






文章目录
前言
本文为7月24日深度学习笔记,分为五个章节:
- Towards Improving Adam:AMSGrad、AdaBound;
- Towards Improving SGDM:Cyclical LR、SGDR、One-cycle LR;
- Combination of Adam and SGDM:SWATS、RAdam;
- 总结;
- 参考文献。
一、Towards Improving Adam
- fast training;
- large generalization gap;
- unstable.
1、AMSGrad
The convergence issues can be fixed by endowing such algorithms with “long-term memory” of past gradients, and propose new variants of the ADAM algorithm which not only fix the convergence issues but often also lead to improved empirical performance. [Reddi2019]
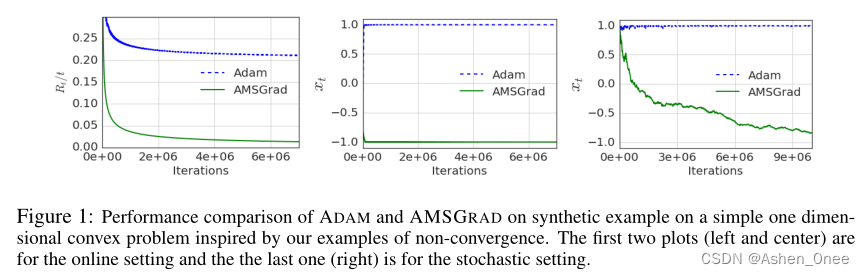
θ
t
=
θ
t
−
1
−
η
v
^
t
+
ε
m
t
v
^
t
=
m
a
x
(
v
^
t
−
1
,
v
t
)
\theta_t=\theta_{t-1}-\frac{\eta}{\sqrt{\hat v_t}+\varepsilon}m_t \\ \hat v_t=max(\hat v_{t-1}, v_t)
θt=θt−1−v^t+εηmtv^t=max(v^t−1,vt)
2、AdaBound
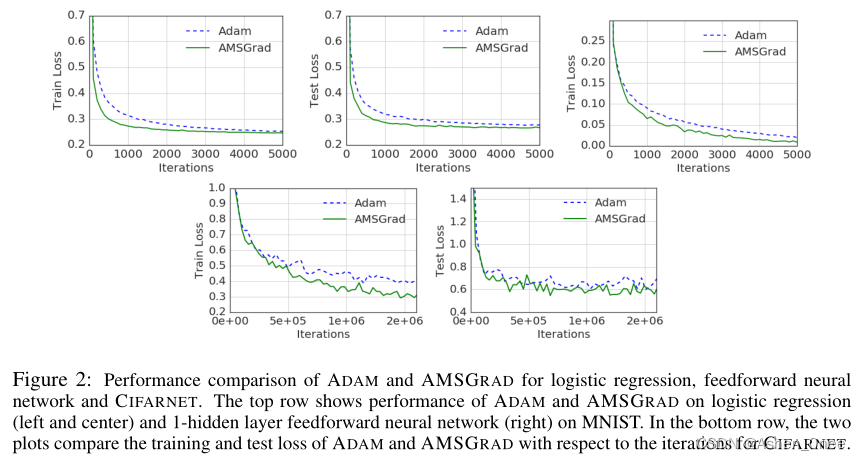
In this paper, Luo et al. demonstrate that extreme learning rates can lead to poor performance. They provide new variants of ADAM and AMSGRAD, called ADABOUND and AMSBOUND respectively, which employ dynamic bounds onlearning rates to achieve a gradual and smooth transition from adaptive methods to SGD and give a theoretical proof of convergence. [Luo2019]
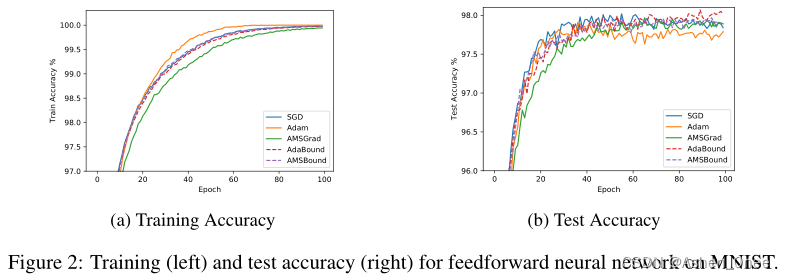
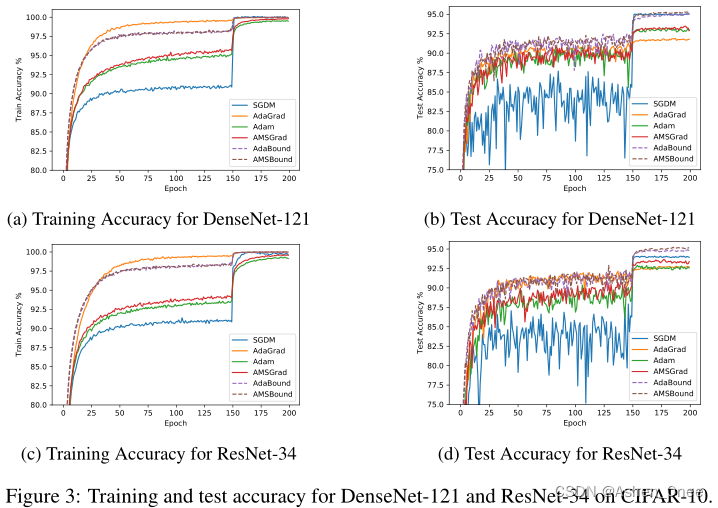
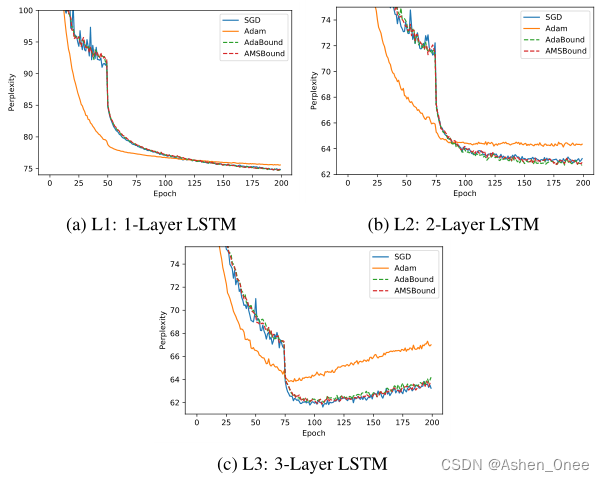
二、Towards Improving SGDM
- stable;
- little generalization gap;
- better convergence.
1、Cyclical LR
This paper describes a new method for setting the learning rate, named cyclical learning rates, which practically eliminates the need to experimentally find the best values and schedule for the global learning rates. Instead of monotonically decreasing the learning rate, this method lets the learning rate cyclically vary between reasonable boundary values. Training with cyclical learning rates instead of fixed values achieves improved classification accuracy without a need to tune and often in fewer iterations. [Smith2015]
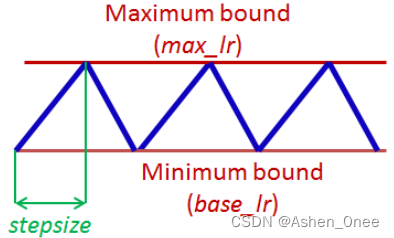
2、SGDR
In this paper, Loshchilov and Frank propose a simple warm restart technique for stochastic gradient descent to improve its anytime performance when training deep neural networks. [Loshchilov2016]
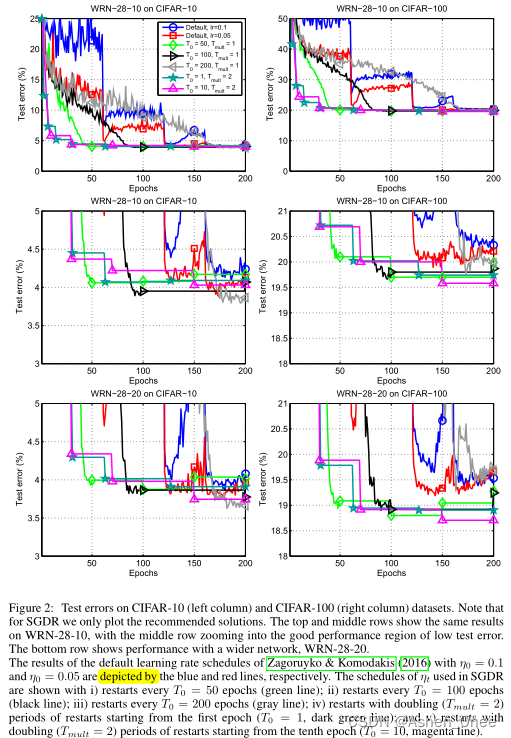
3、One-cycle LR
In this paper, Smith et al. describe a phenomenon, which we named “super-convergence”, where neural networks can be trained an order of magnitude faster than with standard training methods. One of the key elements of super-convergence is training with one learning rate cycle and a large maximum learning rate. [Smith2017]
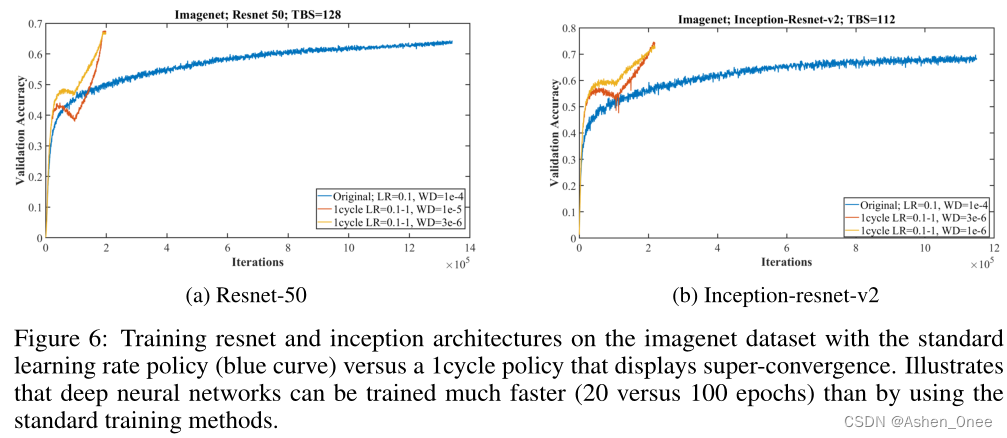
三、Combination of Adam and SGDM
1、SWATS
A simple strategy which Switches from Adam to SGD when a triggering condition is satisfied. The condition we propose relates to the projection of Adam steps on the gradient subspace[Keskar2017].
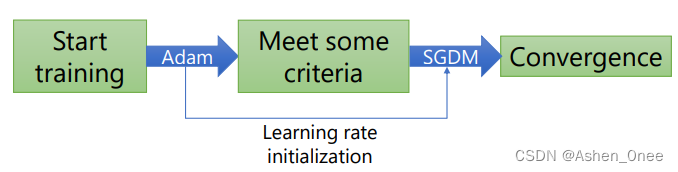
2、RAdam
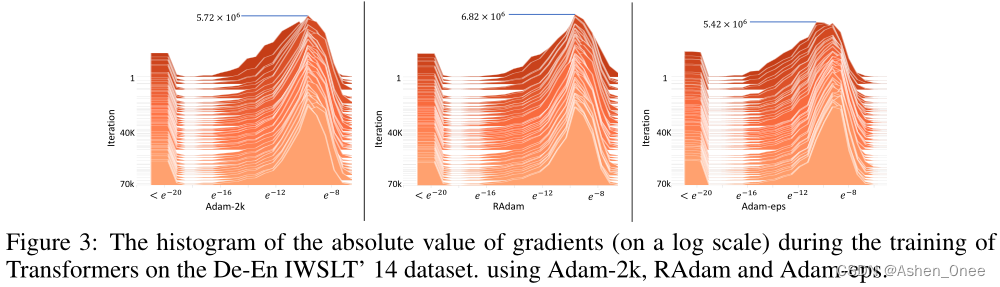
Liu et al. further propose Rectified Adam (RAdam), a novel variant of Adam, by introducing a term to rectify the variance of the adaptive learning rate.[Liu2019]
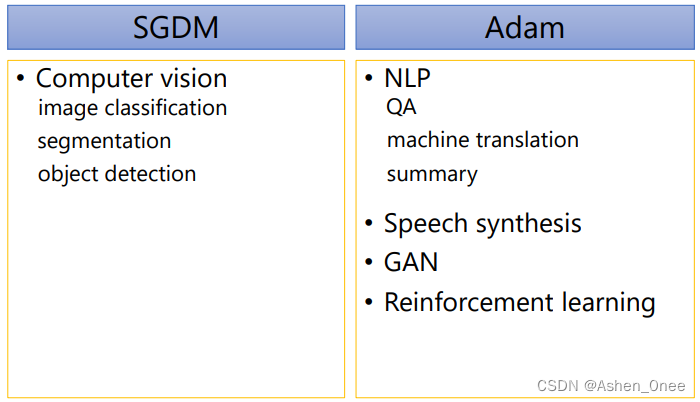
四、总结
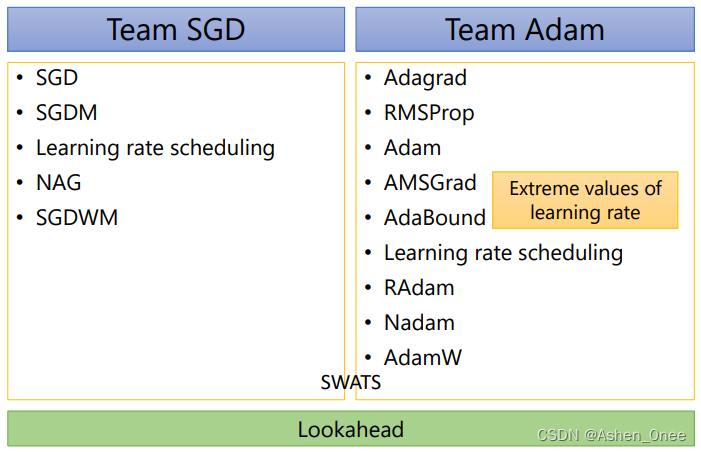
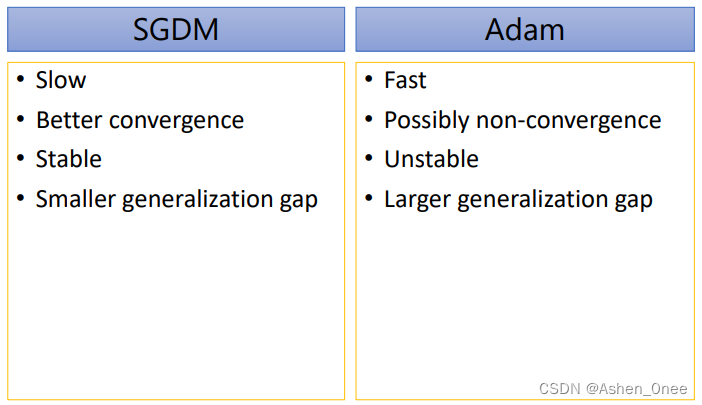
五、参考文献
Keskar, N. S., & Socher, R. (2017). Improving generalization performance by switching
from adam to sgd. arXiv. Retrieved from https://arxiv.org/abs/1712.07628
doi: 10.48550/ARXIV.1712.07628
Liu, L., Jiang, H., He, P., Chen, W., Liu, X., Gao, J., & Han, J. (2019). On
the variance of the adaptive learning rate and beyond. arXiv. Retrieved from
https://arxiv.org/abs/1908.03265 doi: 10.48550/ARXIV.19
Loshchilov, I., & Hutter, F. (2016). Sgdr: Stochastic gradient descent with warm restarts. arXiv. Retrieved from https://arxiv.org/abs/1608.03983 doi:10.48550/ARXIV.1608.03983
Luo, L., Xiong, Y., Liu, Y., & Sun, X. (2019). Adaptive gradient methods with
dynamic bound of learning rate. arXiv. Retrieved from https://arxiv.org/
abs/1902.09843 doi: 10.48550/ARXIV.1902.09843
Reddi, S. J., Kale, S., & Kumar, S. (2019). On the convergence of adam and beyond.
arXiv. Retrieved from https://arxiv.org/abs/1904.09237 doi: 10.48550/
ARXIV.1904.09237
Smith, L. N. (2015). Cyclical learning rates for training neural networks. arXiv.
Retrieved from https://arxiv.org/abs/1506.01186 doi: 10.48550/ARXIV
.1506.01186
Smith, L. N., & Topin, N. (2017). Super-convergence: Very fast training of neural
networks using large learning rates. arXiv. Retrieved from https://arxiv.org/
abs/1708.07120 doi: 10.48550/ARXIV.17















 3702
3702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









