







人脑通过神经激活模式编码信息。虽然分析神经数据的常规方法侧重对大脑(去)激活状态的分析,但是多元神经模式相似性有助于分析神经活动所代表的信息内容。在成年人中,已经确定了许多与表征认知相关的特征,尤其是神经模式的稳定性、独特性和特异性。然而,尽管随着儿童时期认知能力的增长,表征质量也逐步提高,但是发育研究领域特别是在脑电图(EEG)研究中仍然很少使用基于信息的模式相似性方法。在这里,我们提供了一个全面的方法介绍和逐步教程——频谱脑电图数据的模式相似性分析,包括一个公开可用的资源和样本数据集的儿童和成人的数据。
1.介绍
认知神经科学中的一个关键概念是神经表征。它假设信息是由神经活动表示的。其主要目标是了解信息在大脑中是如何表征的,以及神经表征的质量如何影响认知。迄今为止,发育研究很少通过神经表征的视角来研究认知。接下来,我们将以情景记忆表现为例,介绍当前如何研究神经表征并描述它们在认知中的作用的方法。我们提出了发展认知神经科学表征的观点,并提供了一个循序渐进的教程,详细介绍了对时频分辨脑电图数据进行多元神经模式相似性分析的所有必要步骤。
在实践中,神经表征被测量为神经活动模式,用于研究神经表征以及影响信息是否以及如何成功编码到神经活动的因素。神经活动的模式可以通过表征相似性分析(representational similarity analysis, RSA)来确定活动模式的相关性来量化多维空间中神经表示之间的距离,例如,通过关联重复给定刺激所诱发的神经活动模式,可以评估刺激表征随时间的稳定性,即自相似性。不同刺激的响应活动模式之间的相关性可以被视为跨神经表征相似性的衡量标准。例如,相似内容的表征(如不同的脸刺激)彼此之间的相似性更强,相对不同内容的表征(如脸和房子),会表现出更高的相关性。总的来说,RSA是一个通用的工具来研究塑造认知的神经表征属性。
脑磁图和脑电图(M/EEG)高时间分辨率使人们能够检查刺激呈现试验中不同时间点的神经模式的相似性,从而确定特定信息在大脑中呈现的时间和持续时间。虽然RSA越来越多地应用于脑电图数据,但迄今为止的大多数研究都使用它来比较时空活动模式(例如,来自事件相关电位),即跨刺激呈现时间和电极的激活幅度。鉴于在大范围频率范围内的节律性神经活动对认知过程具有重要意义,我们在这里通过实现一种计算儿童和成人时频表征(TFRs)相似性的例子,扩展了之前的脑电图模式相似性方法。
接下来,我们将提供一个全面的指南,通过时间分辨谱模式相似性分析的步骤来计算(并绘制)来自TFRs的神经表征的稳定性和独特性,并使用FieldTrip实现的基于聚类的排列分析对其进行统计比较,以及与记忆性能的关联。MATLAB代码是公开可访问和可执行的,其附带的脑电图样本数据集来自参加记忆研究的10名儿童和10名年轻人(Sommer et at.,2021;图1)。
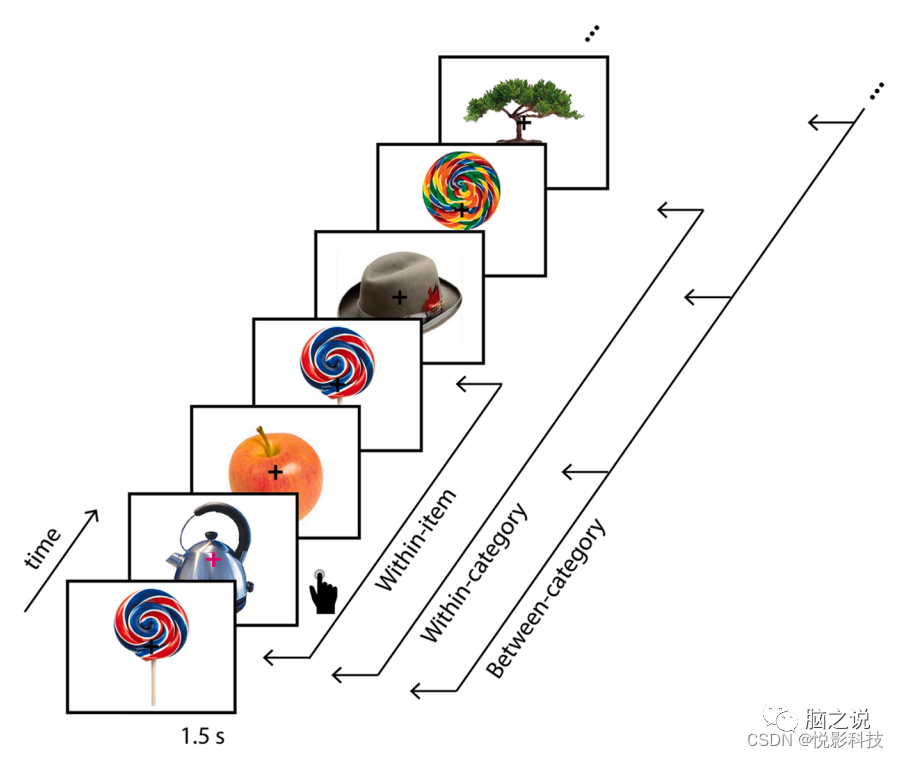
图1 记忆任务范式的编码阶段(Sommer et al.,2021)和表征相似性水平。在编码任务中,对象按顺序呈现,并且每当固定交叉改变颜色时,参与者就被要求按下按钮。示例数据集包含对来自每个对象类别的两个示例的两次重复的试验。项目内相似性是通过看到相同的对象而引发的神经模式的相似性。类别内的相似性是由来自同一对象类别的不同示例引起的神经模式的相似性。类别间相似性是由所有不同对象类别引起的神经模式的平均成对相似性。类别内和类别之间的相似性也称为项目之间的相似性。
2.频谱EEG数据的表征相似性分析
2.1 概述
在示例性的数据分析流程中,我们演示了如何评估跨刺激重复的表征(项目内模式相似性)的神经稳定性,以及对不同刺激的响应(项目间模式相似性)的神经特异性。此外,我们通过对比项目内相似性和项目间相似性来检查神经表征是否具有特定的性质。
该教程附带了一个样本数据集,包括儿童和成人的脑电图数据(Sommer et al.,2021)以及与开源FieldTrip工具箱相接口的自定义编写的MATLAB代码。本教程已在MATLAB R2016b, R2019b, R2020b和FieldTrip-20180709和FieldTrip-20210507(https://www.fieldt riptoolbox.org/download/)上测试,不需要高性能计算能力。除了输入数据之外,我们还提供所有中间输出,这样所有分析步骤都可以彼此独立地执行。数据和代码可以在https://osf.io/jbrsa/上公开。
2.2 实例数据集
样本数据集包括10名7岁的儿童(6名女性,4名男性)和10名18岁的成年人(5名女性,5名男性)在情景记忆研究的编码阶段的脑电图数据(图1)。类别由两个不同的范例代表,所有范例都有两次呈现。刺激被连续地呈现在电脑屏幕中央的白色背景上。一个中央固定十字架被叠加在物体上,并在整个任务过程中一直保持在屏幕上。刺激呈现持续1500 ms,刺激间间隔抖动在1500 ~ 2000 ms之间。刺激顺序是伪随机化的,3~10个刺激(来自其他类别)出现在同一项目的重复之间,至少5个项目出现在同一类别的不同样本之间。参与者被要求注意物体,但要盯着十字架,以尽量减少眼球运动。为了确保参与者参加了每次试验,他们执行了一项目标检测任务,要求他们在注视十字从黑色变为品红时按下按钮。
这里提供的脑电图数据是通过预处理、无人工干扰的单受试者单试验TFRs (详细信息见下文)。因此,在排除脑电图数据中有伪影的实验数据后,得到的TFRs的试验数量因参与者而异。本教程中的TFRs是表征相似性分析的基础。此外,对于示例数据集,还提供了项目内相似性和类别内相似性(但不提供类别间相似性)的所有中间输出。有关数据集请参阅 https://osf.io/jbrsa/wiki/。
2.3 安装运行RSA教程
要对示例数据集运行分析,请将代码存储库和数据下载到您的计算机(https://osf.io/jbrsa/)。另外,请下载FieldTrip工具箱(https://www.fieldtriptoolbox.org/do wnload/)。分析的所有步骤都在单独的函数中实现。每个函数接收一个配置结构作为输入,该结构为各自的分析设置所有可调规范。表1列出了所有实现的步骤。
原则上,分析步骤需要一个接一个地执行,因为前一个步骤的输出通常需要作为下一个步骤的输入。但是,对于示例数据集,还提供了所有中间输出,这样每个步骤都可以单独运行。为了按照预期的顺序运行函数,我们建议使用config_and_run_rsa.m脚本。在这里,您可以调整所有分析步骤所需的配置输入,并逐个运行它们,而不需要调整单独的函数。具体来说,您需要在FieldTrip工具箱config下配置路径设置。pdat(在“路径配置”代码部分),指定在哪里找到数据,在哪里保存结果等。此外,RSA本身需要配置(在代码部分“RSA配置”中),即应该分析哪些数据(年龄组和个体主体id)和哪个表示级别(类型,见下文)。默认情况下,结果保存到指定的文件夹中,但您也可以通过设置config运行任何步骤,输入和输出数据不需要特定的文件夹结构。
表1. 本教程中包含的所有分析步骤以及运行它们的相应函数、配置输入所需的设置、所需的数据以及返回和/或保存的输出。

2.4 关于输入的注意事项:EEG数据的时频表征
在样本数据集中,TFRs包含频率范围从2 Hz到125 Hz。然而,输入的数据并不局限于特定的频率范围或分辨率,而是可以根据研究问题和假设进行改变。对于低频率(2-20 Hz),使用固定宽度为500 ms的汉宁窗,产生2 Hz的频率步长。对于更高的频率(25 -125 Hz),使用宽度为400 ms的离散长球形序列(DPSS)窗,以5 Hz为步长,有7个Slepian窗,产生10 Hz的平滑。我们使用了相对于刺激开始的0.6到2 s的试验时间。通过这种方法,我们获得了每个试验和电极的TFRs,得到了每个参与者的四维功率谱(试验电极频率时间)。根据使用教程所需的FieldTrip数据结构提供数据(参见https://www.fi eldtriptoolbox.org/development/datastructure/)。
2.5 计算表征相似性的估计
RSA可用于研究不同层次的神经表征(见图1)。由相同刺激输入引起的神经激活模式的相似性是表征神经稳定性的指标。而由不同刺激输入引起的激活模式的相似性是这些刺激被表征的独特性的一个指标。这种项目之间的表征相似性可以在来自同一更广泛的刺激类别的项目之间和来自不同刺激类别的项目之间进行评估。
为了测量项目内的表征相似性,在记录大脑活动的同时,各自的刺激项目必须被展示至少两次。一种常见的方法是评估这些第一和第二刺激呈现之间的神经模式相似性。另一种可能是将刺激物呈现两次以上,并将项目内相似度作为所有重复的平均相似度来衡量。对于项目之间的相似性,人们可能会对两个或多个刺激的相似性感兴趣,比如实验中出现的所有刺激(也称为全局相似性),它们可能属于一个或不同的类别。
请注意,类别中的对象在某种程度上是可变的,并且经常在研究之间有所不同。在当前的数据集中,来自同一对象类别(如不同的帽子)的样本被定义为属于一个类别,而不同的对象(如帽子、树)被定义为不同的类别。其他的研究可能会选择更具体的类别或更高级的类别(例如,衣服,植物,或无生命和有生命的物体)。
总的来说,RSA如何用于评估表征性属性,如神经稳定性和特殊性,在方法论上存在很大的差异。不同的方法之间的一般逻辑和过程是相似的,可以轻松地调整和扩展框架,以进行所需的相似性分析。
2.6 项目内相似度(稳定性)的实现
计算RSA的第一步,需要调用函数step1_rsa_get_sim_matrices。对于项目内的相似性计算,需要输入配置类型,来指定所需的相似程度(可以使用config_and_run_rsa脚本来配置和运行每个分析步骤)。对于每个受试者,调用step1_rsa_get_sim_matrices中的self_rsa函数来加载TFRs,如包含所有电极、所有呈现的刺激试验、时间和频率的谱功率,该函数选择了试验的TFRs进行关联。在计算相似性之前,需要对数据进行对数变换,并从TFRs中去除背景噪声谱,以抵消由于脑电图功率谱的1/频率 特性导致的频率模式之间固有高相关性的影响。为此,可以通过函数subtract_mean_noise_spectrum调用应用了一种来自更好的振荡检测(BOSC)框架的方法。
模式相似性分析的核心是通过self_rsa调用函数spectral_rsa实现各个TFRs的相关性。在每个电极上分别计算两个时间频率模式矩阵(pattern 1 and pattern 2; see Fig. 2A),这里有31个频率箱,从2 Hz到125 Hz(见上图),326个时间点,从刺激开始前0.6 s(0)到刺激开始后2 s。其中,第一种模式的每个时间点tp1的频率向量与第二种模式的每个时间点tp2的频率向量相关。因此,我们得到了每个tp1*tp2组合的相关系数。如果没有指定,则使用Pearson相关性。得到的相关矩阵然后进行Fisher-z变换并返回,它表示两个光谱模式在所有时间点组合时的相似性。对所有电极(成人为60个,儿童为64个头皮电极)重复此过程,得出每对相关刺激试验的电极时间-时间相似性矩阵。注意,由于脑电图数据质量的差异和RSA类型的选择,在预处理后的试验数量在参与者之间有所不同。
最后产生的相似性矩阵(类别电极时间*时间)在FieldTrip数据结构中表示(参见https://www.fieldtriptoolbox.org/development/datastructure/)。由于拥有两个时间维度不是有效的数据类型,我们将其中一个时间维度表示为频率,从而产生了一个频率维度,使得FieldTrip将该数据视为TFRs。FieldTrip除了常见数据和元数据字段外,RSA中相关的原始试验和对象类别的附加信息也保存在其数据结构中。然后,函数step1_rsa_get_sim_matrices将各个相似度数据保存在指定的输出文件夹中。
在开始平均数据之前,我们建议仔细检查试验中的部分相似结果)。这有助于获得所分析数据集的总体水平和相似性方差的印象,并可能识别出有趣的模式,这些模式可能会在试验中的平均相似性时丢失。
在下一步中,step2_rsa_group_ga计算并保存各个相似度矩阵的平均值。也就是说,每个相似性矩阵在各个项目之间平均,得到一个通道时间相似性矩阵,其中包含独立于单个项目或相互比较的类别的各自表征相似性。每个平均相似度矩阵组合在一个数据结构并保存到指定的输出文件夹。
项目内平均相似度矩阵(在所有电极上平均)和平均相似度矩阵的对角线可以使用step3_plot_sim_matrices绘制(见图3和图4)。对角线显示了相同时间点各自光谱模式的相似性。由于高度的相似性经常出现在对角线上及周围,绘制对角线可以更好地说明不同项目或条件比较。在样本数据集中,成人的模式相似性值总体上比儿童高得多。
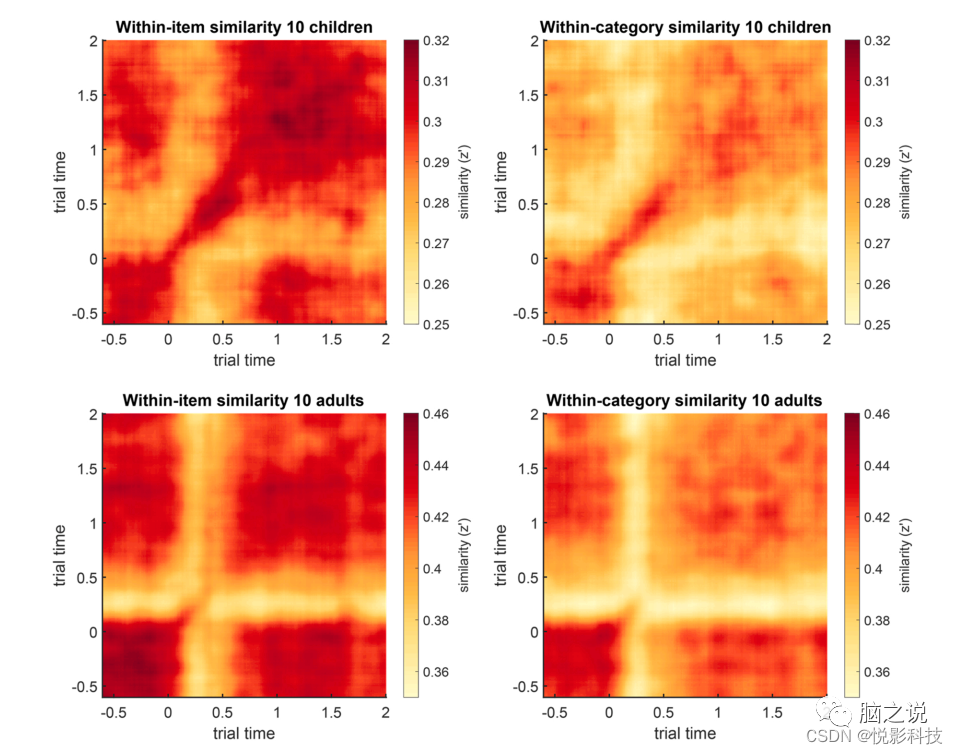
图3 项目内相似度(左)和类别内相似度(右)的时间-时间模式相似矩阵,在10名儿童(CH;上),10名年轻人(YA,下)。相似性用Fisher-z变换后的Pearson相关系数(z)来衡量。
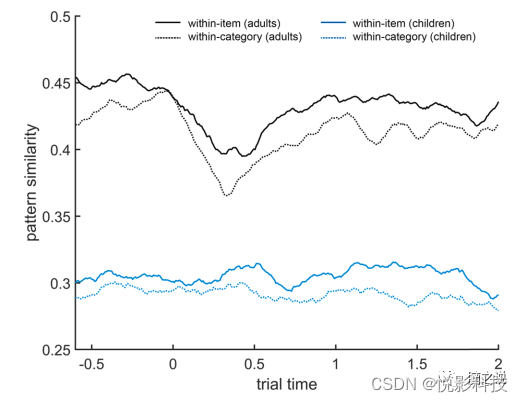
图4 儿童(蓝色)和成人(黑色)的项目内相似性(实线)和类别内相似性(虚线)的时间-时间模式相似性矩阵的对角线(见图3)。可以使用step3_plot_sim_matrices创建这些图。
2.7 项目内相似性(特殊性)的实现
对于来自同一对象类别的项(类别内相似度)或来自不同对象类别的项(类别间相似度),可以计算项间相似度,这可以通过指定配置进行选择。当运行step1_rsa_get_sim_matrices时,分别输入in-cat或between-cat类型。要关联的试验用self_rsa或betw_cat_rsa选择,它们分别由step1_rsa_get_sim_matrices调用,用于表示类别内或类别间的相似性。在计算相似性之前,对数据进行对数变换,并使用BOSC从TFRs中去除背景噪声谱(见上文)。类别内相似度计算为每个对象类别的第一个和第二个范例所诱发的光谱模式之间的相关性(为简单起见,仅第一次呈现)。类间相似度计算为每个类别与所有其他类别之间的平均相似度(为简单起见,仅第一个范例的第一次展示)。这意味着在分类RSA中(就像在项目内RSA中一样),每个对象类别的两个TFRs是相互关联的。具体来说,例如对于n个类别,假如有60个电极,那么就会计算出60n个的时间时间的相关矩阵。与此相反,类别间RSA计算所有可用类别的所有成对组合(自相似性除外),会得到60n-1n-1的时间*时间的相关矩阵。因此,类间RSA需要相当多的计算,相应地需要更长的运行时间。同样,调用spectral_rsa并运行TFRs可以做相关计算。在接下来的步骤中,可以通过step2_rsa_group_ga计算得到相似度矩阵的平均值,并使用step3_plot_sim_matrices绘制结果(与上面相同)。
相似矩阵的对角线将矩阵分为上三角形和下三角形(分别位于对角线的上方和下方)。这些三角形不一定是对称的。例如,对于类别内相似性,在展示的第一个范例期间的神经模式的每个时间点(试验1)会与第二个范例的神经模式的每个时间点(试验2)进行比较。如果试验1的开始与试验2的结束表现出高度相似性,那么这种高度相似性将在其中一个三角形中出现,而不是在两个三角形中出现。另一个三角形的对称点则会显示试验1结束和试验2开始的相似性。然而,对于所有两两比较都要计算的项目之间的相似性(这里是类别之间的相似性),两个时间点的频率向量的每个相关性实际上都要计算两次,因此出现在对角线的两边。每个相似度矩阵并不相同,但是当计算所有刺激组合的平均相似度时,得到的平均相似度矩阵在对角线上对称。在这些情况下,其中一个三角形足以绘图和后续分析。
2.8 RSA矩阵的统计比较
根据研究问题和比较水平,我们在FieldTrip上使用不同的统计检验。为了检验表征相似性矩阵的差异,主要的工具是非参数聚类的随机排列统计,可以解释多重比较问题,可以计算所有电极上的时间时间相似性矩阵的单变量双边、依赖或独立t统计量。聚类是通过将p值低于0.05(空间和时间)的相邻通道时间*时间的样本分组形成的。然后分别的测试统计数据被确定为集群中所有t值的总和。我们使用蒙特卡罗方法来计算总结的簇级t值的参考分布。为了推导出在组间/条件之间没有差异的零假设下的参考分布,将样本反复分配到任意组,并计算这些随机组之间的t检验,并在各自的集群内求和。最后,将真实组比较得出的给定集群的汇总t值与随机赋值得出的相同集群的汇总t值的参考分布进行比较。
2.9 实现
在FieldTrip中使用ft_freqstatistics函数来计算实现时频数据(有关详细教程,请参阅https://www.fieldtriptoolbox.org/tutorial/cluster_permutation_freq/)。由于这些统计测试旨在获得频率分辨数据,我们再次通过将电极-时间-时间的相似性矩阵的一个时间维度表示为频率来构造TFRs。FieldTrip函数接收一个配置输入cfg指定所需的计算。根据应用的数据,输出数据包含所有通道时间时间的t-map、p-值、集群维度等统计值。
2.9.1 表征水平的比较(项目特异性和类别特异性)
假设我们用大脑记录技术测量的神经模式确实代表了输入呈现的特定内容,我们就会期望相关内容(例如,来自同一刺激类别)之间的表征相似性高于不相关刺激之间(例如,来自不同类别)。因此,一些研究,特别是那些与神经分化的年龄相关差异相关的研究测量了神经表征(类别)的特异性,将类别内相似度校正为类别间相似度。
类似地,神经项目表征的特异性被定义为比与其他类似项目的表征相似性更高的项目稳定性,因此被评估为项目内和类别内相似性的差异。项目特异性的评估是一种通过量化或测试它们的差异来结合神经稳定性和神经特异性的措施。在本教程中,我们通过直接测试每个参与者的项目内相似性和类别内相似性来实现项目特异性(即第一级分析)。随后,我们第一级分析的t值进行检验,以检验这些差异在群体层面上是否可靠(第二级分析)。组间比较(三级分析)见2.4.2节。同样,对类别特异性的测试也包括对类别内相似性和类别间相似性的测试。
注意,除了刺激内容(例如,呈现的物品或类别),其他因素也可能影响它们的神经表征相似性,例如它们在实验中的时间距离。这些混杂因素需要加以识别和纠正。
2.10 第一级(目标内)分析的实现
在函数step4a_sim_comparison_1st_level中实现比较所有指定参与者的单个项目内相似度和类别内相似度矩阵。这里,在FieldTrip输入cfg以指定ft_freqstatistics进行统计测试运行。对于每个项目,使用双配对t检验对项目模式相似性与其他项目模式相似性进行对比。由此产生的t-maps可以被认为是代表水平之间差异的逐点效应大小测量。将t-maps返回统计输出,并将其保存为1st_level_stat到指定的输出文件夹中。
2.11 第二级(组内)分析的实现
在step4b_sim_comparison_2nd_level中,使用双边独立样本t检验对第一级分析的t-maps进行检验,通过基于聚类的随机排列检验进行多重比较。输出的stat2包含了正的和负的聚类统计信息以及识别的聚类的通道时间坐标,并保存为2nd_level_cluster_stat(https://www.fieldtriptoolbox.org/faq/how_not_to_interpret_results_from_a_cluster-based_permutation_test /)。聚类是正的还是负的,取决于效果的方向,在这种情况下,这是由在一级分析中对比类别内相似性和类别间相似性的顺序决定的。在提供的数据集和当前设置下,分析发现儿童样本有2861个阳性和271个阴性簇,成人样本有1788个阳性和137个阴性簇。在这些聚集性病例中,2例儿童阳性聚集性病例和1例成人阳性聚集性病例超过97.5% (ps <0.025)为各自的参考分布,表明在两年龄组均有显著影响。在这里,正聚类表明项目内相似性显著高于类别内相似性(项目特异性)。注意,排列的数量决定了p值可以有多小。当排列数量大于500时,p值不能小于0.002。
所识别的聚类包含了广泛的时间-时间组合范围和所有电极(见图5),表明在类别内和类别内的相似性方面存在广泛的差异,因此具有高度的物品特异性神经表征。利用识别出的聚类维数,可以从差异可靠的通道时间时间坐标中提取相似值(见图6)。
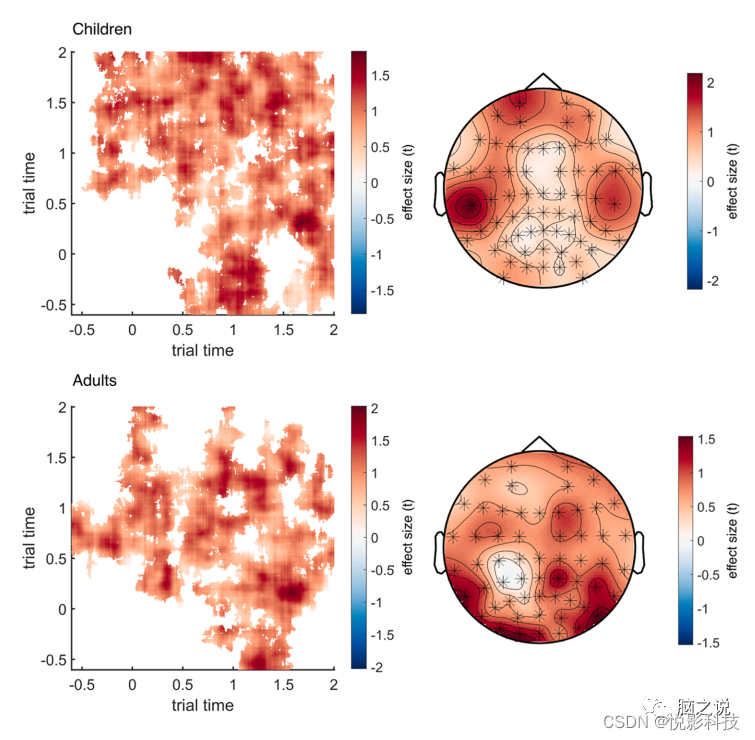
图5 在儿童(上)和成人(下)的聚类中显示项目特异性(即,项目内和项目间相似性的可靠差异)的效应大小(t值)的可视化
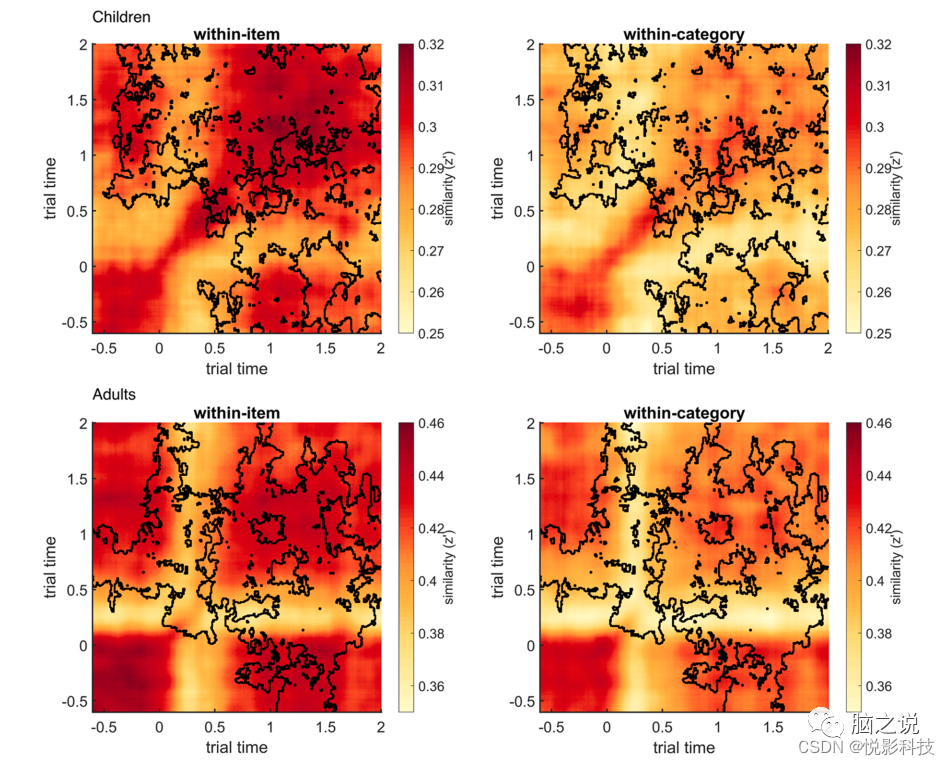
图6 模式相似性矩阵(与图2相同)加上已识别的簇的轮廓(见图5),从儿童(上)和成人(下)的时间-时间坐标中项目内(左)和类别内(右)相似性可以看出稳定的差异和平均电极。
2.11.1 年龄组比较
可以采用不同的方法测试不同年龄组的神经表征特性是否不同。一种简单的方法是基于聚类的排列分析,类似于上面描述的方法,直接对比不同年龄参与者的相似性数据。这可以表明不同年龄段的大脑皮层区域和时间点可能显示出可靠的模式相似性差异。然而,对这种年龄效应的解释需要仔细考虑,因为它们可能是由于许多不特定的年龄差异而出现的,例如,颅骨厚度在很大程度上影响脑电图信号。为了避免解释年龄的主要效应,如神经激活的绝对差异,而将注意力集中在诸如人体内效应的年龄差异等方面,可以将这些混杂因素的影响降至最低。因此,在当前的分析过程中,我们建议比较不同年龄组之间的人内项目特异性效应差异(即,项目内相似性高于项目间相似性),而不是绝对相似性值。具体来说,在群体层面(二级分析)识别的聚类可以用于提取在那些通道时间时间坐标上显示可靠差异的特定于目标的相似值(或效应大小),然后可以在组间进行对比。本教程采用了这种方法来研究儿童和成人在神经项目特异性方面是否存在差异。
2.12 第三级(组间)分析的实现
在step4c_sim_comparison_3rd_level上对比儿童和成人的神经特异性。对于每个组,使用ps <0.025进行二级分析得出的所有聚类;计算信道时间时间中单个项内和类别内的相似值。将这些提取的相似点平均(见图7)并保存。
计算每个受试者的项目内和类别内相似性之间的差异,然后用于年龄组比较,使用标准的双边独立样本t检验来计算年龄差异的项目特异性(见图8)。结果在命令窗口中返回。在提供的样本数据集中,儿童和成人的项目特异性没有显著差异(t = 0.93, p = 0.364)。
同样,不使用简单的差异评分,在一级分析中获得的单个效应大小可以在聚类中提取并平均(这里没有实现)。这也可以表明项目内和类别内的相似性有多大的差异,从而表明神经表征对项目的特异性有多大,然后可以在年龄组之间进行比较。
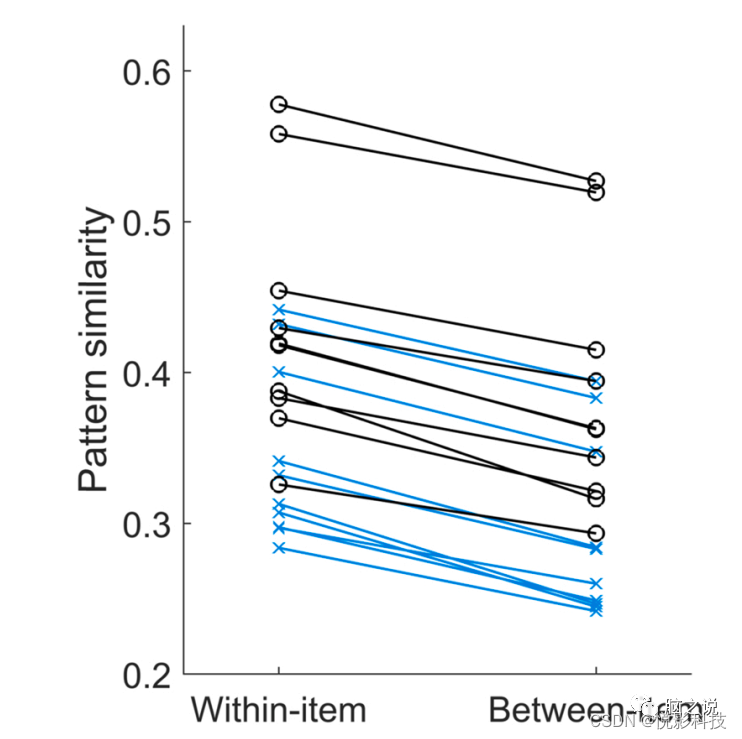
图7 在个体水平比较平均项目内和项目间模式相似性(蓝色,x)和成人(黑色,o)。
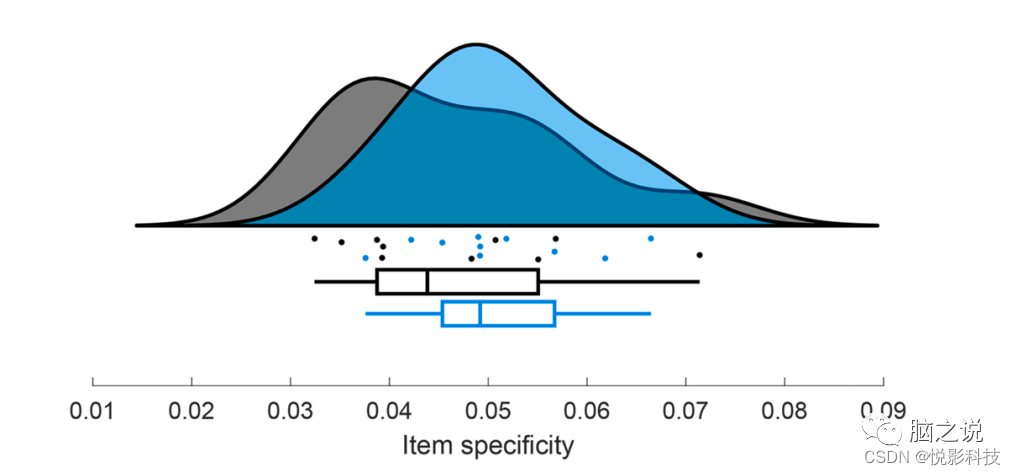
图8 儿童(蓝色)和成人(黑色)的项目特异性(计算为项目内和类别内相似性的差异)。
2.13 与行为联系
我们对项目特异性的测量可以反映在刺激编码期间的神经激活模式表示了多少刺激特异性信息。根据之前的研究,表现出更多特定项目神经表征的成年参与者比表现出较少特定项目神经表征的参与者能更好地记住物品。当前数据集的参与者在编码阶段之后进行了记忆识别测试。在识别任务中,给出了精确的项目重复和全新的物体,从而实现了对精确的项目记忆的估计。这里,作为一个例子,我们将项目记忆表现与神经项目特异性(计算在上面)联系起来,以识别大脑和行为之间的人与人之间的联系。还可以通过其他分析来研究神经特异性差异的行为效应,例如,可以计算出后续的记忆效应,即项目特异性在人体内的关联以及相应的记忆结果。
2.14 实现记过
参与者记忆表现在示例数据集(CH+YA_mean_item_memory.mat)中提供。脚本step7_correlation_with_behavior加载单个项目特异性和项目记忆数据,并使用Pearson相关性将它们关联起来,分别针对儿童和成人,以及跨年龄组。结果将在命令窗口中返回。此外,我们绘制了一个散点图来说明相关性(图9)。来自样本数据集的结果表明,项目记忆和项目特异性可能正相关,但相关性不显著(儿童:r = 0.18, p = 0.612;成人:r = 0.41, p = 0.245;组间:r = 0.35, p = 0.128)。
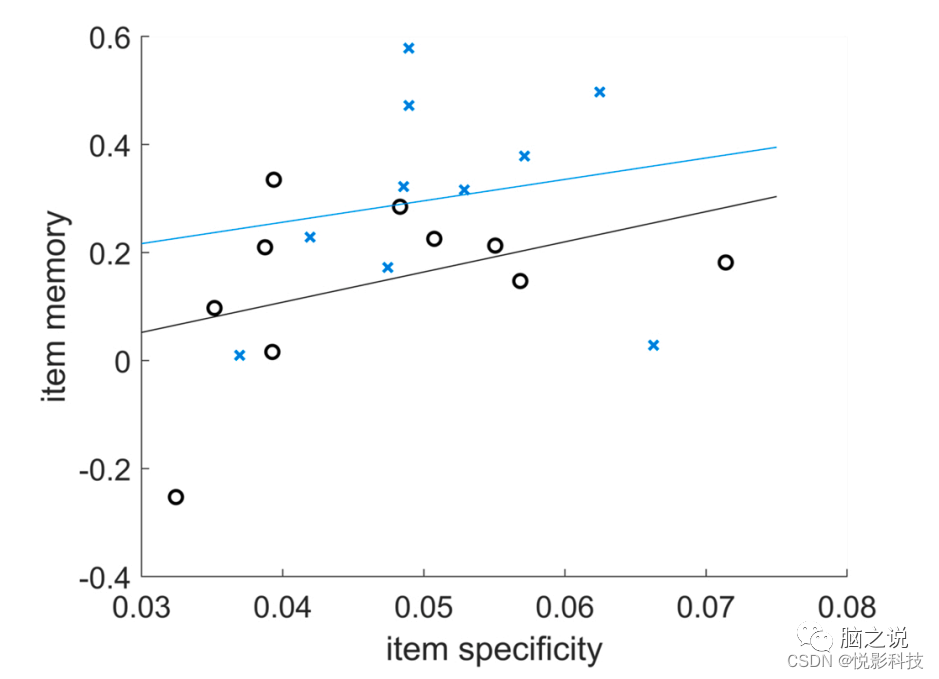
图9 儿童(蓝色,x)和成人(黑色,o)的项目特异性和项目记忆的被试关联之间用最小二乘法线表示。
2.15 进一步应用
RSA可用于计算特定刺激的神经表征相似性,识别相似性中的差异,比较不同年龄组之间的差异,并将其与行为联系起来,目前的教程只是其中的一个例子。我们已经在上面提示了更多的选项,并简要列出了这些和其他可行的应用程序:
– Category specificity:类别特异性表示在神经激活模式中有多少类别信息被表示出来,并以类别内相似性和类别间相似性的差异来衡量。它是fMRI中与衰老相关的神经去分化的经典测量方法之一,表明神经表征在老年时变得不那么明显,但其与认知关联的证据是混合的。通过分别用类别内相似度数据和类别间相似度数据替换项目内相似度数据和类别内相似度数据,可以简单地调整当前管道的类别特异性。
– Pattern reinstatement:模式恢复是编码过程中的激活模式与检索过程中的激活模式的相似性,例如在识别或回忆任务,因此与模式稳定性密切相关。它是情景记忆模型的关键要素,涉及事件编码的过程也涉及事件检索。项目信息的恢复已在时间和光谱(颅内)脑电图模式中得到证实。通过使用带有不同数据的self_rsa脚本,即编码和检索数据,而不是编码期间的第一和第二表示,可以调整当前的教程来进行模式恢复分析。
– Global similarity/matching:全局相似性/匹配是指在实验或条件下呈现的所有刺激之间的表征相似性。就像类间相似度的实现一样,计算所有两两比较。认知理论认为,对一件物品的记忆强度源于该物品的表征与对其他已编码物品的表征的相似性。通过分别计算已记忆项目和未记忆项目的项目相似性,并将它们与用于统计比较的脚本进行对比,当前可以用于检查全局相似性和内存性能的关联。
– Representational dissimilarity matrix (RDM):表征不同度矩阵(RDM)是指所有成对项目不同度 (相似度的倒数,如相关距离r 1,或可解码性),从而表征表征的信息结构。行和列对应于单个项,每个单元格是两个项之间的(非)相似性(例如,平均时间-时间相似性矩阵)。这些RDM可以与来自其他大脑区域或其他虚拟模型、行为以及个体或物种之间的RDM进行比较。也就是说,在这一步中比较的是表示的信息结构,而不是活动模式本身。当前教程可用于运行所有成对项目相似性(类别之间的相似性)。需要对产生的时间-时间相似性矩阵进行平均,以获得每个参与者的每一项对的一个相似性值,然后在一个RDM中进行说明,并与其他RDM进行比较。
– Subsequent memory effects:随后的记忆效应显示了人的神经活动对随后记住的事物和不记得的事物的反应差异。在计算个体相似性矩阵之前,根据每个参与者的记忆结果将项目分开,这可以应用于表征相似性的任何测量。然后,可以使用基于聚类的排列分析来对比已记忆和未记忆项目的相似度矩阵。
2.16 根据自己的数据调整代码
教程专门用于分析所提供的数据集,需要进行调整以适用于其他数据格式。由于本教程依赖于FieldTrip工具箱及其数据结构,我们建议读者也使用FieldTrip的预处理和/或频率分解工具,因为这些工具可以生成所需格式的tfr,或者将数据转换为FieldTrip格式。此外,当前教程中的试验选择是特定于示例数据集和内存任务范例的。为了应用于您自己的数据,您还需要提供具体的试验信息,例如,关于项目重复次数和类别成员。该信息在self_rsa和betw_cat_rsa中使用,需要进行调整,以选择那些需要关联的试验。
参考文献:Spectral pattern similarity analysis: Tutorial and application in developmental cognitive neuroscience














 7740
7740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









