






目录
什么是条件随机场
条件随机场的定义
条件随机场总的来说就是只要满足“条件随机场”这个条件,就可以根据定义的模型去求解我们需要求解的问题,而我们时长需要解决的问题以线性的居多,所谓线性就是满足“线性链条件随机场”,本文也只涉及对“线性链条件随机场”的讲解。
定义(线性链条件随机场) 设与
均为线性链表示的随机变量序列,若在给定随机变量序列X的条件下,随机变量序列Y的条件概率分布
构成条件随机场,即满足马尔可夫性:
当
时,只考虑单边
则称为线性链条件随机场。
所谓线性简单的来说就是随机变量序列X各个节点之间的关系是呈线性的,序列Y也一 一对应着各个节点的X,而不是其他乱七八糟的关系,也就是满足马尔可夫性。
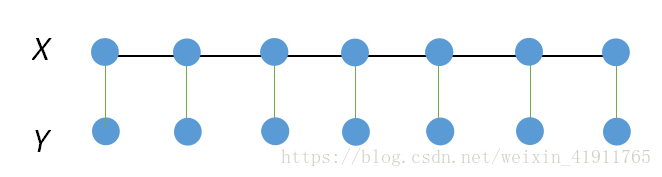
回忆一下马尔可夫链的两个假设
| (1)齐次马尔可夫假设: | 即t时刻的状态只受t-1时刻状态的影响 |
| (2)观测独立性假设: | 即任意时刻的观测只受该时刻所处状态的影响 |
在线性条件随机场里面t时刻的状态往往受到前后两个状态的相互影响从而有(条件概率分布):
假设线性条件随机场的应用
它的应用场景与HMM隐马尔科夫模型的类似,因此我们要解决的问题也对应了前面HMM模型的三个问题:
1.概率计算问题:给定参数,计算观测序列出现的概率,如,
等为后面做准备。
2.学习问题:极大化训练数据的对数函数P,求满足P的参数。
3.预测问题:不用说肯定是输出最大的隐藏序列(标注序列)。
条件随机场长怎么样
条件随机场的参数化形式
我们上面给出了了条件随机场的条件分布函数:
但是我们又应该如何得到的表达呢?更近一步地,整个序列Y的条件概率分布
又应该怎么表达呢?
我们先来看教科书式的表达(参数化表达):
假设参数化形式的内部理解
1. 称为特征函数,其中
是对状态序列的特征提取,表示
的特征受
状态的影响。
是对观测序列的特征提取,表示
受
的影响,说到这里是不是很熟悉,没错,它跟HMM很相似,也体现了马尔可夫的两个假设(至于特征又是怎么提取的下面将会以一个例子来介绍)。特征函数的取值为0或1,满足某个特征就取1,不满足就取0。
2. 表示特征函数的一个权值,表示某个特征的重要程度或者是正负方向。
3. 我们对求和项做一个合并
得到 其中
。
令 ,
则
求和项表示对序列
所有的特征求和的一个综合评分
4. 指数化的意义:数据的大小之于某种结果的贡献往往表现出自然指数的增长性,或者是说采用指数化往往比线性对某种目的的拟合性能更好,比如一个女生选男朋友,有三个对象,身高为(170,175,180),100分制的评分,似乎(80,85,100)比(80,90,100)更贴合女生的要求,指数化也是这样,用于拉开线性情况下高分与低分的距离。
5. 是对所有可能的状态序列
求和,其作用是归一化各种情况,以总和为1的形式给出每种情况的概率大小。
如何构建特征函数
OK,那到这里条件随机场的参数化形式就只剩下特征函数怎么求了
一个例子——词性标注问题 :(转自:http://www.jianshu.com/p/55755fc649b1 )
词性标注就是给一个句子中的每个单词注明词性。比如这句话:“Bob drank coffee at Starbucks”,注明每个单词的词性后是这样的:“Bob (名词) drank(动词) coffee(名词) at(介词) Starbucks(名词)”。
下面,就用条件随机场来解决这个问题。
以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为l,可选的标注序列有很多种,比如l还可以是这样:(名词,动词,动词,介词,名词),我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。
怎么判断一个标注序列靠谱不靠谱呢?
就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。
假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它负分!!
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
定义CRF中的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
1. 句子(就是我们要标注词性的句子)
2. ,用来表示句子
中第
个单词
3. ,表示要评分的标注序列给第i个单词标注的词性
4. ,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
几个特征函数的例子
1.当
是“副词”并且第
个单词以“ly”结尾时,我们就让
,其他情况
。不难想到,
特征函数的权重
应当是正的。而且
越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列
2.如果
,
为动词,并且句子
是以“?”结尾时,
,其他情况
。同样,
应当是正的,并且
越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
3.当
是介词,
是名词时,
,其他情况
。
也应当是正的,并且
越大,说明我们越认为介词后面应当跟一个名词。
4.如果
和
都是介词,那么
,其他情况
。这里,我们应当可以想到
是负的,并且
的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
.................一系列的特征函数对序列的每个节点进行评分求和,最后归一化就可以得到当前序列
的概率大小。
前向—后向算法
细看一下分子
先回顾一下条件概率分布函数 的分子部分
如果根据展开应该是这样的:
定义一个函数
表示在x的条件下取得状态
时所有特征的得分
定义一个M阶矩阵
不 同的状态
,对应不同的值,m表示
有m种状态
分布函数的新形式
,
表示对所有序列的非规范化得分的总和
前向—后向算法
对每个指标,定义前向向量
:
起始单元:
递推单元:
可表示为:
表示在已知序列y的情况下从位置0到i的得分,或叫非规范化概率
用图表示
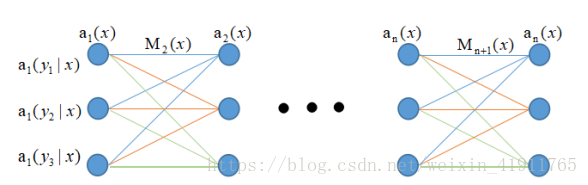

同样,定义后向向量
表示在已知序列y的情况下从末尾位置反向到i的得分,或叫非规范化概率
由前向后向算法不难得到
,1为m维的单位向量。
条件随机场的概率计算问题
状态i为yi的概率
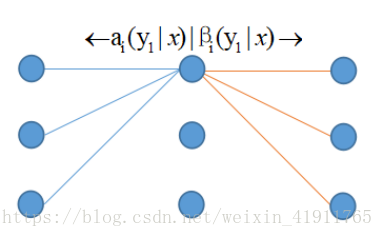
状态i-1为yi-1,状态i为yi的概率
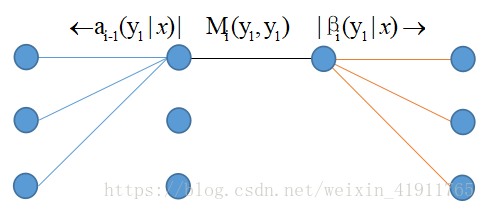
期望值的计算
条件随机场的预测问题
预测问题就是给定条件随机场和输入序列
,求条件概率最大的标记序列
,即对观测序列进行标注
其中
故表示根据指定序列的
,对每一个节点
中的每一个特征函数与权重的成绩乘积求和
是条件随机场预测问题成为非规范化概率(得分)最大的最优化路径问题。
维比特算法
曾记否,在讲HMM时我们也用了维比特算法求最优路径的,大概就是在每个节点求使
最大的
的标注是什么,在遍历完
后返向求取上一个标注,最终得到最优路径在这里也是一样。
为了对每一个节点进行展开计算,我们需要定义
,表示在节点i处各特征得分和的向量
令
,表示i=1节点处乘以权重向量后的得分和的向量
可以表示
的每个分量,m表示状态的个数
表示在节点i-1处取得最大值的项连接到i处各个标注的得分
记录上一个节点的最大位置
当i=n时 就是非规范化概率的最大值
而就是最优路径的终点
将后一个节点的最优值作为当前节点的指针便可以得到当前节点的最优值得
所以
则就是使得概率最大化的最优标注序列。
到最优的标注序列
未完待续
[1] 李航.统计学习方法[M].北京:清华大学出版社,2012:155-184
[2] 如何轻松愉快地理解条件随机场(CRF)?[Online]. https://www.jianshu.com/p/55755fc649b1

















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









