







1. 摘要
越来越多的证据表明,精神疾病,如重度抑郁症(MDD)和自闭症谱系障碍(ASD),并不是单一的疾病,而是包含多种共现症状和不同治疗反应的异质性综合征。这种临床异质性阻碍了精准诊断和治疗效果的进展。在本研究中,我们提出了一种新的可解释图神经网络 (GNN) 框架——BPI-GNN,用于分析功能磁共振图像(fMRI),利用了著名的原型学习。此外,我们引入了一种新的原型子图生成过程,以发现不同原型的关键边缘,并使用总相关性 (TC) 来确保不同原型子图模式的独立性。BPI-GNN能够有效地区分精神病患者和健康对照 (HC),并识别具有生物学意义的精神疾病亚型。我们对三个精神病数据集上的 11 种流行脑网络分类方法的性能进行了评估,发现我们的 BPI-GNN 总是获得最高的诊断准确性。更重要的是,我们检查了识别出的亚型在临床症状和基因表达谱方面的差异,并观察到我们识别出的基于大脑的亚型具有临床相关性。它还发现了与当前神经科学知识一致的亚型生物标志物。
2. 引言
精神疾病是全球医疗系统造成广泛社会和经济负担的主要原因之一,并严重损害受影响者的福祉。尽管经过数十年的研究,精神病学中统一或确定的生物标志物仍然不确定。一个可能的原因是,目前的精神疾病诊断主要基于临床症状和体征,而不是潜在的生物学机制。例如,当患者表现出九种临床症状中的五种(如情绪低落、快感缺失和认知障碍等)时,他们被诊断为重度抑郁症 (MDD),这导致了具有相同诊断的患者之间的高度临床异质性。由于这种临床异质性,研究人员无法通过传统的病例对照研究(将所有具有相同诊断的患者与健康对照进行比较)获得可靠的生物标志物。更重要的是,它阻碍了精神疾病治疗效果和结果的进展。
为了应对这一问题,发布了研究领域标准 (RDoC) 计划,并启动了“精神病学精准医学”项目。其核心思想是基于潜在的生物学和认知测量来识别精神疾病亚型,而不仅仅依赖于传统的症状诊断方法。迄今为止,一些研究已经开始利用静息态功能磁共振成像 (fMRI) 这一特别有用的方式来研究精神疾病的生物学意义亚型。fMRI 是一种非侵入性的神经影像技术,它通过计算 fMRI 时间序列的成对相关性(功能连接,FC)作为特征,来研究各种患者群体中的神经生物学和精神病亚型。大多数现有的神经影像学研究都使用混合框架,包括特征选择(例如,典型相关分析 (CCA) 和自动编码器 (AutoEncoder))和无监督方法(例如,层次聚类和 k-means 聚类)。具体来说,研究人员首先使用特征选择方法获得低维表示或相对较少的FC,然后将这些低维生物特征应用于无监督学习方法,以识别精神疾病的亚型。然而,现有的精神疾病亚型研究方法容易导致次优解决方案,因为很难保证所使用的特征选择和无监督学习方法是最优和最适合的。此外,由于缺乏下游任务的真实情况,这些框架可能会得到不一致的结果和不可靠甚至不准确的预测,例如亚型数量不一致。
原型学习是一种基于案例的推理,通过将新实例与一组学习到的范例案例进行比较,促进了对新实例的预测。到目前为止,原型学习的概念已经被集成到图像识别(图1)中,以提高可解释性,从而能够提供子类型级的解释。例如,ProtoPNet利用原型学习和卷积神经网络(CNN)的融合,获取特定类别中的原型部分,并产生直观的图像解释。然而,目前对于将原型学习应用于图形分类任务或大脑网络分析,还没有令人信服的先例。
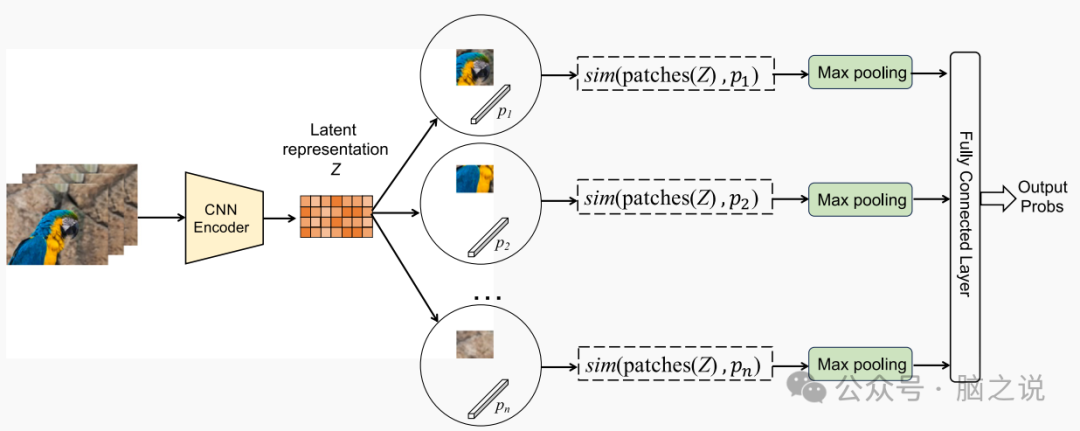
图1. 传统的图像识别原型学习。给定一个输入图像𝐼,框架使用卷积神经网络(CNN)𝑓提取图像表示𝑍=𝑓(𝐼),并学习𝑛原型向量𝑃={𝑝𝑖}𝑛𝑖=1。随后,框架计算𝑗th原型𝑝𝑗与所有𝑍补丁之间的距离,然后将其进行反转,得到相似度得分𝑠𝑖𝑚(𝑍,𝑝𝑗)= max𝑧∈patches(𝑍)
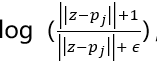
,其中𝜖被设置为一个小值,如1e-4。然后在这些相似度得分之后是全局最大池,从而得到一个单一的相似度得分。最后,将𝑛相似度得分发送到全连通层,以产生输出概率。
为了克服这些挑战,图神经网络 (GNN) 因其处理图结构数据的强大能力,最近在功能磁共振成像 (fMRI) 研究中获得了广泛关注。具体来说,GNN 可以直接在脑网络图上操作,保留原始图结构信息,而无需将其转换为矢量表示。这使得 GNN 能够捕捉脑区之间复杂的非线性关系,而这些关系在传统方法中可能会丢失。现有的基于GNN 的方法已经显示出在精神疾病诊断中的有效性,但它们主要集中于区分患者和健康对照 (HC),而没有考虑精神疾病的异质性。此外,尽管这些方法在预测性能上表现良好,但它们通常缺乏可解释性,使得很难理解模型做出决策的原因。为了解决这些问题,我们提出了一种新的基于图神经网络的框架——BPI-GNN(Brain Prototype-based Interpretable Graph Neural Network),用于精神疾病的诊断和亚型划分。我们的主要贡献如下:
-
可解释性 GNN 框架:我们引入了原型学习机制,使得模型能够学习脑网络的原型,这些原型可以解释模型的决策过程。每个原型代表了一组具有相似脑网络特征的患者子集,从而为精神疾病的异质性提供了新的见解。
-
原型子图生成:我们提出了一种新的原型子图生成过程,以发现不同原型的关键边缘,并使用总相关性 (TC) 来确保不同原型子图模式的独立性。这种方法能够识别出具有生物学意义的亚型,进而促进精准医学的发展。
-
高效的精神疾病诊断:我们在三个精神病数据集上对 11 种流行的脑网络分类方法进行了评估,结果表明 BPI-GNN 总是获得最高的诊断准确性。
-
临床和基因表达分析:我们进一步检查了识别出的亚型在临床症状和基因表达谱的差异,发现基于大脑的亚型具有临床相关性,并识别出与当前神经科学知识一致的亚型生物标志物。
总之,我们提出的 BPI-GNN 框架不仅在精神疾病诊断中表现出色,而且在识别和解释精神疾病亚型方面具有很大的潜力。我们的研究为精神病学精准医学的发展提供了新的方向和工具。
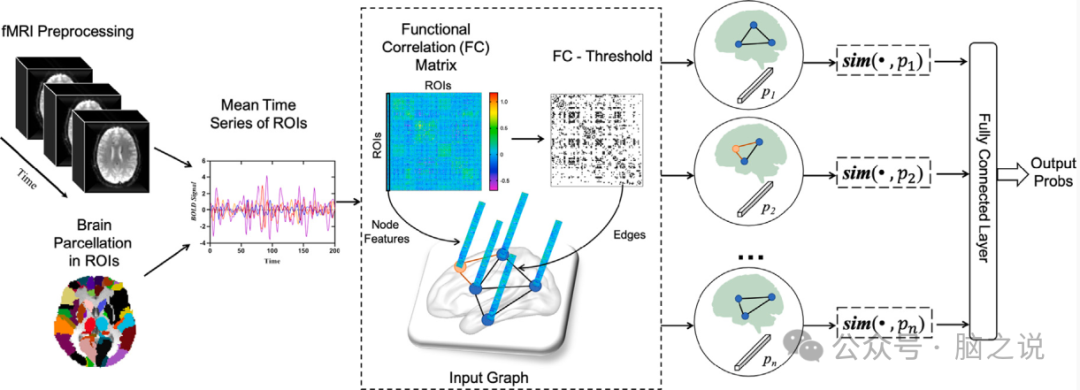
图2. 脑网络分析的原型学习(例如,BPI-GNN)。静息态功能磁共振成像数据进行预处理,随后使用图谱将其划分为感兴趣的区域。然后通过ROI之间的皮尔逊相关性生成功能连接(FC)矩阵。这些FC矩阵被用来构建大脑功能图。然后,BPI-GNN生成一组原型子图,并学习𝑛原型向量。随后,BPI-GNN计算了原型和原型子图之间的相似性。最后,将𝑛相似度得分发送到全连通层,以产生输出概率。
3. 背景知识
3.1 用于精神病学诊断的GNN(图神经网络)
3.1.1 GNN
图神经网络(GNNs)利用消息传递机制,沿着输入图的边缘有效地传播和聚合信息,从而获得表达性节点表示。GNN架构由𝐿层组成,每个层包括三个基本步骤。(1)首先,在第 层 GNN 中,为每条边计算消息,其中 和 分别对应于前一层中节点和 的表示,
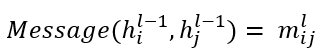
。(2)其次,对于每个节点 ,GNN 从其邻域 中聚合接收到的消息,使用一个聚合函数:
![]()
。(3) 最后,GNN 通过应用函数
![]()
更新每个节点的向量表示,其中聚合后的消息和当前节点表示作为输入。最终的节点嵌入
![]()
由 GNN 最后一层获得的隐藏表示得到。在获得节点嵌入后,GNN 采用 READOUT 函数来学习整个图的表示:
![]()
, 其中是图的表示。在本研究中,我们使用 sum-pooling作为 READOUT 函数来学习图嵌入:
![]()
。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









