







前言
在实际场景中,想有一份干净的监督数据是非常难的,而标注数据需要耗费大量的人力,是非常昂贵的,于是乎基于弱监督的方法就显得非常重要了,今天介绍一篇基于弱监督方法的文本分类模型。
论文链接:https://arxiv.org/pdf/2205.06604.pdf
方法
作者总体思路就是额外获取一个监督信号,以此来增强分类任务的进行即弱监督。
具体的作者是从预训练模型中获取监督信号,然后借助该信号进行后续的分类。
(1)Supervision Signals
作者这里借鉴prompt思想来获取当前document的一些提示词,具体的是通过给MLM构造如下prompt输入:
[CLS] + document + This article is talking about [MASK]. + [SEP]
然后我们最终从 [MASK]处获取topk个词即可。
除了上述生成的词外,作者还使用了一种更容易想到的办法,那就是直接从文章中抽取关键词,具体是使用词性标注工具去得到当前document所有词的词性,然后只选择专有名词作为结果(类比[MASK]抽取出的词大部分都是专有名词)。
作者同时使用了上述两种,可以相互弥补,具体的case如下:

从MLM获得的提示词并不一定全是对分类有增益效果的,有的词可能会带来噪声,为此最好过滤一波。一个基本思路就是当一个词越以相同频率出现在不同类别中时,那它就越是噪声,很显然其对分类没有任何用处【举个极端的例子,中文当中的助动词】。
具体的量化作者是通过如下两个公式完成的:


公式(1)是说单词w在类别ci的所有文章上出现的频率比(分母是文档中的所有词个数)
公式(2)中的分子是单词w在所有类别中对应最大的CII值,分母是第二大的CII值。
可以看到当CIR(W)的值越大,说明第一第二的差距就越大,进而说明当前w越有偏向性(就是偏向ci类)就越可以作为最终的提示词,当然了CIR公式中的分母有可能为0,这个时候其实体现了其更是容易作为提示词的,所以这个时候可以人为给CIR(W)设置一个较大值即可。
但是这里有个gap,那就是我们本来的大前提就是没有那么多的标注数据,那就自然而然无法得到未标注数据的CII值等。那怎么解决呢?作者这里使用了伪标签。
首先作者使用提示词的上下文embedding的平均来表征提示词,使用类别名的embedding来表征类别(当同一个类别有多个类别名时,最后结果也是取平均)。然后看当前提示词和所有类别的embedding的相似性中最大的那个来决定其属于哪一个类,当然了为了准确,相似性也必须大于某一个门限(这样也会导致一部分提示词用不了了,但是没办法,为了准确)
(2)Model Training
训练这里,公式较多,我们一点点来看
首先看一个总的优化目标如下:其实就是最大化提示词的log-likelihood,c就是具体的类别,wr是提示词

注意看上述推导公式的最后部分,这里有几个概率,首先是p(wr|c),它的含义是给定一个类别前提下,提示词wr出现的概率,q(c|x)其实就是我们想要的分类任务即给定documents x后属于c类的概率。
到目前为此,我们根据公式可以看到,现在就是需要解决p(wr|c)和q(c|x),这两个作者都是使用网络去学习得到的,前者paper叫做Word Distribution Learner,后者就是Document Classifier也是我们的最终目的。
先来看Word Distribution Learner,即
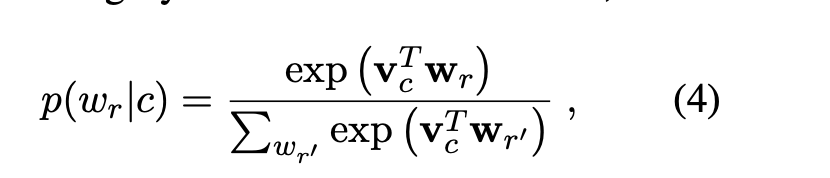
vc 就是一个可学习的向量,wr也是一个可学习的word embedding,可以看到分母是代表词表中所有词,由于词表都是很大的,所以作者对公式(4)进行了近似,具体为采用了负采样的办法:
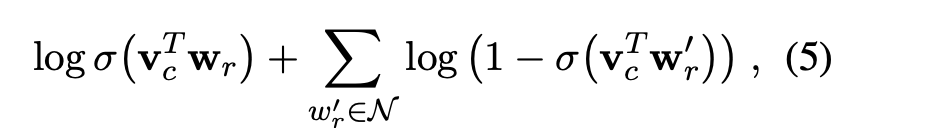
所以用了近似的公式后,总的(3)变成了

关于Document Classifier就很好理解了,什么网络都可,只要是个分类模型就行。
实验效果

解释一下,上述表格中的bert是用标注数据的fintune,是代表着弱监督效果的上限。
总结
(1)总的来说,要说trick吧,有两点可以看下,第一就是过滤提示词那里的CIR设置,可以学习一下,第二就是整天训练目标是利用了最大化提示词的log-likelihood,进而不断的推导,目的就是为了引入p,q两个概率(我们要的就是q啊),所以可以学习下即先总体有个优化目标,再不断想办法带入我们最终想要的优化目标。
(2)说实话,学术研究可以这样搞,实际工业中,折腾半天还不如多用人去标注几条数据来的更粗暴有效。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:














 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









