









文章链接
文章方法为无监督跨数据集行人重识别(Unsupervised Cross-Domain Person Re-Identification)方法中的一种——利用GAN网络将源数据集图像转变为目标数据集图像的风格样式。
下面简单叙述一下文章的思路:
文章提出的网络框图如下所示:

大致流程:给定source图像Xs、target图像Xt,利用target背景mask来提取target图像Xt中的背景,并输入绿色的卷积网络中进行context的特征提取;同理,将Xs输入到黄色的网络中今天identity的特征提取,再利用fusion进行特征融合,输入到灰色的网络U-Net中去,输出新生成的图像XR以及Xs的人物mask Xc,再利用Xc分别提取Xs的行人信息与XR图像中的背景信息,从而得到输出XG,XG的表达式如下所示:
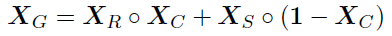
其中,○表示哈达玛积

即简单通俗地讲就是,将source的图像Xs的前景信息——行人,与target图像Xt的背景信息想结合,生成一个拥有source行人+target背景的新图像,从而实现风格转移,同时扩充模型训练的数据集。
其中上述涉及的mask,是利用LIP-JPPNet得到person mask,从而过滤掉Xt中的行人信息,有兴趣的可以了解一下:LIP-JPPNet
涉及到的loss
文章涉及到四个loss,分别为:Adversarial Loss,Camera Loss,Context Loss,Identity Loss。
Adversarial Loss:
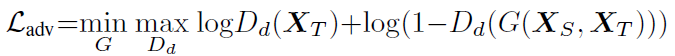

上述损失函数为GAN网络的损失函数,简单地理解为对判别器Dd以及生成器G分别进行优化,迭代交替进行。
首先对判别器Dd进行优化:
其中Dd(Xt)表示对真实的样本进行判别,这里,我们希望它的判别结果越接近于1越好,所以损失函数为log(Dd(x)),G(Xs,Xt)表示生成的样本,对于生成的样本,我们希望判别器的判别结果Dd(G(Xs,Xt))越接近于0越好,所以损失函数为log(1-Dd(G(Xs,Xt))),因为希望判别器能区分真实图片与生成图片,所以需要loss总数值最大。
在完成对判别模型的优化之后,便是对生成模型进行优化,在这里,生成模型的优化很简单,只需要让判别的结果Dd(G(Xs,Xt)))接近于1就可以了。因为希望能让判别器无法区分原始图像与生成的图像,所以让loss总数值最小。
Camera Loss:
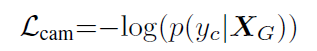

这个loss比较简单好理解,camera的id为yc,当yc与Xg对应上的概率为1时,Lcam为0,且概率越高,Lcam越小。
Identity Loss:
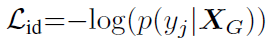

同理于Lcam,行人id为yj,当yc与Xg对应上的概率为1时,Lid为0,且概率越高,Lid越小。
Context Loss:
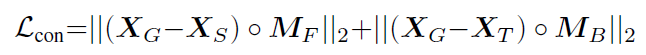

生成的图像XG中的前景(人物)以及背景分别越接近Xs、Xr,Lcon越小
Final Loss:
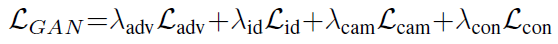
最终的损失函数为四个loss的乘以权重相加,如上式所示。
效果展示

(a)为baseline的效果,可以发现效果不怎么好,(b)为这篇文章的最终效果图,可以发现效果相当不错。
完。
(个人理解,仅供参考)















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









