







生产中的RAG,为何表现不尽人如意人?
RAG(Retrieval Augmented Generation,检索增强生成)是一个将大规模语言模型(LLM)与来自外部知识源的检索相结合的框架,以改进问答能力的工程框架。虽然一切都看起来很美好,在实际应用中,RAG的状态却是“一看就会,一用就废”,总是难堪大用。今天我们就来聊聊RAG,还有那些常见的坑和生产中的困境。
RAG 补充大模型能力
在进入RAG的介绍之前,需要读者首先理解一个概念,LLM的知识更新是很困难的,主要原因在于:
- LLM的训练数据集是固定的,一旦训练完成就很难再通过继续训练来更新其知识。
- LLM的参数量巨大,随时进行fine-tuning需要消耗大量的资源,并且需要相当长的时间。
- LLM的知识是编码在数百亿个参数中的,无法直接查询或编辑其中的知识图谱。
因此,LLM的知识具有静态、封闭和有限的特点。为了赋予LLM持续学习和获取新知识的能力,RAG应运而生。
一般RAG的主要目的是:
- a) 减少LLM的幻觉回答问题
- b) 将来源/参考关联到大模型生成的回答
- c) 消除使用元数据注释文档的需要。
工作原理
RAG本质上是通过工程化手段,解决LLM知识更新困难的问题。其核心手段是利用外挂于LLM的知识数据库(通常使用向量数据库)存储未在训练数据集中出现的新数据、领域数据等。通常而言,RAG将知识问答分成三个阶段:索引、知识检索和基于内容的问答。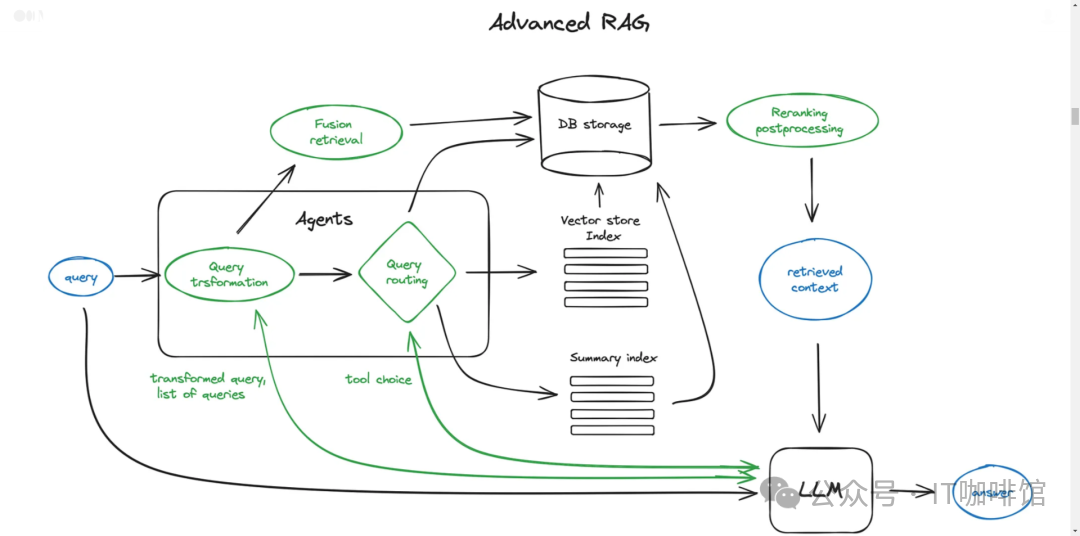 第一阶段是知识索引,需要事先将文本数据进行处理,通过词嵌入等向量化技术,将文本映射到低维向量空间,并将向量存储到数据库中,构建起可检索的向量索引。在这个阶段,RAG涉及数据加载器、分割器、向量数据库、提示工程等组件以及LLM本身。
第一阶段是知识索引,需要事先将文本数据进行处理,通过词嵌入等向量化技术,将文本映射到低维向量空间,并将向量存储到数据库中,构建起可检索的向量索引。在这个阶段,RAG涉及数据加载器、分割器、向量数据库、提示工程等组件以及LLM本身。
第二阶段是知识检索,当输入一个问题时,RAG会对知识库进行检索,找到与问题最相关的一批文档。这需要依赖于第一阶段建立的向量索引,根据向量间的相似性进行快速检索。
第三阶段是生成答案,RAG会把输入问题及相应的检索结果文档一起提供给LLM,让LLM充分把这些外部知识融入上下文,并生成相应的答案。RAG控制生成长度,避免生成无关内容。这样,LLM就能够充分利用外部知识库的信息,而不需要修改自身的参数。当知识库更新时,新知识也可以通过prompt实时注入到LLM中。这种设计既发挥了LLM强大的语言生成能力,又规避了其知识更新的困境,使之能更智能地回答各类问题,尤其是需要外部知识支持的问题。
RAG的常见坑
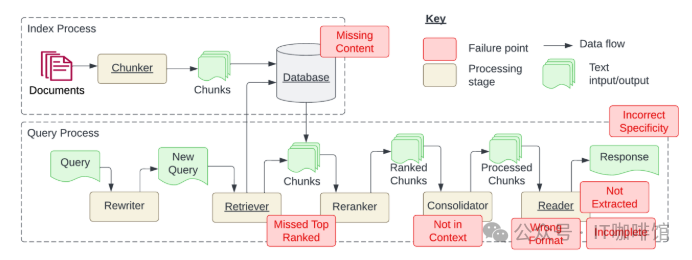
内容缺失——这是生产案例中最大的问题之一。用户假设特定问题的答案存在于知识库中。事实并非如此,系统也没有回应“我不知道”。相反,它提供了一个看似合理的错误答案,但实际是“毫无意义”。
漏掉排名靠前的文档 - 检索器是小型搜索系统,要获得正确的结果并不简单。简单的嵌入查找很少能达到目的。有时,检索器返回的前 K 个文档中不存在正确答案,从而导致失败。
不符合上下文 - 有时,RAG系统可能会检索到太多文档,并且还是强制根据上下文分割并输入文档。这意味着对问题的回答不在上下文中。有时,这会导致模型产生幻觉,除非系统提示明确指示模型不要返回不在上下文中的结果。
未提取到有用信息 - 当LLM无法从上下文中提取答案时。当你塞满上下文并且LLM会感到困惑时,这往往会成为一个问题。不同大模型对背景信息的理解能力层次不齐。
格式错误——虽然论文将这视为一种失败模式,但这种类型的功能并不是大型语言模型(LLM)的开箱即用功能。这种需要特定格式的输出,需要进行大量的系统提示和指令微调,以生成特定格式的信息。例如,使用Abacus AI,可以创建一个代理程序来以特定格式输出代码,并生成带有表格、段落、粗体文本等的Word文档。这种一般可以通过MarkDown输出来渲染!
不合适的回答 -响应中返回答案,但不够具体或过于具体,无法满足用户的需求。当 RAG 系统设计者对给定问题(例如教师对学生)有期望的结果时,就会发生这种情况。在这种情况下,应该提供具体的教育内容和答案,而不仅仅是答案。当用户不确定如何提出问题并且过于笼统时,也会出现不正确的特异性。不完整 - 不完整的答案是准确的,但缺少一些信息,即使这些信息存在于上下文中并且可用于提取。
为啥生产中会失败
1. 系统太复杂
把RAG从实验室搬到生产线,就像是把一辆赛车从赛道开到市区。赛车在赛道上跑得飞快,但在市区里就得考虑交通规则、红绿灯,还有各种突发情况。RAG也是这样,它需要处理各种不可预测的负载,保证在高需求下也能稳定运行。

2. 用户互动难以预测
用户会怎么和RAG互动,这事儿可不好说。这就要求RAG得有持续的监控和适应能力,才能保持性能和可靠性。
然而,这种预测用户需求的能力对RAG来说是一个巨大的挑战。用户可能来自不同的背景,有着不同的知识水平和期望,这就要求RAG不仅要有广泛的知识储备,还要具备一定的推理和判断能力。此外,用户的行为模式也可能随时间而变化,RAG系统必须能够适应这些变化,不断学习和优化,以保持其性能和可靠性。

改进思路
由于上诉缺点的存在,直接使用LangChain等框架实现的RAG框架几乎无法直接在生产中使用,需要进行大量的工程化优化,总得来说,至少包括如下内容:
- 检查和清洗输入数据质量。
- 调优块大小、top k检索和重叠度。
- 利用文档元数据进行更好的过滤。
- 优化prompt以提供有用的说明。

总结
RAG虽然听起来很牛,但要让它在生产环境里稳定运行,还真不是一件容易的事。目前看来它确实有多实际的应用价值,相关的技术也在不断的演进,包括RAG从1.0向2.0的演进,也是在通过探索,不断地去完善这项技术的弱点。
相关资料
- https://arxiv.org/pdf/2401.05856
- https://www.rungalileo.io/blog/mastering-rag-how-to-architect-an-enterprise-rag-system#prompting-techniques-for-improving-rag
- https://medium.com/towards-data-science/how-to-use-re-ranking-for-better-llm-rag-retrieval-243f89414266















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









