






1. 自适应优化方法的显著特征
您知道并非所有馈入神经网络的特征值都会对最终结果产生相同的影响。 一些参数可能会包含很多噪声,且比其他变化更频繁,振幅也有所不同。 其他参数的样本可能包含稀有值,当采用固定学习速率训练神经网络时,这些稀有值可能不会被注意到。 之前研究过的随机梯度下降方法的缺点之一是在此类样本上无法使用优化机制。 结果就是,学习过程可能在局部最小值处停止。 可采用自适应方法训练神经网络来解决该问题。 这些方法能够在神经网络训练过程中动态改变学习率。 这样的方法及其变体有很多数量。 我们来研究其中最受欢迎的。
1.1. 自适应梯度方法(AdaGrad)
自适应梯度法于 2011 年提出。 它是随机梯度下降法的一种变体。 经由比较这些方法的数学公式,我们轻易注意到一个不同之处:对于所有之前的训练迭代,AdaGrad 的学习率除以梯度平方和的平方根。 这种方式可降低频繁更新参数的学习率。
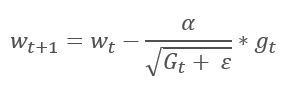
编辑
添加图片注释,不超过 140 字(可选)
而该方法的主要缺点来自其公式:梯度的平方和只能增长,因此学习率趋于 0。 这最终会导致训练停止。
利用这种方法需要额外的计算和内存分配,以便保存每个神经元的梯度平方和。
1.2. RMSProp 方法
AdaGrad 方法的逻辑延续自 RMSProp 方法。 为了避免学习率跌落到 0,在更新权重的公式分母中,已用梯度平方的指数均值替换过去的梯度平方和。 这种方法消除了分母中数值的恒定无限增长。 甚而,它更加关注表征模型当前状态的最新梯度值。
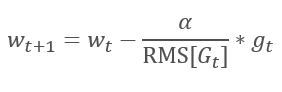
编辑
添加图片注释,不超过 140 字(可选)
1.3. Adadelta 方法
Adadelta 自适应方法几乎与 RMSProp 同时提出。 此方法类似,它在更新权重的公式分母中采用了平方梯度总和的指数均值。 但与 RMSProp 不同,此方法彻底拒绝更新公式中的学习率,并在所分析参数中用之前修改的平方和的指数均值来替代。
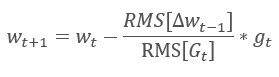
编辑
添加图片注释,不超过 140 字(可选)
这种方式能够从更新权重的公式中删除学习率,并创建高度自适应的学习算法。 然而,此方法需要额外的计算迭代,并为存储每个神经元的额外值而分配内存。
1.4. 自适应动量评估方法(亚当)
2014 年,Diederik P.Kingma 和 Jimmy Lei Ba 提出了自适应动量评估方法(Adam)。 根据作者的说法,该方法结合了 AdaGrad 和 RMSProp 方法的优点,非常适合在线训练。 该方法在不同样本上始终展现出良好的结果。 在各种软件包中,通常建议按照默认使用它。
该方法基于计算出的梯度 m 的指数平均值,和平方梯度 v 的指数平均值。 每个指数平均值都有其自己的超参数 ß,由它判定平均周期。
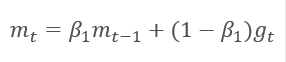
编辑
添加图片注释,不超过 140 字(可选)
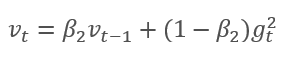
编辑
添加图片注释,不超过 140 字(可选)
作者建议默认采用 ß1 0.9 和 ß2 0.999。 在此情况下,m0 和 v0 取零值。 采用这些参数,上面介绍的公式在训练开始时返回值接近 0,因此开始时的学习率会很低。 为了加快学习过程,作者建议修改所获得的动量。
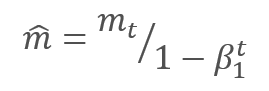
编辑
添加图片注释,不超过 140 字(可选)
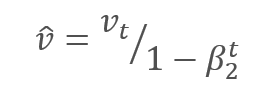
编辑
添加图片注释,不超过 140 字(可选)
通过调整校正梯度动量 m 与平方梯度 v 的校正动量的平方根之间的比率来更新参数。 为避免除零,在分母里加入接近 0 的常数 Ɛ。 依据学习因子 α 调整所得比率,学习因子 α 在这种情况下是学习步幅的上限。 作者建议默认采用 α 0.001。
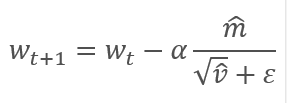
编辑
添加图片注释,不超过 140 字(可选)
2. 实现
研究过理论方面之后,我们便可以进行实际实现了。 我建议采用作者提供的默认超参数来实现 Adam 方法。 进而,您可以尝试其他超参数变体。
早前建立的神经网络采用随机梯度下降法进行训练,为此我们已经实现了反向传播算法。 现有的反向传播功能可用来实现 Adam 方法。 我们只需要实现权重更新算法。 这个功能需经由 updateInputWeights 方法,它是在每个神经元类里实现的。 当然,我们不会删除之前创建的随机梯度下降算法。 我们来创建一个替代算法,令您可以选择要采用的训练方法。
2.1. 构建 OpenCL 内核
研究 CNeuronBaseOCL 类的 Adam 方法实现。 首先,创建 UpdateWeightsAdam 内核实现 OpenCL 方法。 指向以下矩阵的指针则会通过参数传递给内核:
-
权重矩阵 — matrix_w,
-
误差梯度矩阵 — matrix_g,
-
输入数据矩阵 — matrix_i,
-
梯度指数均值矩阵 — matrix_m,
-
平方梯度的指数均值矩阵 — matrix_v.
__kernel void UpdateWeightsAdam(__global double *matrix_w, __global double *matrix_g, __global double *matrix_i, __global double *matrix_m, __global double *matrix_v, int inputs, double l, double b1, double b2)
另外,在内核参数中,传递输入数据数组的大小和 Adam 算法的超参数。
在内核伊始,获取在两维的流序列号,其分别指示当前层和先前层的神经元数量。 使用接收到的编号,判断缓冲区中已处理元素的初始编号。 请注意,第二维中的结果流编号应乘以 “4”。 这是因为为了减少流数量和程序执行的总时间,我们将利用含有 4 个元素的向量计算。
{ int i=get_global_id(0); int j=get_global_id(1); int wi=i*(inputs+1)+j*4;
判断已处理元素在数据缓冲区中的位置后,声明矢量变量,并用相应的数值填充它们。 利用先前讲述的方法,并在向量中将缺失数据填充零值。
double4 m, v, weight, inp; switch(inputs-j*4) { case 0: inp=(double4)(1,0,0,0); weight=(double4)(matrix_w[wi],0,0,0); m=(double4)(matrix_m[wi],0,0,0); v=(double4)(matrix_v[wi],0,0,0); break; case 1: inp=(double4)(matrix_i[j],1,0,0); weight=(double4)(matrix_w[wi],matrix_w[wi+1],0,0); m=(double4)(matrix_m[wi],matrix_m[wi+1],0,0); v=(double4)(matrix_v[wi],matrix_v[wi+1],0,0); break; case 2: inp=(double4)(matrix_i[j],matrix_i[j+1],1,0); weight=(double4)(matrix_w[wi],matrix_w[wi+1],matrix_w[wi+2],0); m=(double4)(matrix_m[wi],matrix_m[wi+1],matrix_m[wi+2],0); v=(double4)(matrix_v[wi],matrix_v[wi+1],matrix_v[wi+2],0); break; case 3: inp=(double4)(matrix_i[j],matrix_i[j+1],matrix_i[j+2],1); weight=(double4)(matrix_w[wi],matrix_w[wi+1],matrix_w[wi+2],matrix_w[wi+3]); m=(double4)(matrix_m[wi],matrix_m[wi+1],matrix_m[wi+2],matrix_m[wi+3]); v=(double4)(matrix_v[wi],matrix_v[wi+1],matrix_v[wi+2],matrix_v[wi+3]); break; default: inp=(double4)(matrix_i[j],matrix_i[j+1],matrix_i[j+2],matrix_i[j+3]); weight=(double4)(matrix_w[wi],matrix_w[wi+1],matrix_w[wi+2],matrix_w[wi+3]); m=(double4)(matrix_m[wi],matrix_m[wi+1],matrix_m[wi+2],matrix_m[wi+3]); v=(double4)(matrix_v[wi],matrix_v[wi+1],matrix_v[wi+2],matrix_v[wi+3]); break; }
梯度向量是通过将当前神经元的梯度乘以输入数据向量而获得的。
double4 g=matrix_g[i]*inp;
接下来,计算梯度和平方梯度的指数平均值。
double4 mt=b1*m+(1-b1)*g; double4 vt=b2*v+(1-b2)*pow(g,2)+0.00000001;
计算参数变化增量。
double4 delta=l*mt/sqrt(vt);
请注意,我们尚未调整内核中的接收动量。 在此有意省略了此步骤。 因为 ß1和 ß2 对于所有神经元和 t 都是相同的,其在这里是 神经元参数更新的迭代次数,对于所有神经元也相同,然后对于所有神经元校正因子也将相同。 这就是为什么我们不会重新计算每个神经元的因子,而是在主程序代码中对其进行一次性计算,并将其传递给内核,以便依据该值调整后续的学习系数的原因。
在增量计算完成之后,我们只需要调整权重系数,并更新缓冲区中已计算的动量即可。 然后退出内核。
switch(inputs-j*4) { case 2: matrix_w[wi+2]+=delta.s2; matrix_m[wi+2]=mt.s2; matrix_v[wi+2]=vt.s2; case 1: matrix_w[wi+1]+=delta.s1; matrix_m[wi+1]=mt.s1; matrix_v[wi+1]=vt.s1; case 0: matrix_w[wi]+=delta.s0; matrix_m[wi]=mt.s0; matrix_v[wi]=vt.s0; break; default: matrix_w[wi]+=delta.s0; matrix_m[wi]=mt.s0; matrix_v[wi]=vt.s0; matrix_w[wi+1]+=delta.s1; matrix_m[wi+1]=mt.s1; matrix_v[wi+1]=vt.s1; matrix_w[wi+2]+=delta.s2; matrix_m[wi+2]=mt.s2; matrix_v[wi+2]=vt.s2; matrix_w[wi+3]+=delta.s3; matrix_m[wi+3]=mt.s3; matrix_v[wi+3]=vt.s3; break; } };
此代码还有另一个技巧。 请注意 switch 运算符中 case 情况的相反顺序。 此外, break 操作符仅在 case 0 和 default 情况之后使用。 这种方式可避免所有变体重复相同的代码。
2.2. 修改主程序里的神经元类代码
构建内核之后,我们需要对主程序代码进行修改。 首先,在 “define” 模块里添加操控内核的常量。
#define def_k_UpdateWeightsAdam 4 #define def_k_uwa_matrix_w 0 #define def_k_uwa_matrix_g 1 #define def_k_uwa_matrix_i 2 #define def_k_uwa_matrix_m 3 #define def_k_uwa_matrix_v 4 #define def_k_uwa_inputs 5 #define def_k_uwa_l 6 #define def_k_uwa_b1 7 #define def_k_uwa_b2 8
创建指示训练方法的枚举,并在枚举中添加动量缓冲区。
enum ENUM_OPTIMIZATION { SGD, ADAM }; //--- enum ENUM_BUFFERS { WEIGHTS, DELTA_WEIGHTS, OUTPUT, GRADIENT, FIRST_MOMENTUM, SECOND_MOMENTUM };
然后,在 CNeuronBaseOCL 类主体中,添加缓冲区,用来存储动量、指数平均常数、训练迭代计数器,以及保存训练方法的变量。
class CNeuronBaseOCL : public CObject { protected: ......... ......... .......... CBufferDouble *FirstMomentum; CBufferDouble *SecondMomentum; //--- ......... ......... const double b1; const double b2; int t; //--- ......... ......... ENUM_OPTIMIZATION optimization;
在类构造函数中,设置常量的值,并初始化缓冲区。
CNeuronBaseOCL::CNeuronBaseOCL(void) : alpha(momentum), activation(TANH), optimization(SGD), b1(0.9), b2(0.999), t(1) { OpenCL=NULL; Output=new CBufferDouble(); PrevOutput=new CBufferDouble(); Weights=new CBufferDouble(); DeltaWeights=new CBufferDouble(); Gradient=new CBufferDouble(); FirstMomentum=new CBufferDouble(); SecondMomentum=new CBufferDouble(); }
不要忘记在类的析构函数中加入删除缓冲区对象的代码。
CNeuronBaseOCL::~CNeuronBaseOCL(void) { if(CheckPointer(Output)!=POINTER_INVALID) delete Output; if(CheckPointer(PrevOutput)!=POINTER_INVALID) delete PrevOutput; if(CheckPointer(Weights)!=POINTER_INVALID) delete Weights; if(CheckPointer(DeltaWeights)!=POINTER_INVALID) delete DeltaWeights; if(CheckPointer(Gradient)!=POINTER_INVALID) delete Gradient; if(CheckPointer(FirstMomentum)!=POINTER_INVALID) delete FirstMomentum; if(CheckPointer(SecondMomentum)!=POINTER_INVALID) delete SecondMomentum; OpenCL=NULL; }
在类初始化函数的参数中,添加训练方法,并根据指定的训练方法来初始化缓冲区。 如果采用随机梯度下降法进行训练,初始化增量缓冲区,并删除动量缓冲区。 如果采用 Adam 方法,初始化动量缓冲区,并删除增量缓冲区。















 2399
2399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









