







前言:
耗时统计:
bert等预训练模型虽然大放异彩,但是实际在落地的时候还是遇到各种问题,比如:储存空间的限制,时延的限制等等。为此有很多工作都是针对预训练模型的压缩展开的。比如最常见的就是模型蒸馏,今天想说的是另外一个思路:NAS即模型搜索,其主要思路就是不需要人为去设计特定的网络,而是让模型自己去选择,这类方法通常需要考虑的两点就是:
(1 )怎么定义候选空间。
(2 )加速训练
缺点其实很明显了,那就是耗时、资源,今天就来看一篇。
TASK-AGNOSTIC AND ADAPTIVE-SIZE BERT COM- PRESSION
所谓ADAPTIVE-SIZE就是说nas天生的优势即自己搜索,自适应。
所谓TASK-AGNOSTIC就是说其针对的是预训练模型的搜索,而不正对具体下游任务,这样学出来的模型更具有通用性。
论文将一个base模型(12层)看成是24层,即将M HA(多头)和FFN分开看,同时论文考虑了6种可选项(operation): MHA、FFN、SeqConv(三个不同size核)、Identity。同时考虑了128,192,256,384,512 五种hidden size,可以看到这里如果用排列组合来说的话,有很多种即 (1+1+3)*5 +1=26种
这里同时说一下Identity的理解,其其实是一个占位符,如果选用了Identity就代表缺少一层。
加速方法
这里说一下论文中提到的一些加速方法。为了更生动说明,这里我们就模拟一下到底怎么训练:
(1) 首先我们将24层分为4个block,然后每个块单独训练,互不影响,简单来说的话你可以今天训练一个block,明天训练另外一个。如下:
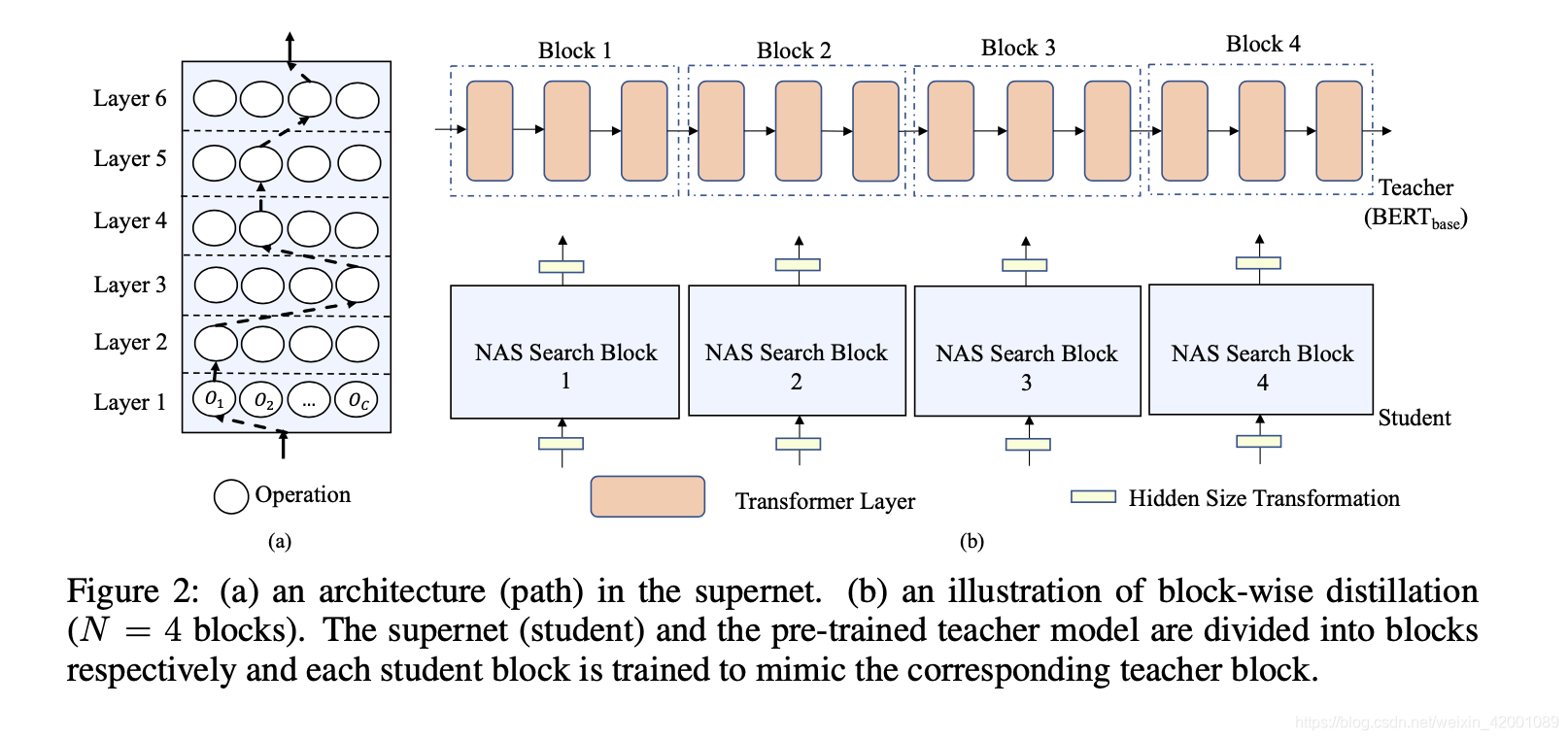
(2) 现在问题简化到怎么训练一个block,比如训练的是第N个block:
使用的蒸馏的方法,待训练student的输入是teacher对应第N-1个块的输出,拟合的输出是teacher对应第N个块的输出,loss采用的是
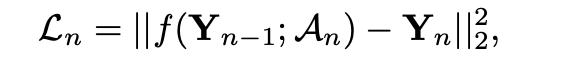
在当前块中,为了减少搜索空间, 所有层的hidden size要一样,也就是说一个块可以有不同种hidden size但是用某一种时块内的层要统一。同时比如 FFN Identity FFN Identity等效于 FFN FFN Identity Identity,所以这里面有很多冗余的,即看起来每个block有组合选择,但其实是
种组合,同时为了进一步缩减搜索空间,论文还提到使用了PROGRESSIVE SHRINKING,其实就是分桶(bins),假设在一个block中的所有组合中拥有最大参数大小的那个组合的参数大小是100M,当前分的bin数是10,那么第一个桶的参数大小范围就是0-10,第二个就是10-20,以此类推,那么就可以把所有的组合按自身参数量大小分到对应的桶中,那么在训练的时候,其实我们是从各个桶中抽出一部分来训练,其他的就不要了,这个相当于代表大会选举了,就是说各个阶层(参数量大小)都派出一部分模型,而不是都用,这在一定程度上也减少了搜索空间,当然了这个抽样也是根据loss的大小选出topk,而不是随机的,同理对待时延也是采用同样的策略,这样一来相当于又减少一批模型。
总的来看:通过(1)分块(2)块内 hidden size 一样(3)Identity都放后面 (4)PROGRESSIVE SHRINKING 这四个方面使搜索空间不断减少。
具体到训练当前块的方法是:一个step,就随机抽一种组合进行训练,一开始epoch不使用PROGRESSIVE SHRINKING,到后面的话,每个epoch后使用一些PROGRESSIVE SHRINKING
(3) 训练完后,假设每个bin 种剩下m个模型,每个块一共B个bin,一共N个block,那么最后我们大概会得到如下数量的组合模型
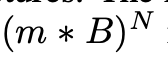
每一种组合都包含了其模型大小,时延,loss三种信息。
根据我们的具体场景要求的模型大小和时延,去对应选出一批模型,然后根据loss的大小选最好的就可以了。
选出来以后再fintune具体场景。
更多方法:
如何避免调参来自动选择神经网络结构?基于遗传算法的NAS最新进展
如何提升大规模Transformer的训练效果?Primer给出答案
论文标题:
Primer: Searching for Efficient Transformers for Language Modeling
论文链接:
https://arxiv.org/abs/2109.08668
论文代码:
https://github.com/google-research/google-research/tree/master/primer
看法
首先先不说nas效果好不好,就其出发点来看,其是自动搜索,然后是做了一个通用的,不依赖具体任务,但是这个情况的必要性是不是很大呢?大多数场景都是有一个固定任务,我们直接蒸馏就好了,是不是有必要去花费精力和这么大的资源去搞一个nas? 当然也有基于相关任务的nas方法,这个如果不是耗费太多资源还可以搞一下,但是应该来说需要的资源还是不少的,毕竟要搜索,nas 方法多出现在cv方向,NLP还有待进一步探索吧
欢迎关注笔者公众号,定期更新一些工程上的trick或者前言paper以及代码解读:


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









