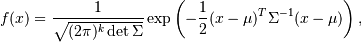
where 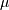 is the mean,
is the mean, 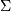 the covariance matrix, and
the covariance matrix, and 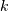 is the dimension of the space where
is the dimension of the space where  takes values.
takes values.
举例:
from scipy.stats import multivariate_normal
import numpy as np
import matplotlib.pyplot as pltx = np.linspace(0, 5, 10, endpoint=False)
x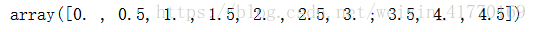
y = multivariate_normal.pdf(x, mean=2.5, cov=0.5); y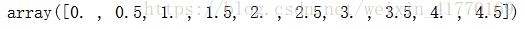
plt.plot(x, y)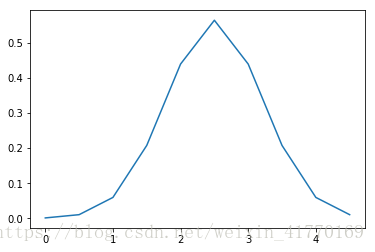















 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









