







前言
毫不夸张的说在中国除了婴幼儿及七八十以上的老年人,都有过网购经历。电商公司就如雨后春笋般迅速发展。了解用户的网购行为,有助于商家定品类,定营销方案等。利用数据分析与挖掘,争取做到比顾客自己还了解TA自己。
文章目录
一、背景
Ⅰ 数据来源
该数据集来自The UCI Machine Learning Repository,为了更贴合我的分析目的,我自己在这个基础进行了一些修改。对不需要的数据进行了删除,添加了一些需要的数据。
Ⅱ 数据背景
该数据集是英国某电商在2010-12-01到2011-12-09的全部在线销售数据,采用的是我进行整改后的数据,包含541904个样本和九个特征值,分别是发票编号,商品品类,购买日期,购买时间,数量,单价,总价,客户编号,国家。发票编号前面有c的订单为退货,数据为负的也代表退货。
Ⅲ 分析目的
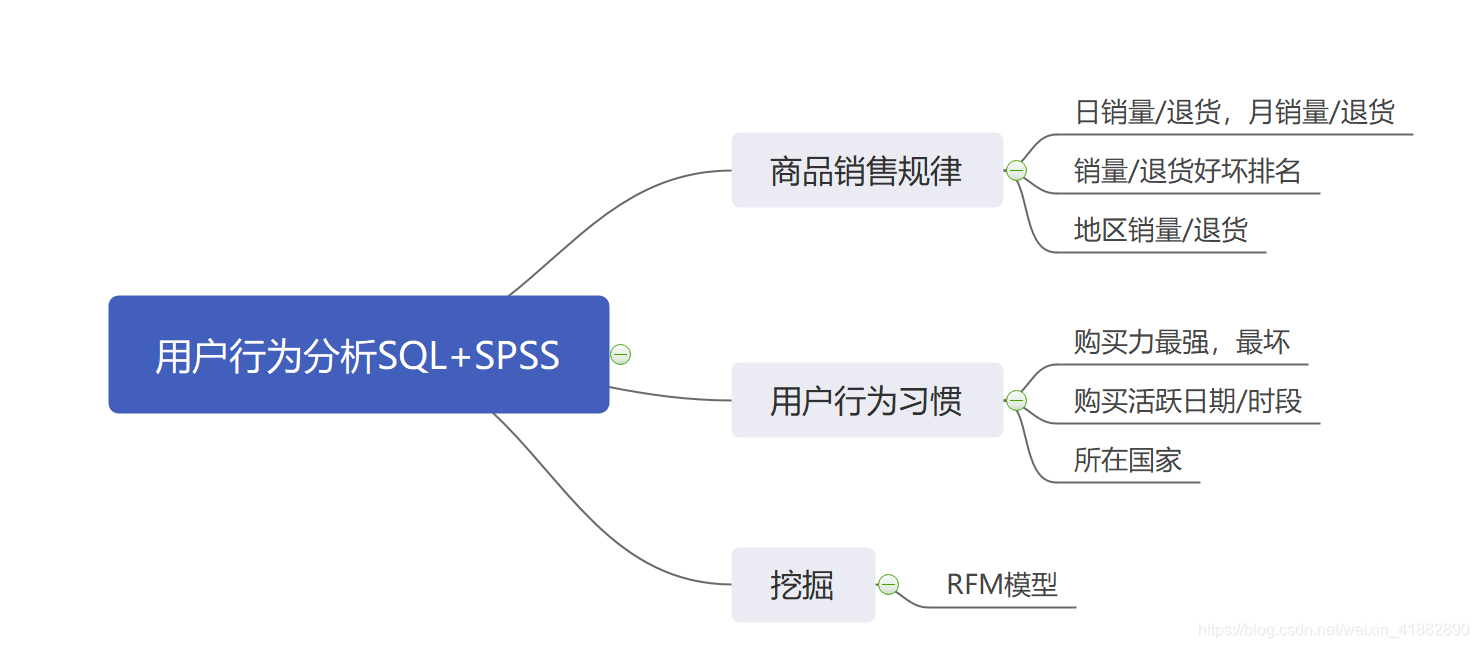
二、探索性分析
Ⅰ 数据导入
一、创建数据表
CREATE TABLE `users` (
`InvoiceNo` varchar(30) DEFAULT NULL,
`GOODS` varchar(30) DEFAULT NULL,
`Dates` date DEFAULT NULL,
`Times` time DEFAULT NULL,
`Quantity` int(11) DEFAULT NULL,
`UnitPrice` float DEFAULT NULL,
`Total` float DEFAULT NULL,
`CustomerID` varchar(30) DEFAULT NULL,
`Country` varchar(30) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
二、插入数据
LOAD DATA INFILE 'D:UsersBehavior.csv'
INTO TABLE users
CHARACTER SET utf8
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '"'
LINES TERMINATED BY '\n'
ignore 1 lines;  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5751
5751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









