







时间:2017年5月
出处:http://blog.csdn.net/csearch/article/details/71244171
声明:版权所有,转载请联系作者并注明出
虽然目前工业界很少再直接通过itemCF来进行推荐,但可以从这个算法中体会到这种集体智慧的应用。
1.ItemCF原理
充分利用集体智慧,即在大量的人群的行为和数据集中收集答案,以帮助我们对整个人群得到统计意义上的结论,推荐的个性化程度高。
基于以下两个出发点:
(1)兴趣相近的用户可能会对同样的东西感兴趣;
(2)用户可能较偏爱与其已购买的东西相类似的商品。
也就是说考虑进了用户的历史习惯,对象客观上不一定相似,但由于人的行为可以认为其主观上是相似的,就可以产生推荐了。
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户,如图所示:
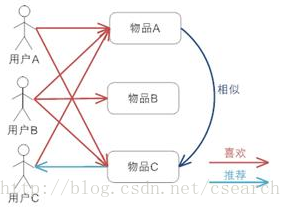
上图表明基于项目的协同过滤推荐的基本原理,用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,
从这些用户的历史喜好中可以认为物品A与物品C比较类似,喜欢物品A的都喜欢物品C,基于这个判断,用户C也可能喜欢物品C,
所以推荐系统将物品C推荐给用户C。
基于物品的协同过滤关键步骤
(1)计算物品之间的相似度。
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
ItemCF算法并不利用物品的内容属性计算物品直接的相似性,她主要通过分析用户的行为记录计算物品直接的相似度。
IUF(Inverse User Frequence)参数,即用户活跃度对数的倒数的参数,认为活跃用户对物品相似度的贡献应该小于不活跃的用户。
2.Python版本代码示例
2.1.读取数据集
from collections import defaultdict
# data_path = "../data/ml-1m/ratings.dat";sep = "::"
data_path = "../data/ml-100k/u1.base";sep = "\t"
fp = open(data_path, "r")
user2item_matrix = defaultdict(defaultdict) # 用户到物品的评分矩阵
item2user_matrix = defaultdict(defaultdict) # 物品到用户的倒排评分矩阵
# UserID \t MovieID \t Score \t Time
for line in open(data_path):
lines = line.strip().split(sep)
userID, movieID, score = lines[0],lines[1],lines[2]
user2item_matrix[userID][movieID] = float(score)
item2user_matrix[movieID][userID] = float(score)
fp.close()
print("totol users:",len(user2item_matrix))
print("totol items:",len(item2user_matrix))输出:
(‘totol users:’, 943)
(‘totol items:’, 1650)
2.2.计算物-物相似度矩阵
计算物品之间的相似度公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









