







 本文详细介绍了RISC-V架构中的CLINT和CLIC中断控制器,探讨了MTVEC和MCAUSE寄存器的作用,以及直接模式和向量模式的设置和初始化过程。特别强调了异常处理入口地址的对齐要求和向量模式下异常向量表的设计原则。
本文详细介绍了RISC-V架构中的CLINT和CLIC中断控制器,探讨了MTVEC和MCAUSE寄存器的作用,以及直接模式和向量模式的设置和初始化过程。特别强调了异常处理入口地址的对齐要求和向量模式下异常向量表的设计原则。
1、前言
- CLINT(Core-Local Interruptor)翻译过来是核本地中断控制器,是比较简单的中断控制器,通常和PLIC(Platform-Level Interrupt COntroller)搭配使用
- 使用CLINT涉及的MTVEC、MCAUSE寄存器,CLIC控制器也同样会使用,两个寄存器会兼容CLINT和CLIC(Core-Local Interrupt Controller )
- CLIC比CLINT的功能要强大一些,CLIC可以支持一定数目外部中断,而CLINT则不支持,需要结合PLIC来处理外部中断。简单理解:CLIC等于"CLINT+PLIC"的轻量版功能实现
- RISC-V架构的特权集手册里只对MTVEC和MCAUSE寄存器做了最基础的规定,不同款的芯片,寄存器的未定义是有差别的,需要具体分析
2、mtvec寄存器介绍
2.1、mtvec寄存器的位介绍
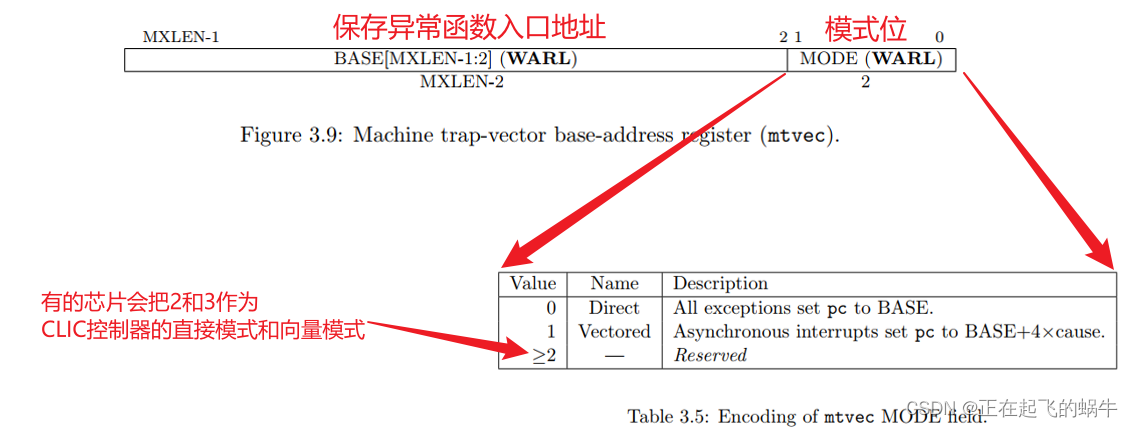
- 模式位占用两个bit,其中2和3这两个值是保留的,在有的芯片中,2和3会分别对应CLIC的直接模式和CLIC的向量模式
- 模式位不仅可以决定是直接模式还是向量模式,还可以决定使用CLINT控制器还是CLIC控制
2.2、怎么设置直接模式、间接模式
csrs mtvec,1 /* 设置成CLINT的向量模式 */
- 使用csrs指令去操作mtvec寄存器的低两位
2.3、异常处理入口函数地址的对齐要求
- RISC-V特权集手册要求异常处理入口函数的地址必须是4字节向上对齐
- 不同的芯片实现,在对齐要求上有差别,有的需要64字节对齐,有的需要256字节对齐
- 为什么至少4字节对齐?
- mtvec的低两位已经用来设置模式,但是地址是MXLEN位,如果是4字节向上对齐,则异常入口函数的地址的低两位肯定是0,这样就不用保存,所以BASE字段只有"MXLEN-2"位,要得到异常处理入口函数地址,只需要将mtvec.BASE << 2
2.4、怎么从mtvec寄存器识别出模式和异常入口函数地址
- 识别模式:直接读取出mtvec寄存器的低两位的值
- 读取出异常函数入口地址:从mtvec寄存器中读取出BASE字段,向左移两位;异常入口函数地址 = mtvec.BASE << 2,因为入口函数地址已经4字节向上对齐了,这里将低位填零的做法是没问题的
3、直接模式的初始化
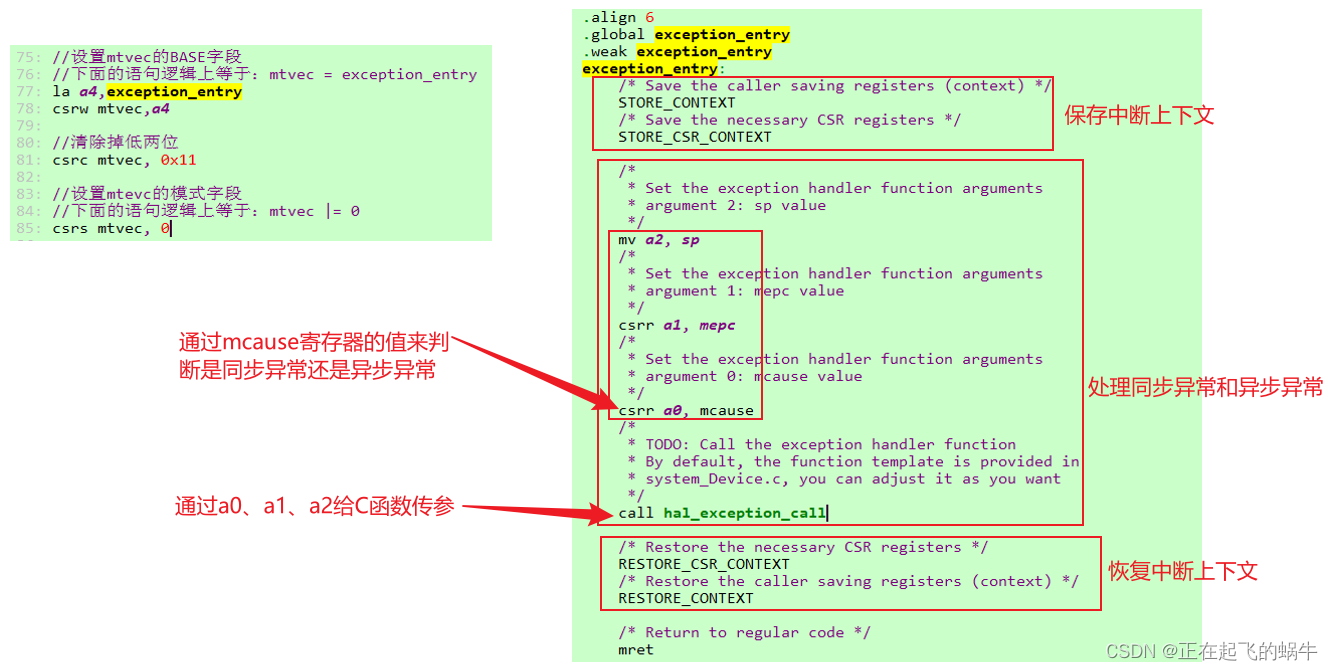
4、向量模式的初始化
4.1、异常向量表的表项
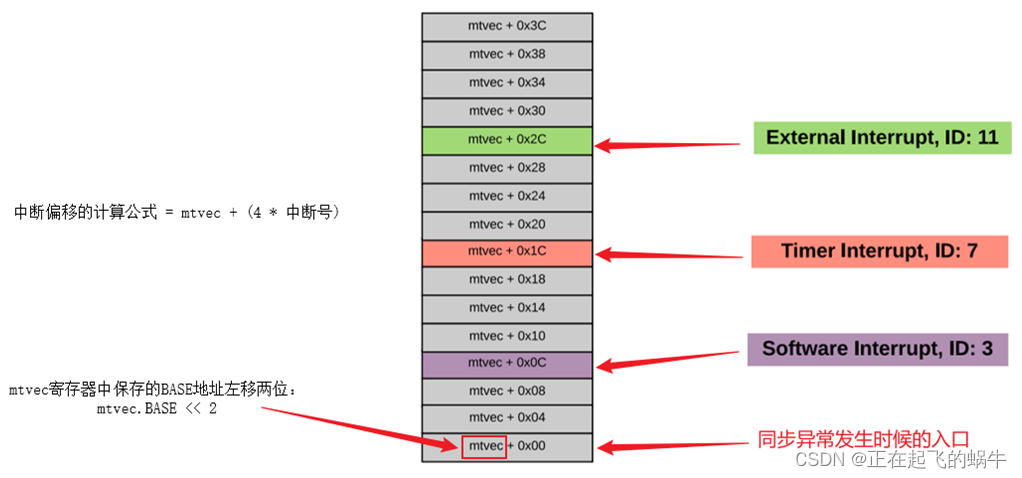
- 每个表项是4个字节,整个向量表的基地址存在mtvec.BASE字段中
- 当发生中断时,硬件将自动跳转到
mtvec.BASE + (4 * 中断号)地址处执行 - 为什么32位和64位的异常向量表都是4字节?
- 异常向量表的表项存的不是中断处理函数的地址,而是一条跳转到中断处理函数的指令,指令的长度就是4字节,和CPU架构的位数无关
- 如果异常向量表的表项存的是中断处理函数的地址,才需要区分32位和64位架构的CPU
- 零号中断和同步异常都跳转到
mtvec.BASE + 0x00处,是否有歧义?- 在芯片实现时,会避免掉这种情况,要么干脆就没有零号中断
- 在RISC-V的官方手册里有相关的说明,不是很理解文档里说的用户模式软件中断,下面是文档原文:

4.2、代码初始化向量模式

- 需要注意:每个中断号对应的处理函数必须用__attribute__((interrupt))属性修饰,目的是添加保存/恢复中断现场的代码
- 每个表项都是跳转指令,跳转的范围是当前PC值的前后1MB范围
- 可参考博客:gcc扩展选项__attribute__((interrupt))——指定中断处理函数属性-CSDN博客
5、直接模式和向量模式的比较
- 直接模式
- 优点:
- 初始化简单,只有一个入口地址
- 所有的中断和异常都共用保存/恢复中断现场的代码,编译出的bin文件会小一点(更少代码量)
- 缺点:
- 需要在异常处理函数中通过读取mcause寄存器的值来判断究竟是中断还是异常,判断逻辑要负责一点
- 对于中断的响应会慢一点,因为需要软件去区分产生了哪一个中断
- 优点:
- 向量模式
- 优点:
- 对于中断的响应速度回更快,由硬件去判断产生的中断号,并跳转到对应地址处执行(更快响应速度)
- 缺点:
- 初始化要更复杂,需要构建异常向量表,并且发生不同的中断,入口地址也不同
- 每个中断处理函数都必须用
__attribute__((interrupt))属性修饰,导致编译出来的汇编代码条数会比直接模式多
- 优点:



















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











