




在设备的故障检测中,有约30%-40%的设备故障是由轴承故障引起的,因此本文将列举有关检测轴承故障使用到的相关数据集,模型和算法。
数据集
现有的数据集,普遍由固定在电机马达上的两个震动检测器获得,并根据需要,分离震动数据在时域和频域上的特征以供网络模型学习。
不同的数据集,区别在于,检测的马达转速不同,环境不同,取样频率不同,一段样本的时长不同等等
(1)Case Western Reserve University (CWRU) Dataset
该数据集拥有多种数据,测量的时候,通过改变轴承的直径,检测的位置,马达的负载和转速,取样的频率等方式,在有限的实际设备中,生成多种有效数据。
CWRU数据集在实际使用中相当大众,是训练网络模型和检测网络性能的基本数据集。
但数据大多来源于实验室内,数据不够广泛,也不够真实。
(2)Paderborn University Dataset
该数据集在搞分辨率和高采样率的条件下,同步检测电机电流和振动信号。被检测的轴承中,26个为故障轴承,6个健康轴承。故障轴承中,12个为人为损坏,14个为加速寿命造成的更实际的损伤。人为的损坏多为人工钻孔或者人工划损;加速寿命所带来的故障数据,在使用上来说,更具真实性,它更多是因为老化而逐渐失去润滑。
它在提供振动信号的同时,也提供相对应的电流信息,促进完善着基于多物理特性的网络学习模型。
(3)PRONOSTIA Dataset
比起检测轴承故障,该数据集更多是用在检测轴承的剩余有效时间(remaining useful life--RUL)。
它主要提供了在不同条件下的,真实的加速老化轴承数据。收集数据的传感器为转子传感器和压力传感器。
在高频率收集振动数据的同时,它也在监测着轴承的温度数据,便于神经网络从多个物理特性确定轴承的RUL。
(4)Intelligent Maintenance Systems (IMS) Dataset
与普通的数据集不同,该数据集记录的不是人工造成损坏或者通过施加轴电流造成的加速老化故障,IMS数据集包含轴承缺陷演化的完整记录。yue
在一次故障出现之前,一个轴承要在2000转速情况下,连续运行30天,共约经历8千6百万次循环。
同样的,该数据集在监控震动信号的同时,也监督着轴承的温度(用来检测马达的润滑程度),适用于检测轴承的RUL。
图表总结

传统机器学习方法(ML)
与DL的自动提取特征,自动学习模式不同。传统的ML往往需要大量的专业知识和复杂的特征工程,也就是专业人员人工操作处理。先对数据集执行深入的探索性数据分析,再由PCA或者其他方法对数据进行降维处理,最后才是特征提取。其中最麻烦的还是人工的步骤,不同领域的专业知识交叉并不多,在不同的领域研究问题,往往需要多个该领域的专业人员进行手动特征提取,这导致研究成本的增大。
(1) Artificial Neural Networks (ANN)
人工神经网络基本可以算是最原始的神经网络,该网络训练的时候,以定子电流和电机转速测量作为输入(这种方法还需要一个额外的速度编码器来收集电机速度信号作为额外的输入),以预测的轴承条件作为输出。数据集也是在实验室里头,用不同的工况条件采集出来的,35个训练数据,70个测试数据。最终得出的准确率达到了 94.7% 。
(2)Principle Component Analysis (PCA)
PCA算法多用于对数据进行降维,通过计算原始数据集中的信息可用度,去除冗余信息,向用户提供这个对象的低维投影,作为网络模型的输入,这有助于缩短网络模型的训练时间和降低网络训练所需要的计算量。
实验证明,使用PCA提取出来的降维特征学习,要比用原始数据直接学习效果更好,准确率能从88%提升到98%。
(3)K-Nearest Neighbors (k-NN)
它是一种无参数的方法,常用于分类或者回归。通过数据最近的K个邻居的投票,最终决定该数据的类型。故障检测中,采用该方法来确定轴承的故障具体属于哪一个故障类。
(4)Support Vector Machines (SVM)
支持向量机是一种监督学习模型,它分析用于非概率分类或回归分析的数据。同样用于给轴承故障进行分类。
ML目前遇到的问题:
1.滑动:当前故障检测是假定滚动件和轴承滚道之间不发生滑动的基础上实现的,但在现实情况下,这种滑动并不少见
2.频率相互影响:多种故障同时发生时,会互相造成影响,从而模糊单一故障的信息频率。
3.外界的震动:在真实的环境下,除了被检测的轴承,很可能还有其他震动进行干扰,而普通ML的抗噪能力不强。
4.故障的可观察性:有些故障出现的时候,不会产生单独的震动频率,有的故障对震动频率没有明显的影响,依靠震动频率作为检测主体的ML,对于轴承故障检测不够全面。
5.灵敏度:在不同的环境条件下,各故障类型的灵敏度也不一样,在真正投入使用之前,需要收集在不同环境下,各故障类型的灵敏度。
由于ML的难以解释,准确率不稳定,抗噪健壮性不强等特点,ML没有大量投入使用,并逐渐被后来的DL所取代。
基于深度学习的方法(DL)
DL是从ML发展而来的一个机器学习的子集。DL的出现可以主要归功于以下几个因素:
1.数据爆炸:DL学习需要大量的带标签数据,新一代的传感器能收集更多,更广泛的数据,而且得益于CWRU等公开数据集的出现,使得大量带标签数据的获取变得容易,这扩展了DL的输入,促进了DL的发展。(在小数据训练和测试中,DL和ML的性能相差并不大,但随着数据量的增加,二者的准确度也会逐渐区分开来)
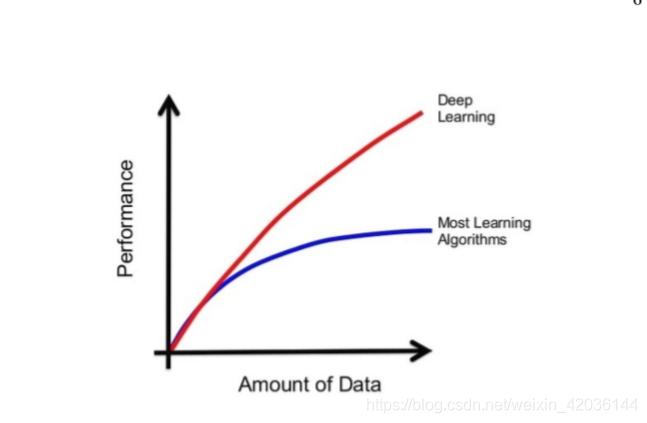
2.算法优化:对于DL模型研究加深,能够更高效地训练网络,并达到更高的准确率,实现更快的速度、更好的收敛性。例如,ReLU等算法有助于加速收敛速度;dropout和池等技术有助于防止过拟合等。
3.硬件的进化:DL学习过程需要的计算量相当庞大,也就是学习时间长,导致效率低。高性能GPU的出现,可以显著加速这一训练过程。它强大的计算能力,极大地缩减了DL模型训练的时间,提高了工作效率。(例如,NVIDIA Tesla V100张量核心gpu现在可以比传统cpu更快地解析pb级数据)
DL的出现,迅速取代了传统的,繁琐的ML,相对于ML,DL有以下几个优势:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8192
8192









 到【灌水乐园】发言
到【灌水乐园】发言







