







win10+ollama+minicpm-v2.6进行多模态大模型调用测试记录
前言
本次记录在win10系统下,使用ollama和minicpm-v2.6,进行图像分析。即输入一张图像给多模态大模型分析图像中的信息。
一、安装ollama
1.下载安装包
进入ollama官网,下载对应系统版本就行。官网链接
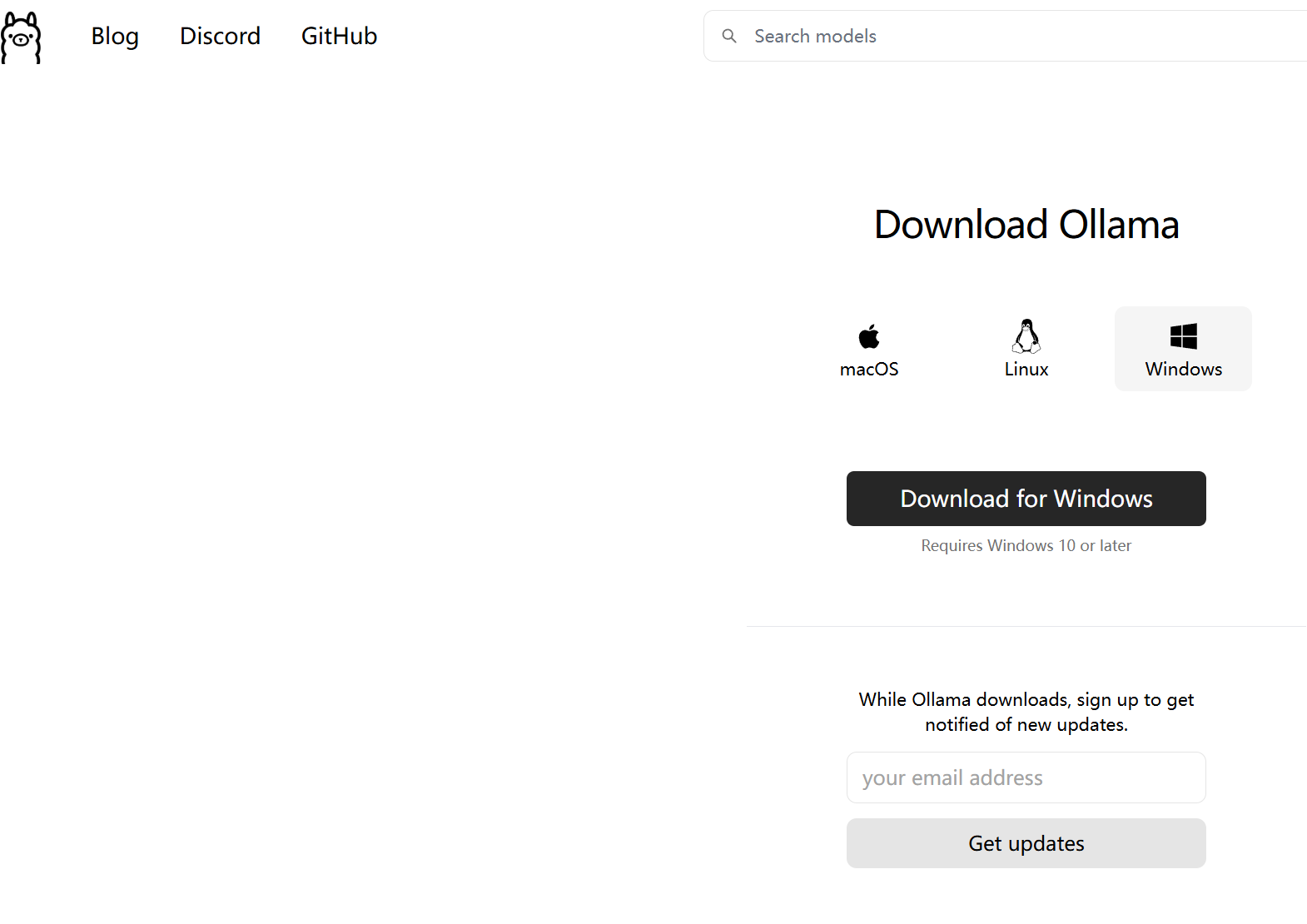
2.安装
安装时不能选择安装路径,默认直接安装到C盘。但是我们可以修改模型下载路径。
安装结束后,打开cmd终端,输入:
ollama list
出现列表就表示安装成功

修改模型存储路径,由于大模型的模型文件都比较大,直接存到默认路径(C:\Users\用户名.ollama)下的话,很容易撑爆C盘。修改步骤如下
1)在系统变量里面新建一个名字为“OLLAMA_MODELS”的变量。
2)变量值中写入你想保存模型的路径
3)重启电脑
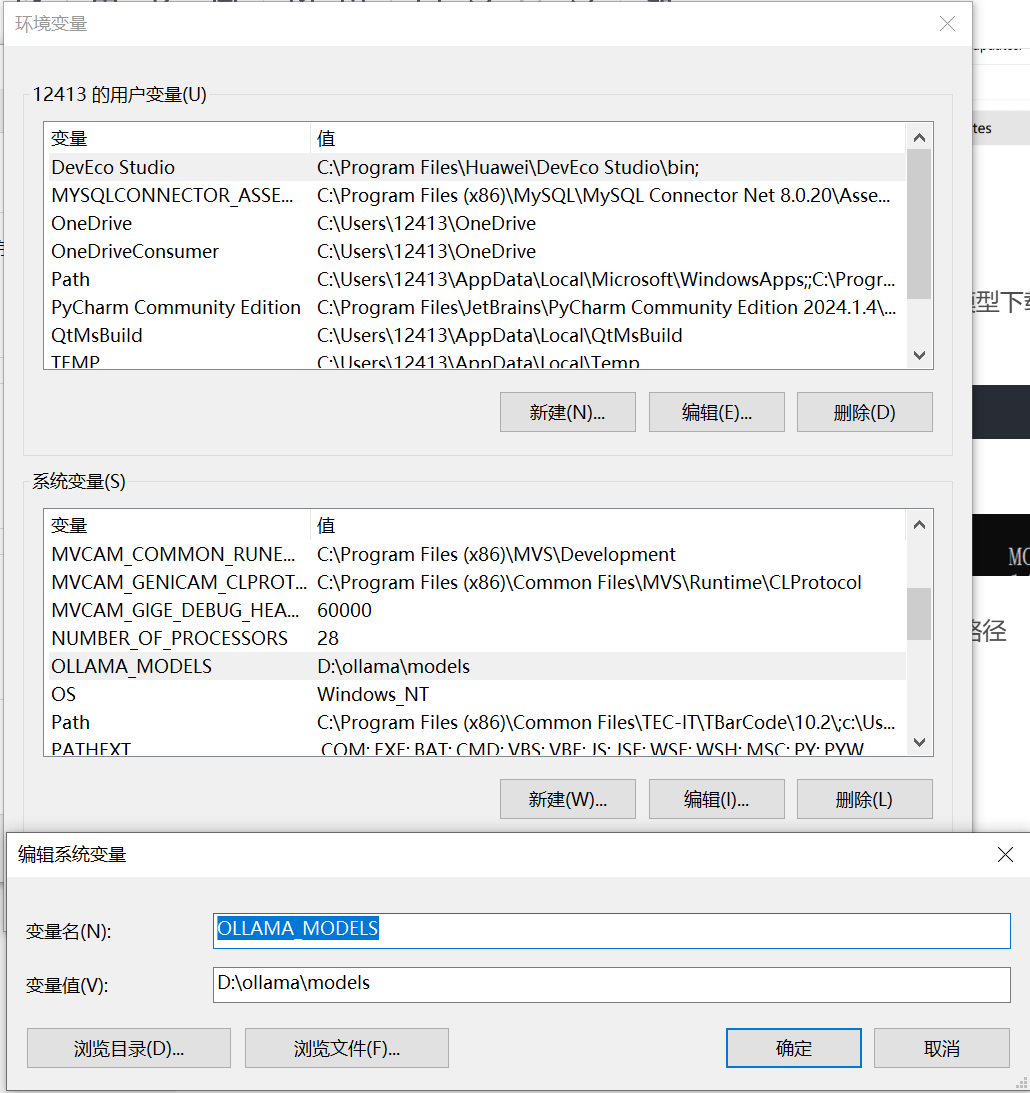
二、下载模型文件
同样是进入ollama官网。选择你需要的模型
本次使用minicpm-v2.6:Q4_K_M模型,复制指令,到终端运行,进行模型下载。
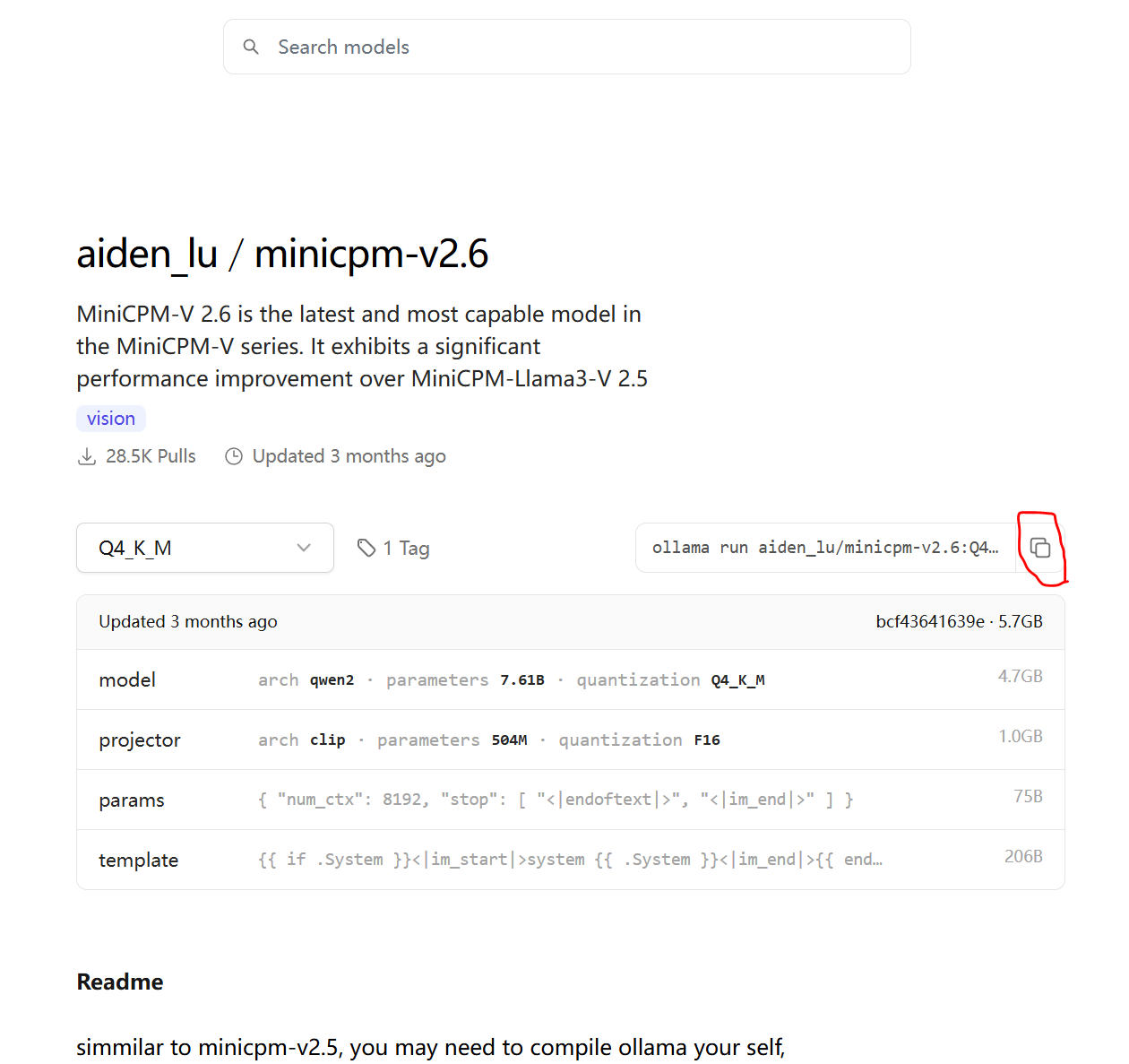
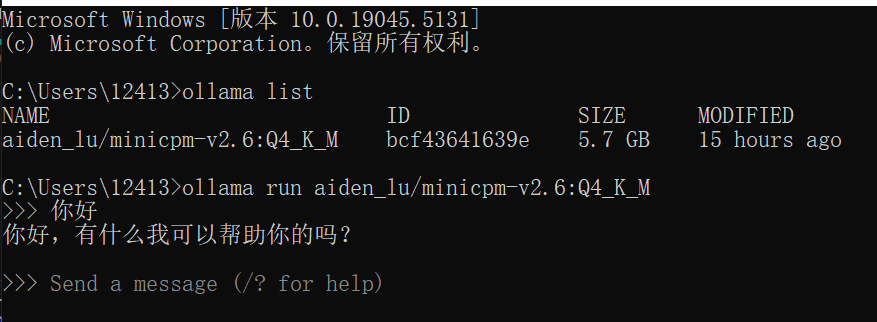
下载结束后试运行一下,运行指令
ollama run aiden_lu/minicpm-v2.6:Q4_K_M
三、代码调用
1.pip安装ollama
先使用pip安装ollama,输入指令
pip install ollama
2.测试代码
测试代码如下
import ollama
response = ollama.chat(
model = "aiden_lu/minicpm-v2.6:Q4_K_M",
messages = [{
'role':'user',
'content':'请使用中文回答,图片中是什么东西?',
'images':['1.jpg']
}]
)
print(response['message']['content'])
增加耗时计算
import ollama
import time
start_time = time.time() # 记录开始时间
response = ollama.chat(
model = "aiden_lu/minicpm-v2.6:Q4_K_M",
messages = [{
'role':'user',
'content':'请使用中文回答,图片中是什么东西?',
'images':['1.jpg']
}]
)
print(response['message']['content'])
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算耗时
print(f"{elapsed_time:.4f} 秒")
图片请替换成你自己想测试的。我使用的图片如下

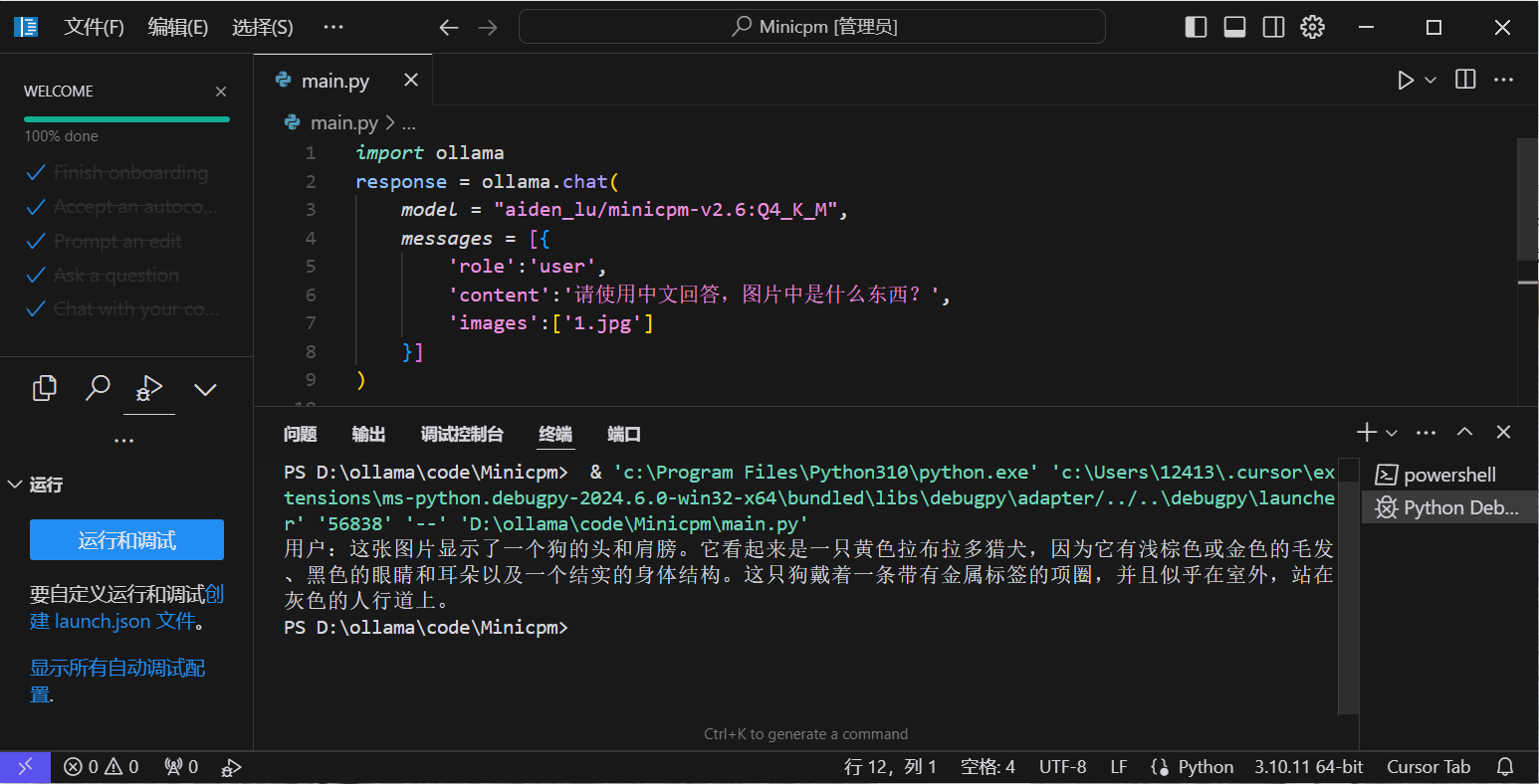
3.运行结果
测试结果如下,模型还是较为准确的输出了对该图像的分析结果。


















 7578
7578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











